djupinlärning för att upptäcka lunginflammation från röntgenbilder
en end-to-end-pipeline för detektering av lunginflammation från röntgenbilder
fastnat bakom betalväggen? Klicka här för att läsa hela historien med min Vänlänk!
risken för lunginflammation är enorm för många, särskilt i utvecklingsländer där miljarder möter energifattigdom och förlitar sig på förorenande energiformer. WHO uppskattar att över 4 miljoner för tidiga dödsfall inträffar årligen från hushållens luftföroreningsrelaterade sjukdomar inklusive lunginflammation. Över 150 miljoner människor smittas med lunginflammation på årsbasis, särskilt barn under 5 år. I sådana regioner kan problemet förvärras ytterligare på grund av brist på medicinska resurser och personal. Till exempel i Afrikas 57 nationer finns ett gap på 2,3 miljoner läkare och sjuksköterskor. För dessa populationer betyder korrekt och snabb diagnos allt. Det kan garantera snabb tillgång till behandling och spara välbehövlig tid och pengar för dem som redan upplever fattigdom.
detta projekt är en del av Lungröntgenbilder (lunginflammation) som hålls på Kaggle.
Bygg en algoritm för att automatiskt identifiera om en patient lider av lunginflammation eller inte genom att titta på röntgenbilder i bröstet. Algoritmen måste vara extremt exakt eftersom människors liv står på spel.
miljö och verktyg
- scikit-lär dig
- keras
- numpy
- pandas
- matplotlib
data
datauppsättningen kan laddas ner från kaggles webbplats som finns här.
var är koden?
utan mycket ado, låt oss komma igång med koden. Hela projektet på github finns här.
Låt oss börja med att ladda alla bibliotek och beroenden.
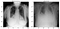
nästa jag visade några normala och lunginflammation bilder att bara ta en titt på hur mycket olika de ser ut från blotta ögat. Tja inte mycket!
sedan delade jag datauppsättningen i tre uppsättningar-tåg, validering och testuppsättningar.
nästa skrev jag en funktion där jag gjorde lite dataförstoring, matade träningen och testuppsättningen bilder till nätverket. Jag skapade också etiketter för bilderna.
övningen av dataförstoring är ett effektivt sätt att öka storleken på träningsuppsättningen. Genom att utöka träningsexemplen kan nätverket ” se ” mer diversifierade, men fortfarande representativa, datapunkter under träningen.
sedan definierade jag ett par datageneratorer: en för träningsdata och den andra för valideringsdata. En datagenerator kan ladda den önskade mängden data (ett mini — parti bilder) direkt från källmappen, konvertera dem till träningsdata (matas till modellen) och träningsmål (en vektor av attribut-övervakningssignalen).
För mina experiment ställer jag vanligtvis
batch_size = 64. I allmänhet bör ett värde mellan 32 och 128 fungera bra. Vanligtvis bör du öka / minska batchstorleken enligt beräkningsresurser och modellens prestanda.
efter det definierade jag några konstanter för senare användning.
nästa steg var att bygga modellen. Detta kan beskrivas i följande 5 steg.
- jag använde fem faltningsblock bestående av faltningsskikt, maxpooling och batch-normalisering.
- ovanpå det använde jag ett platt lager och följde det med fyra helt anslutna lager.
- även däremellan har jag använt bortfall för att minska överpassningen.
- aktiveringsfunktionen var Relu hela förutom det sista lagret där det var Sigmoid eftersom detta är ett binärt klassificeringsproblem.
- jag har använt Adam som optimerare och cross-entropi som förlusten.
före träning är modellen användbar för att definiera en eller flera återuppringningar. Ganska praktiskt en, är: ModelCheckpoint och EarlyStopping.
- ModelCheckpoint: när träning kräver mycket tid för att uppnå ett bra resultat krävs ofta många iterationer. I det här fallet är det bättre att spara en kopia av den bäst presterande modellen endast när en epok som förbättrar mätvärdena slutar.
- EarlyStopping: ibland kan vi under träning märka att generaliseringsgapet (dvs. skillnaden mellan tränings-och valideringsfel) börjar öka istället för att minska. Detta är ett symptom på överfitting som kan lösas på många sätt (minska modellkapacitet, öka träningsdata, data augumentation, regularisering, bortfall, etc). Ofta är en praktisk och effektiv lösning att sluta träna när generaliseringsgapet blir värre.

nästa tränade jag modellen för 10 epoker med en batchstorlek på 32. Observera att vanligtvis en högre batchstorlek ger bättre resultat men på bekostnad av högre beräkningsbörda. Viss forskning hävdar också att det finns en optimal batchstorlek för bästa resultat som kan hittas genom att investera lite tid på Hyper-parameter tuning.
låt oss visualisera förlust och noggrannhet tomter.

hittills så bra. Modellen konvergerar vilket kan observeras från minskningen av förlust och valideringsförlust med epoker. Det kan också nå 90% valideringsnoggrannhet på bara 10 epoker.
Låt oss plotta förvirringsmatrisen och få några av de andra resultaten också som precision, återkallelse, F1-poäng och noggrannhet.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
modellen kan uppnå en noggrannhet på 91,02% vilket är ganska bra med tanke på storleken på data som används.
slutsatser
även om detta projekt är långt ifrån komplett men det är anmärkningsvärt att se framgången med djupt lärande i så olika verkliga problem. Jag har visat hur man klassificerar positiva och negativa lunginflammationsdata från en samling röntgenbilder. Modellen gjordes från grunden, som skiljer den från andra metoder som är starkt beroende av överföringsinlärningsmetod. I framtiden kan detta arbete utvidgas för att upptäcka och klassificera röntgenbilder som består av lungcancer och lunginflammation. Att skilja röntgenbilder som innehåller lungcancer och lunginflammation har varit en stor fråga på senare tid, och vårt nästa tillvägagångssätt bör vara att ta itu med detta problem.