všechny modely strojového učení vysvětleny za 6 minut
intuitivní vysvětlení nejpopulárnějších modelů strojového učení.

V mém předchozím článku, Vysvětlil jsem, co regrese byl a ukázal, jak to může být použit v aplikaci. Tento týden se chystám projít většinu běžných modelů strojového učení používaných v praxi, abych mohl trávit více času vytvářením a vylepšováním modelů, než vysvětlováním teorie za tím. Pojďme se do toho ponořit.

Všechny strojového učení modely jsou klasifikovány jako buď pod dohledem nebo bez dohledu. Pokud je model kontrolovaným modelem, je pak kategorizován jako regresní nebo klasifikační model. Projdeme si, co tyto pojmy znamenají, a odpovídající modely, které spadají do každé kategorie níže.
supervizované učení zahrnuje učení funkce, která mapuje vstup na výstup na základě příkladů párů vstup-výstup .
například, pokud bych měl datový soubor se dvěma proměnnými, věk (vstup) a výšky (výstup), jsem mohl realizovat pod dohledem učení modelu předpovědět výšku osoby na základě jejich věku.
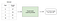
znovu opakovat, v rámci učení s učitelem, jsou tam dva sub-kategorií: regrese a klasifikace.
regrese
v regresních modelech je výstup spojitý. Níže jsou uvedeny některé z nejběžnějších typů regresních modelů.
Lineární Regrese

myšlenka lineární regrese je jednoduše najít přímku, která nejlépe odpovídá datům. Rozšíření lineární regrese zahrnují vícenásobnou lineární regresi (např. nalezení roviny nejvhodnější) a polynomiální regrese (např. nalezení křivky nejvhodnější). Více o lineární regresi se dozvíte v mém předchozím článku.
Rozhodovací Strom
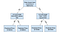
Rozhodovací stromy jsou populární model, který se používá v operační výzkum, strategické plánování a strojového učení. Každý čtverec výše se nazývá uzel a čím více uzlů máte, tím přesnější bude váš rozhodovací strom (obecně). Poslední uzly rozhodovacího stromu, kde je rozhodnuto, se nazývají listy stromu. Rozhodovací stromy jsou intuitivní a snadno se staví, ale pokud jde o přesnost, zaostávají.
náhodný Les
náhodné lesy jsou technikou učení souborů, která staví z rozhodovacích stromů. Náhodné lesy zahrnují vytvoření několika rozhodovacích stromů pomocí bootstrapped datových souborů původních dat a náhodný výběr podmnožiny proměnných v každém kroku rozhodovacího stromu. Model pak vybere režim všech předpovědí každého rozhodovacího stromu. Jaký to má smysl? Tím, že se spoléhá na model „většinové výhry“, snižuje riziko chyby z jednotlivých stromů.

například, pokud bychom vytvořili jeden rozhodovací strom, ten třetí, to by předvídat 0. Ale pokud bychom se spoléhali na režim všech 4 rozhodovacích stromů, předpokládaná hodnota by byla 1. To je síla náhodných lesů.
StatQuest dělá úžasnou práci, která prochází podrobněji. Vidět.
Neuronové Sítě

Neuronová Síť je v podstatě síť matematických rovnic. Vyžaduje jednu nebo více vstupních proměnných a procházením sítí rovnic vede k jedné nebo více výstupním proměnným. Můžete také říci, že neuronová síť přijímá vektor vstupů a vrací vektor výstupů, ale v tomto článku se nedostanu do matic.
modré kruhy představují vstupní vrstvu, černé kruhy představují skryté vrstvy a zelené kruhy představují výstupní vrstvu. Každý uzel ve skrytých vrstvách představuje jak lineární funkci, tak aktivační funkci, kterou uzly v předchozí vrstvě procházejí, což nakonec vede k výstupu v zelených kruzích.
- Pokud se o tom chcete dozvědět více, podívejte se na mé vysvětlení pro začátečníky v neuronových sítích.
klasifikace
v klasifikačních modelech je výstup diskrétní. Níže jsou uvedeny některé z nejběžnějších typů klasifikačních modelů.
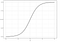
logistická regrese
logistická regrese je podobná lineární regresi, ale používá se k modelování pravděpodobnosti konečného počtu výsledků, typicky dvou. Existuje řada důvodů, proč se při modelování pravděpodobnosti výsledků používá logistická regrese oproti lineární regresi (viz zde). Logistická rovnice je v podstatě vytvořena tak,že výstupní hodnoty mohou být pouze mezi 0 a 1 (viz níže).
Support Vector Machine
Podpůrný Vektorový Stroj je pod dohledem klasifikace techniku, která může ve skutečnosti být docela složité, ale je velmi intuitivní na té nejzákladnější úrovni.
předpokládejme, že existují dvě třídy dat. Podpůrný vektorový stroj najde hyperplane nebo hranici mezi dvěma třídami dat, která maximalizuje okraj mezi oběma třídami (viz níže). Existuje mnoho rovin, které mohou oddělit dvě třídy, ale pouze jedna rovina může maximalizovat okraj nebo vzdálenost mezi třídami.

Pokud se chcete dostat do větších detailů, Savane napsal skvělý článek o tom, Support Vector Machines.
Naive Bayes
Naive Bayes je další populární klasifikátor používaný v datové vědě. Myšlenka za tím je poháněna Bayesovou větou:
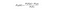
V jednoduché angličtině, tato rovnice se používá k odpovědi na následující otázku. „Jaká je pravděpodobnost y (Moje výstupní proměnná) vzhledem k X? A kvůli naivnímu předpokladu, že proměnné jsou vzhledem k třídě nezávislé, můžete říci, že:

Stejně, odstraněním jmenovatele, můžeme pak říci, že P(y|X) je úměrná pravé straně.

Proto, cílem je najít třídy y s maximální úměrná pravděpodobnosti.
podívejte se na můj článek „matematické vysvětlení naivních Bayes“ , pokud chcete podrobnější vysvětlení!
rozhodovací strom, náhodný Les, neuronová síť
tyto modely se řídí stejnou logikou, jakou bylo dříve vysvětleno. Jediný rozdíl je v tom, že tento výstup je spíše diskrétní než spojitý.
Učení bez učitele

Na rozdíl od učení s učitelem, učení bez učitele se používá, aby se vyvodit závěry a najít vzory ze vstupních dat, aniž by odkazy na označené výsledky. Dvě hlavní metody používané v učení bez dozoru zahrnují shlukování a redukci dimenzionality.
Clustering

Clustering je bez dozoru technika, která zahrnuje seskupení, nebo clusterů datových bodů. Často se používá pro segmentaci zákazníků, detekci podvodů a klasifikaci dokumentů.
mezi běžné techniky shlukování patří shlukování k-means, hierarchické shlukování, shlukování mean shift a shlukování založené na hustotě. Zatímco každá technika má jinou metodu při hledání shluků, všechny mají za cíl dosáhnout stejné věci.
redukce dimenzionality
redukce dimenzionality je proces snižování počtu uvažovaných náhodných proměnných získáním sady hlavních proměnných . Zjednodušeně řečeno, je to proces snižování dimenze vaší sady funkcí (ještě jednodušeji, snížení počtu funkcí). Většina technik redukce dimenzionality může být kategorizována jako eliminace prvků nebo extrakce prvků.
populární metoda redukce dimenzionality se nazývá analýza hlavních komponent.
Principal Component Analysis (PCA)
v nejjednodušším smyslu zahrnuje PCA projekt vyšší dimenzionální data (např. 3 rozměry) na menší prostor (např. 2 rozměry). Výsledkem je nižší rozměr dat (2 rozměry místo 3 rozměry) při zachování všech původních proměnných v modelu.
s tím souvisí poměrně dost matematiky. Pokud se o tom chcete dozvědět více…
podívejte se na tento úžasný článek o PCA zde.
Pokud byste raději sledovali video, StatQuest vysvětluje PCA za 5 minut zde.
závěr
je zřejmé, že pokud se ponoříte do konkrétního modelu, existuje spousta složitosti, ale to by vám mělo poskytnout základní pochopení toho, jak každý algoritmus strojového učení funguje!
Pro více článků jako je tento, podívejte se na https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Umělé Inteligence: Moderní Přístup (2010), Prentice Hall,
Roweis, S. T., Saule, L. K., Nelineární redukce dimenzionality Lokálně lineárním vložením (2000), věda