Hluboké Učení pro Detekci zápal Plic od X-ray Obrázky
konec konec potrubí pro zápal plic detekce od X-ray obrázky
Strčil za paywall? Klikněte sem a přečtěte si celý příběh s odkazem můj přítel!
riziko pneumonie je pro mnohé obrovské, zejména v rozvojových zemích, kde miliardy čelí energetické chudobě a spoléhají se na znečišťující formy energie. WHO odhaduje, že ročně dochází k více než 4 milionům předčasných úmrtí na choroby související se znečištěním ovzduší v domácnosti, včetně pneumonie. Více než 150 milionů lidí se každoročně nakazí pneumonií, zejména dětmi mladšími 5 let. V takových regionech může být problém dále zhoršen kvůli nedostatku lékařských zdrojů a personálu. Například v 57 zemích Afriky existuje mezera 2,3 milionu lékařů a sester. Pro tyto populace znamená přesná a rychlá diagnóza vše. Může zaručit včasný přístup k léčbě a ušetřit tolik potřebný čas a peníze těm, kteří již trpí chudobou.
tento projekt je součástí rentgenových snímků hrudníku (pneumonie) držených na Kaggle.
Vytvořte algoritmus, který automaticky identifikuje, zda pacient trpí pneumonií nebo ne, při pohledu na rentgenové snímky hrudníku. Algoritmus musel být velmi přesný, protože v sázce jsou životy lidí.
Prostředí a nástroje
- scikit-learn
- keras
- numpy
- pandy
- matplotlib
Data
datové sady lze stáhnout z kaggle webové stránky, které lze nalézt zde.
kde je Kód?
bez větších okolků začneme s kódem. Kompletní Projekt na Githubu najdete zde.
začněme načtením všech knihoven a závislostí.
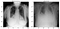
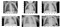
Další, zobrazí se mi nějaké normální a zápal plic snímků se jen podívat na to, jak moc se liší jejich pohled od pouhým okem. No nic moc!
Pak jsem se rozdělit data-nastavit do tří sad — vlak, validační a testovací množiny.
dále jsem napsal funkci, ve které jsem udělal některé údaje prsou, fed školení a testovací sady obrázků k síti. Také jsem vytvořil štítky pro obrázky.
praxe augmentace dat je účinným způsobem, jak zvýšit velikost tréninkové sady. Rozšíření příkladů školení umožňuje síti během tréninku“ vidět “ diverzifikovanější, ale stále reprezentativní datové body.
pak jsem definoval několik generátorů dat: jeden pro tréninková data a druhý pro validační data. Na data generator je schopen načítání požadované množství dat (mini várka obrázků) přímo ze zdrojové složky, převést je do tréninkových dat (fed modelu) a tréninkové cíle (vektor atributy — dohled signál).
pro své experimenty obvykle nastavuji
batch_size = 64. Obecně by hodnota mezi 32 a 128 měla fungovat dobře. Obvykle byste měli zvětšit / zmenšit velikost dávky podle výpočetních zdrojů a výkonů modelu.
Poté, co jsem definovanými některé konstanty pro pozdější použití.
dalším krokem bylo sestavení modelu. To lze popsat v následujících 5 krocích.
- použil jsem pět konvolučních bloků složených z konvoluční vrstvy, max-sdružování a dávkové normalizace.
- nahoře jsem použil zploštělou vrstvu a následoval ji čtyřmi plně propojenými vrstvami.
- také mezi tím jsem použil výpadky ke snížení nadměrné montáže.
- aktivační funkce byla Relu po celou dobu s výjimkou poslední vrstvy, kde byla sigmoidní, protože se jedná o binární klasifikační problém.
- Použil jsem Adam jako optimalizátor a křížovou entropii jako ztrátu.
před tréninkem je model užitečný pro definování jednoho nebo více zpětných volání. Docela šikovný, jsou: ModelCheckpoint a EarlyStopping.
- ModelCheckpoint: když trénink vyžaduje hodně času k dosažení dobrého výsledku, často je zapotřebí mnoho iterací. V tomto případě je lepší uložit kopii nejvýkonnějšího modelu pouze tehdy, když skončí epocha, která zlepšuje metriky.
- EarlyStopping: někdy, v průběhu tréninku si můžeme všimnout, že generalizace mezery (tj. rozdíl mezi tréninkem a validační chyba) začne zvyšovat, místo aby se zmenšovaly. To je příznakem overfitting, který může být řešen mnoha způsoby (snížení modelu kapacity, zvýšení tréninkových dat, data prsů, regularizace, vypuštění, atd.). Praktickým a efektivním řešením je často zastavit trénink, když se generalizační mezera zhoršuje.

dále jsem trénoval model pro 10 epoch s dávkové velikost 32. Vezměte prosím na vědomí, že obvykle vyšší velikost dávky dává lepší výsledky, ale na úkor vyšší výpočetní zátěže. Některé výzkumy také tvrdí, že existuje optimální velikost dávky pro dosažení nejlepších výsledků, které lze nalézt investováním času do ladění hyperparametrů.
Pojďme si to představit ztrátu a přesnost pozemků.

tak daleko, Tak dobrý. Model se sbližuje, což lze pozorovat z poklesu ztráty a ztráty validace s epochy. Také je schopen dosáhnout 90% validační přesnosti v pouhých 10 epochách.
pojďme plot matici zmatku a získat některé z dalších výsledků také jako přesnost, odvolání, F1 skóre a přesnost.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
model je schopen dosáhnout přesnosti 91.02%, což je docela dobré vzhledem k velikosti dat, které je použit.
závěry
ačkoli tento projekt není zdaleka úplný, ale je pozoruhodné vidět úspěch hlubokého učení v takových rozmanitých problémech reálného světa. Ukázal jsem, jak klasifikovat pozitivní a negativní údaje o pneumonii ze sbírky rentgenových snímků. Model byl vyroben od nuly, což jej odděluje od jiných metod, které se silně spoléhají na přístup k transferovému učení. V budoucnu by tato práce mohla být rozšířena o detekci a klasifikaci rentgenových snímků sestávajících z rakoviny plic a pneumonie. Rozlišování rentgenových snímků, které obsahují rakovinu plic a pneumonii, bylo v poslední době velkým problémem a naším dalším přístupem by mělo být řešení tohoto problému.