alla maskininlärningsmodeller förklaras på 6 minuter
intuitiva förklaringar av de mest populära maskininlärningsmodellerna.

i min tidigare artikel förklarade jag vilken regression som var och visade hur den kunde användas i applikationen. Den här veckan kommer jag att gå igenom de flesta vanliga maskininlärningsmodeller som används i praktiken, så att jag kan spendera mer tid på att bygga och förbättra modeller snarare än att förklara teorin bakom den. Låt oss dyka in i det.

alla maskininlärningsmodeller kategoriseras som antingen övervakade eller oövervakade. Om modellen är en övervakad modell, är den sedan underkategoriserad som antingen en regressions-eller klassificeringsmodell. Vi går igenom vad dessa termer betyder och motsvarande modeller som faller i varje kategori nedan.
övervakat lärande innebär att man lär sig en funktion som kartlägger en ingång till en utgång baserat på exempel input-output par .
om jag till exempel hade en dataset med två variabler, ålder (input) och höjd (output), kunde jag implementera en övervakad inlärningsmodell för att förutsäga en persons höjd baserat på deras ålder.
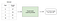
för att upprepa, inom övervakat lärande, finns det två underkategorier: regression och klassificering.
Regression
i regressionsmodeller är utgången kontinuerlig. Nedan följer några av de vanligaste typerna av regressionsmodeller.
linjär Regression

div>
tanken med linjär regression är helt enkelt att hitta en linje som bäst passar data. Förlängningar av linjär regression inkluderar multipel linjär regression (t.ex. hitta ett plan med bästa passform) och polynomregression (t.ex. hitta en kurva med bästa passform). Du kan lära dig mer om linjär regression i min tidigare artikel.
beslutsträd
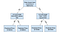
beslutsträd är en populär modell som används i operationsforskning, strategisk planering och maskininlärning. Varje kvadrat ovan kallas en nod, och ju fler noder du har, desto mer exakt kommer ditt beslutsträd att vara (i allmänhet). De sista noderna i beslutsträdet, där ett beslut fattas, kallas trädets löv. Beslutsträd är intuitiva och lätta att bygga men saknar när det gäller noggrannhet.
Random Forest
Random skogar är en ensemble inlärningsteknik som bygger bort beslutsträd. Slumpmässiga skogar innebär att man skapar flera beslutsträd med hjälp av bootstrapped dataset av originaldata och slumpmässigt väljer en delmängd av variabler vid varje steg i beslutsträdet. Modellen väljer sedan läget för alla förutsägelser för varje beslutsträd. Vad är poängen med detta? Genom att förlita sig på en” majoritetsvinst ” – modell minskar risken för fel från ett enskilt träd.

om vi till exempel skapade ett beslutsträd, det tredje, skulle det förutsäga 0. Men om vi förlitade oss på läget för alla 4 beslutsträd, skulle det förutsagda värdet vara 1. Detta är kraften i slumpmässiga skogar.
StatQuest gör ett fantastiskt jobb att gå igenom detta mer detaljerat. Se här.
neuralt nätverk

ett neuralt nätverk är i huvudsak ett nätverk av matematiska ekvationer. Det tar en eller flera ingångsvariabler, och genom att gå igenom ett nätverk av ekvationer resulterar det i en eller flera utgångsvariabler. Du kan också säga att ett neuralt nätverk tar in en vektor av ingångar och returnerar en vektor av utgångar, men jag kommer inte in i matriser i den här artikeln.
de blå cirklarna representerar ingångsskiktet, de svarta cirklarna representerar de dolda lagren och de gröna cirklarna representerar utgångsskiktet. Varje nod i de dolda lagren representerar både en linjär funktion och en aktiveringsfunktion som noderna i föregående lager går igenom, vilket i slutändan leder till en utgång i de gröna cirklarna.
- Om du vill lära dig mer om det, kolla in min nybörjarvänliga förklaring på neurala nätverk.
klassificering
i klassificeringsmodeller är utgången diskret. Nedan följer några av de vanligaste typerna av klassificeringsmodeller.
logistisk Regression
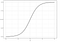
logistisk regression liknar linjär regression men används för att modellera sannolikheten för ett begränsat antal resultat, vanligtvis två. Det finns ett antal skäl till varför logistisk regression används över linjär regression när man modellerar sannolikheter för resultat (se här). I huvudsak skapas en logistisk ekvation på ett sådant sätt att utgångsvärdena endast kan vara mellan 0 och 1 (se nedan).
support vector machine
en stödvektormaskin är en övervakad klassificeringsteknik som faktiskt kan bli ganska komplicerad men är ganska intuitiv på den mest grundläggande nivån.
låt oss anta att det finns två klasser av data. En stödvektormaskin hittar en hyperplan eller en gräns mellan de två klasserna av data som maximerar marginalen mellan de två klasserna (se nedan). Det finns många plan som kan separera de två klasserna, men bara ett plan kan maximera marginalen eller avståndet mellan klasserna.

om du vill komma in i större detalj skrev Savan en bra artikel om supportvektormaskiner här.
Naive Bayes
Naive Bayes är en annan populär klassificerare som används i datavetenskap. Tanken bakom den drivs av Bayes teorem:
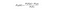
på vanlig engelska används denna ekvation för att svara på följande fråga. ”Vad är sannolikheten för y (min utgångsvariabel) givet X? Och på grund av det naiva antagandet att variabler är oberoende med tanke på klassen kan du säga det:

div genom att ta bort nämnaren kan vi också säga att p(y / X) är proportionell mot höger sida.

kolla in min artikel” en matematisk förklaring av naiva Bayes ” om du vill ha en mer djupgående förklaring!
beslutsträd, slumpmässig skog, neuralt nätverk
dessa modeller följer samma logik som tidigare förklarats. Den enda skillnaden är att den utgången är diskret snarare än kontinuerlig.
oövervakat lärande

till skillnad från övervakat lärande används oövervakat lärande för att dra slutsatser och hitta mönster från indata utan referenser till märkta resultat. Två huvudmetoder som används i oövervakat lärande inkluderar kluster och dimensioneringsreduktion.
Clustering

clustering är en oövervakad teknik som involverar gruppering eller kluster av datapunkter. Det används ofta för kundsegmentering, upptäckt av bedrägerier och dokumentklassificering.
vanliga klustringstekniker inkluderar k-means clustering, hierarkisk clustering, mean shift clustering och densitetsbaserad clustering. Medan varje teknik har en annan metod för att hitta kluster, syftar de alla till att uppnå samma sak.
Dimensionalitetsreduktion
Dimensionalitetsreduktion är processen att minska antalet slumpmässiga variabler som behandlas genom att erhålla en uppsättning huvudvariabler . I enklare termer är det processen att minska dimensionen av din funktionsuppsättning (i ännu enklare termer, vilket minskar antalet funktioner). De flesta dimensionalitetsreduceringstekniker kan kategoriseras som antingen funktionseliminering eller funktionsextraktion.
en populär metod för dimensioneringsreduktion kallas huvudkomponentanalys.
Principal Component Analysis (PCA)
i den enklaste meningen involverar PCA projekt högre dimensionella data (t.ex. 3 dimensioner) till ett mindre utrymme (t.ex. 2 dimensioner). Detta resulterar i en lägre dimension av data, (2 dimensioner istället för 3 dimensioner) samtidigt som alla ursprungliga variabler i modellen behålls.
det finns en hel del matematik involverad i detta. Om du vill lära dig mer om det …
kolla in den här fantastiska artikeln på PCA här.
Om du hellre vill titta på en video förklarar StatQuest PCA om 5 minuter här.
slutsats
Uppenbarligen finns det massor av komplexitet om du dyker in i en viss modell, men det borde ge dig en grundläggande förståelse för hur varje maskininlärningsalgoritm fungerar!
för fler artiklar som den här, kolla in https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (2010), Prentice Hall
roweis, S. T., Saul, L. K., Icke-linjär Dimensionalitetsreduktion genom lokalt linjär inbäddning (2000), vetenskap