Zhroucení a Spectre, vysvětlil
i když tyto dny jsem většinou známý pro aplikační úrovni sítě a distribuované systémy, jsem strávil první část své kariéry, na operační systémy a hypervisory. Udržuji hlubokou fascinaci podrobnostmi nízké úrovně o tom, jak moderní procesory a systémový software fungují. Když byly oznámeny nedávné chyby zabezpečení Meltdown a Spectre, vykopal jsem dostupné informace a dychtivě jsem se dozvěděl více.
zranitelnosti jsou ohromující; Řekl bych, že jsou jedním z nejdůležitějších objevů v informatice za posledních 10-20 let. Zmírnění je také obtížné pochopit a přesné informace o nich je těžké najít. To není překvapující vzhledem k jejich kritické povaze. Zmírnění zranitelností vyžadovalo měsíce tajné práce všech hlavních dodavatelů CPU, operačního systému a cloudu. Skutečnost, že problémy byly drženy pod pokličkou 6 měsíce, kdy na nich pravděpodobně pracovaly doslova stovky lidí, je úžasná.
ačkoli od jejich oznámení bylo napsáno mnoho o Meltdown a Spectre, neviděl jsem dobrý úvod do zranitelností a zmírnění na střední úrovni. V tomto příspěvku se pokusím to napravit tím, že poskytuje jemný úvod do hardware a software zázemí potřebné k pochopení chyb, diskuse o zranitelnosti sebe, stejně jako diskuse o současné skutečnosti snižující závažnost rizika.
Důležitá poznámka: protože jsem nepracoval přímo na zmírnění a nepracuji na Intel, Microsoft, Google, Amazon, Red Hat atd. některé podrobnosti, které poskytnu, nemusí být zcela přesné. Jsem dal dohromady tento příspěvek na základě znalostí, jak tyto systémy fungují, veřejně dostupné dokumentace, a oprav/diskuse vyslán do LKML a xen-devel. Rád bych byl opraven, pokud je některý z těchto příspěvků nepřesný, i když pochybuji, že se to stane v dohledné době vzhledem k tomu, kolik z tohoto tématu je stále pokryto NDA.
v této části poskytnu nějaké pozadí potřebné k pochopení zranitelností. Sekce glosuje velké množství detailů a je zaměřena na čtenáře s omezeným porozuměním počítačového hardwaru a systémového softwaru.
Virtuální paměť
Virtuální paměť je technika, kterou používají všechny operační systémy od roku 1970. To poskytuje vrstvu abstrakce mezi paměťovou adresu layout, že většina software vidí a fyzických zařízení, zálohování, která paměť (RAM, disky, atd.). Na vysoké úrovni umožňuje aplikacím využívat více paměti, než má stroj ve skutečnosti; to poskytuje silnou abstrakci, která usnadňuje mnoho programovacích úkolů.

Obrázek 1 ukazuje zjednodušené počítač s 400 bajtů paměti stanoveny v „stránky“ 100 bajtů (skutečné počítače použití síly dva, obvykle 4096). Počítač má dva procesy, každý s 200 bajty paměti na 2 stranách. Procesy mohou být spuštěny stejným kódem pomocí pevných adres v rozsahu 0-199 bajtů, jsou však podporovány diskrétní fyzickou pamětí, takže se navzájem neovlivňují. Ačkoli moderní operační systémy a počítače používají virtuální paměť podstatně komplikovanějším způsobem, než je uvedeno v tomto příkladu, základní předpoklad uvedený výše platí ve všech případech. Operační systémy abstrahují adresy, které aplikace vidí, z fyzických zdrojů, které je podporují.
převedení virtuálních na fyzické adresy je v moderních počítačích tak běžnou operací, že pokud by se operační systém musel zapojit ve všech případech, počítač by byl neuvěřitelně pomalý. Moderní hardware CPU poskytuje zařízení zvané Translation Lookaside Buffer (TLB), které ukládá nedávno použitá mapování. To umožňuje procesorům provádět překlad adres přímo v hardwaru většinu času.
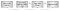
Obrázek 2 ukazuje překlad adres tok:
- program načte virtuální adresu.
- CPU se pokusí přeložit pomocí TLB. Pokud je adresa nalezena, použije se překlad.
- Pokud adresa není nalezena, CPU konzultuje sadu „tabulkových stránek“ pro určení mapování. Tabulky stránek jsou sada stránek fyzické paměti poskytovaných operačním systémem v místě, které je hardware může najít (například registr CR3 na hardwaru x86). Tabulky stránek mapují virtuální adresy na fyzické adresy a také obsahují metadata, jako jsou oprávnění.
- pokud tabulka stránek obsahuje mapování, je vrácena do mezipaměti v TLB a použita pro vyhledávání. Pokud tabulka stránek neobsahuje mapování ,je na OS vyvolána „chyba stránky“. Chyba stránky je speciální druh přerušení, který umožňuje operačnímu systému převzít kontrolu a určit, co dělat, když chybí nebo je neplatné mapování. Například OS může program ukončit. Může také přidělit nějakou fyzickou paměť a zmapovat ji do procesu. Pokud obslužná rutina poruchy stránky pokračuje v provádění, nové mapování použije TLB.

Obrázek 3 ukazuje mírně realističtější pohled na to, co virtuální paměť vypadá to, že v moderní počítačové (pre-Roztavení — více o tom níže). V tomto nastavení máme následující funkce:
- paměť jádra je zobrazena červeně. Je obsažen ve fyzickém rozsahu adres 0-99. Paměť jádra je speciální paměť, ke které by měl mít přístup pouze operační systém. Uživatelské programy by k němu neměly mít přístup.
- Uživatelská paměť je zobrazena šedě.
- nepřidělená fyzická paměť je zobrazena modře.
v tomto příkladu začneme vidět některé užitečné funkce virtuální paměti. Především:
- Uživatelská paměť je v každém procesu ve virtuálním rozsahu 0-99, ale podpořena jinou fyzickou pamětí.
- paměť jádra v každém procesu je ve virtuálním rozsahu 100-199, ale je podpořena stejnou fyzickou pamětí.
jak jsem stručně zmínil v předchozí části, každá stránka má přidružené bity oprávnění. I když je paměť jádra mapována do každého uživatelského procesu, když je proces spuštěn v uživatelském režimu, nemůže přistupovat k paměti jádra. Pokud se o to proces pokusí, spustí chybu stránky, kdy ji operační systém ukončí. Pokud je však proces spuštěn v režimu jádra (například během systémového volání), procesor povolí přístup.
V tomto bodě budu na vědomí, že tento typ dual mapování (každý proces má jádro mapovány na to přímo) byl standardní postup v operačním systému design pro více než třicet let z důvodů výkonu (systémová volání jsou velmi časté, a to bude trvat dlouhou dobu, aby přemapovat kernelu nebo v uživatelském prostoru na každém přechodu).
CPU cache topologie

další základní informace potřebné k pochopení zranitelností je topologie CPU a mezipaměti moderních procesorů. Obrázek 4 ukazuje obecnou topologii, která je společná pro většinu moderních procesorů. Skládá se z následujících komponent:
- základní jednotkou provádění je „vlákno CPU“ nebo „hardwarové vlákno“ nebo „hyper-vlákno.“Každé vlákno CPU obsahuje sadu registrů a schopnost spouštět proud strojového kódu, podobně jako softwarové vlákno.
- vlákna CPU jsou obsažena v “ jádru CPU.“Většina moderních procesorů obsahuje dvě vlákna na jádro.
- moderní procesory obecně obsahují více úrovní vyrovnávací paměti. Úrovně mezipaměti blíže k vláknu CPU jsou menší, rychlejší a dražší. Čím dále od CPU a blíže k hlavní paměti je mezipaměť větší, pomalejší a levnější.
- typický moderní design CPU používá mezipaměť L1 / L2 na jádro. To znamená, že každé vlákno CPU na jádru využívá stejné mezipaměti.
- více jader CPU je obsaženo v “ balíčku CPU.“Moderní procesory mohou obsahovat více než 30 jader (60 vláken) nebo více v balení.
- všechna jádra CPU v balíčku obvykle sdílejí mezipaměť L3.
- CPU balíčky se vejdou do “ soketů.“Většina spotřebitelských počítačů je single socket, zatímco mnoho serverů datových center má více soketů.
Spekulativní provedení

poslední kus základní informace potřebné k pochopení zranitelnosti je moderní CPU technika známá jako „spekulativní provádění.“Obrázek 5 ukazuje obecný diagram prováděcího motoru uvnitř moderního CPU.
primárním cílem je, že moderní procesory jsou neuvěřitelně komplikované a neprovádějí pouze strojové pokyny v pořádku. Každé vlákno CPU má komplikovaný motor pipelining, který je schopen provádět pokyny mimo provoz. Důvod má co do činění s ukládáním do mezipaměti. Jak jsem diskutoval v předchozí části, každý procesor využívá více úrovní ukládání do mezipaměti. Každá chybějící mezipaměť přidává k provádění programu značné množství času zpoždění. Aby se to zmírnilo, procesory jsou schopny provádět dopředu a mimo provoz při čekání na zatížení paměti. Toto je známé jako spekulativní exekuce. Následující úryvek kódu to demonstruje.
if (x < array1_size) {
y = array2 * 256];
}
V předchozím úryvku, představte si, že array1_size není k dispozici v mezipaměti, ale adresu array1. CPU by asi (spekulovat), že x je menší než array1_size a jděte do toho a provést výpočty uvnitř if. Jakmile je array1_size načten z paměti, CPU může určit, zda správně uhodl. Pokud ano, může i nadále ušetřit spoustu času. Pokud ne, může zahodit spekulativní výpočty a začít znovu. To není o nic horší, než kdyby čekal na prvním místě.
jiný typ spekulativního provádění je známý jako nepřímá predikce větve. To je v moderních programech extrémně běžné kvůli virtuálnímu odeslání.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(zdroj předchozího úryvku je tento příspěvek)
způsob, jak v předchozím úryvku je realizován ve strojovém kódu je načíst „v-stůl“ nebo „virtuální odeslání stolu“ z paměti, že obj body a pak zavolat. Protože tato operace je tak běžné, že moderní Procesory mají různé vnitřní cache a často hádat (spekulovat), kde nepřímé pobočky bude jít a pokračovat v realizaci v tomto bodě. Opět platí, že pokud CPU hádá správně, může pokračovat v ukládání spoustu času. Pokud ne, může zahodit spekulativní výpočty a začít znovu.
chyba zabezpečení Meltdown
poté, co jsme nyní pokryli všechny základní informace, můžeme se ponořit do zranitelností.
Rogue data cache load
první zranitelnost, známá jako Meltdown, je překvapivě jednoduchá na vysvětlení a téměř triviální na zneužití. Exploit kód zhruba vypadá takto:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
vezměme si každý krok výše, popsat, co to dělá, a jak to vede k být schopni číst paměť celého počítače, z uživatelského programu.
- v prvním řádku je přiděleno „pole sondy“. Toto je paměť v našem procesu, která se používá jako boční kanál pro načtení dat z jádra. Jak se to dělá, bude brzy zřejmé.
- po přidělení se útočník ujistí, že žádná z paměti v poli sondy není uložena do mezipaměti. Existují různé způsoby, jak toho dosáhnout, z nichž nejjednodušší zahrnuje pokyny specifické pro CPU pro vymazání umístění paměti z mezipaměti.
- útočník pak pokračuje ve čtení bajtu z adresního prostoru jádra. Nezapomeňte z naší předchozí diskuse o virtuální paměti a tabulkách stránek, že všechna moderní jádra obvykle mapují celý virtuální adresní prostor jádra do uživatelského procesu. Operační systémy se spoléhají na skutečnost, že každá položka tabulky stránek má nastavení oprávnění a že programy uživatelského režimu nemají přístup k paměti jádra. Každý takový přístup bude mít za následek chybu stránky. To je skutečně to, co se nakonec stane v kroku 3.
- moderní procesory však také provádějí spekulativní provádění a budou provádět před chybnou instrukcí. Kroky 3-5 tedy mohou být provedeny v potrubí CPU před vyvoláním poruchy. V tomto kroku je bajt paměti jádra (který se pohybuje v rozmezí 0-255) vynásoben velikostí stránky systému, která je obvykle 4096.
- v tomto kroku se násobený bajt paměti jádra použije pro čtení z pole sondy na fiktivní hodnotu. Vynásobením bajtu 4096 je zabránit tomu, aby funkce CPU zvaná „prefetcher“ četla více dat, než chceme do mezipaměti.
- tímto krokem si CPU uvědomil svou chybu a vrátil se zpět ke kroku 3. Výsledky spekulovaných instrukcí jsou však stále viditelné v mezipaměti. Útočník používá funkce operačního systému, aby zachytil chybnou instrukci a pokračoval v provádění (např.
- v kroku 7 útočník iteruje a vidí, jak dlouho trvá čtení každého z 256 možných bajtů v poli sondy, které mohly být indexovány pamětí jádra. CPU načte jedno z umístění do mezipaměti a toto umístění se načte podstatně rychleji než všechna ostatní místa (která je třeba číst z hlavní paměti). Toto umístění je hodnota bajtu v paměti jádra.
Pomocí výše uvedené techniky, a skutečnost, že to je standardní praxe pro moderní operační systémy zmapovat všechny fyzické paměti do jádra virtuální adresový prostor, útočník může číst počítač je celé fyzické paměti.
Nyní byste se mohli divit: „Řekl jste, že tabulky stránek mají bity oprávnění. Jak je možné, že kód uživatelského režimu byl schopen spekulativně přistupovat k paměti jádra?“Důvodem je, že se jedná o chybu v procesorech Intel. Podle mého názoru neexistuje žádný dobrý důvod, výkon nebo jinak, aby to bylo možné. Připomeňme, že veškerý přístup k virtuální paměti musí probíhat prostřednictvím TLB. Během spekulativního provádění je snadno možné zkontrolovat, zda mapování v mezipaměti má oprávnění kompatibilní s aktuální úrovní spuštěných oprávnění. Hardware Intel to prostě nedělá. Ostatní dodavatelé procesorů provádějí kontrolu oprávnění a blokují spekulativní provádění. Pokud tedy víme, Meltdown je zranitelnost pouze Intel.
upravit: zdá se, že alespoň jeden procesor ARM je také citlivý na zhroucení, jak je uvedeno zde a zde.
Zhroucení skutečnosti snižující závažnost rizika
Roztavení, je snadné pochopit, triviální využít, a naštěstí má také relativně jednoduché zmírnění (alespoň koncepčně — vývojáři jádra nemusí souhlasit, že to je jednoduché realizovat).
Kernel stránka tabulce izolace (KPTI)
Připomeňme si, že v sekci virtuální paměť jsem popsal, že všechny moderní operační systémy použít techniku, ve kterém jádro paměť je mapována do každého uživatelského režimu proces virtuální paměti adresového prostoru. To je z důvodů výkonu i jednoduchosti. To znamená, že když program provede systémové volání, jádro je připraveno k použití bez další práce. Oprava pro Meltdown je již provádět toto duální mapování.

Obrázek 6 ukazuje techniku zvanou Jádro Stránka Tabulce Izolace (KPTI). To se v podstatě scvrkává na nemapování paměti jádra do programu, když je spuštěn v uživatelském prostoru. Pokud není k dispozici žádné mapování, spekulativní provedení již není možné a okamžitě dojde k chybě.
kromě toho, že operační systém je správce virtuální paměti (VMM) složitější, bez hardwarové podpory tato technika bude také značně zpomalit pracovní vytížení, které tvoří velké množství uživatelského režimu do režimu jádra přechody, vzhledem k tomu, že stránkovací tabulky musí být upraven na každém přechodu a TLB musí být vyprázdněna (vzhledem k tomu, že TLB se mohou držet na zastaralé mapování).
Novější Procesory x86 mají funkci známou jako ASID (address space ID) nebo PCID (proces ID kontextu), které mohou být použity, aby se tento úkol podstatně levnější (ARM a další microarchitectures měl tuto funkci pro let). PCID umožňuje, aby ID bylo přidruženo k položce TLB a poté pouze propláchnout položky TLB s tímto ID. Díky použití PCID je KPTI levnější, ale stále není zdarma.
stručně řečeno, Meltdown je velmi vážná a snadno zneužitelná zranitelnost. Naštěstí to byl relativně přímočarý klimatu, které již byly nasazeny všechny hlavní OS dodavatelů, upozorněním, že určité pracovní zátěže je pomalejší, než budoucí hardware je výslovně určen pro adresní prostor oddělení je popsáno.
zranitelnost Spectre
Spectre sdílí některé vlastnosti Meltdown a skládá se ze dvou variant. Na rozdíl od Meltdown je Spectre podstatně těžší využít, ale ovlivňuje téměř všechny moderní procesory vyrobené v posledních dvaceti letech. Spectre je v podstatě útok proti modernímu návrhu CPU a operačního systému oproti konkrétní bezpečnostní chybě.
Bounds check bypass (Spectre variant 1)
první varianta Spectre je známá jako “ bounds check bypass.“To je demonstrováno v následujícím úryvku kódu (což je stejný úryvek kódu, který jsem použil k zavedení spekulativního provádění výše).
if (x < array1_size) {
y = array2 * 256];
}
V předchozím příkladu, předpokládejme následující sled událostí:
- útočník ovládací prvky
x. -
array1_sizenení uložen v mezipaměti. -
array1je uložen v mezipaměti. - CPU dohady, že
xje menší nežarray1_size. (CPU používají různé proprietární algoritmy a heuristiky, aby určily, zda spekulovat, což je důvod, proč se podrobnosti útoku pro Spectre liší mezi dodavateli procesorů a modely.) - CPU provádí tělo příkazu if, zatímco čeká na načtení
array1_size, což ovlivňuje mezipaměť podobným způsobem jako Meltdown. - útočník pak může určit skutečnou hodnotu
array1pomocí jedné z různých metod. (Viz výzkum papír pro více informací o cache inference útoků.)
Spectre je podstatně obtížnější využít než Meltdown, protože tato chyba zabezpečení nezávisí na eskalaci oprávnění. Útočník musí přesvědčit jádro, aby spustilo kód a nesprávně spekulovalo. Útočník obvykle musí otrávit spekulační motor a oklamat ho, aby hádal nesprávně. Bylo řečeno, vědci prokázali několik exploitů proof-of-concept.
chci zopakovat, co je skutečně neuvěřitelné zjištění tohoto zneužití. Osobně to nepovažuji za chybu designu CPU, jako je Meltdown per se. Považuji to za zásadní odhalení toho, jak moderní hardware a software spolupracují. Skutečnost, že mezipaměti CPU lze nepřímo použít k získání informací o přístupových vzorcích, je již nějakou dobu známa. Skutečnost, že mezipaměti CPU lze použít jako boční kanál k výpisu paměti počítače, je ohromující, a to jak koncepčně, tak ve svých důsledcích.
Branch target injection (Spectre variant 2)
připomeňme, že nepřímé větvení je v moderních programech velmi běžné. Varianta 2 Spectre využívá nepřímou predikci větve k otrávení CPU do spekulativního provedení do paměťového umístění, které by jinak nikdy nebylo provedeno. Pokud provádění těchto pokynů může zanechat stav v mezipaměti, který lze detekovat pomocí inferenčních útoků mezipaměti, útočník pak může vypsat veškerou paměť jádra. Stejně jako Spectre varianta 1, Spectre varianta 2 je mnohem těžší využít než Meltdown, nicméně vědci prokázali funkční proof-of-concept využije varianty 2.
zmírnění spektra
zmírnění spektra je podstatně zajímavější než zmírnění Meltdownu. Ve skutečnosti, akademický Spectre paper píše, že v současné době nejsou známy žádné zmírnění. Zdá se, že v zákulisí a souběžně na akademické práce, Intel (a pravděpodobně i další CPU dodavatelů) a hlavních OS a cloud prodejci pracují zuřivě měsíce rozvíjet skutečnosti snižující závažnost rizika. V této části se budu zabývat různými zmírněními, která byla vyvinuta a nasazena. Toto je sekce, na které jsem nejvíce mlhavý, protože je neuvěřitelně obtížné získat přesné informace, takže skládám věci dohromady z různých zdrojů.
Statická analýza a oplocení (varianta 1 zmírňování)
jediná známá varianta 1 (kontroly mezí bypass) zmírnění je statická analýza kódu k určení kódu sekvence, které by mohly být útočník řízené zasahovat spekulace. Zranitelný kód sekvence mohou mít serializace instrukce, například lfence vložena který zastaví spekulativní provádění, dokud se všechny instrukce až k plotu byly provedeny. Při vkládání pokynů k plotu je třeba dbát opatrnosti, protože příliš mnoho může mít vážné dopady na výkon.
Retpoline (varianta 2 zmírňování)
první Spectre varianta 2 (branch target injekce) zmírňování byl vyvinut společností Google a je známý jako „retpoline.“Není mi jasné, zda byl vyvinut izolovaně společností Google nebo společností Google ve spolupráci s Intelem. Spekuloval bych, že byl experimentálně vyvinut společností Google a poté ověřen hardwarovými inženýry společnosti Intel, ale nejsem si jistý. Podrobnosti o přístupu „retpoline“ naleznete v příspěvku společnosti Google k tomuto tématu. Shrnu je zde (glosuji některé podrobnosti včetně underflow, které jsou obsaženy v příspěvku).
Retpoline se spoléhá na skutečnost, volání a návratu z funkce a související zásobníku manipulace jsou tak běžné v počítači programy, které Procesory jsou silně optimalizované pro jejich provedení. (Pokud nejste obeznámeni s tím, jak zásobník funguje ve vztahu k volání a návratu z funkcí tento příspěvek je dobrý primer.) Stručně řečeno, když je provedeno „volání“, je zpáteční adresa tlačena na zásobník. „ret“ zobrazí zpáteční adresu a pokračuje v provádění. Spekulativní provedení hardware bude pamatovat tlačil zpáteční adresu a spekulativně pokračovat v provádění v tomto bodě.
retpolinová konstrukce nahrazuje nepřímý skok do paměťového umístění uloženého v registru r11:
jmp *%r11
s:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
podívejme se, co předchozí kód sestavy dělá jeden krok po druhém a jak zmírňuje vstřikování cílové větve.
- v tomto kroku kód volá umístění paměti, které je známé v době kompilace, takže je pevně kódovaný offset a ne nepřímý. Tím se na zásobník umístí návratová adresa
capture_spec. - zpáteční Adresa z hovoru je přepsána skutečným cílem skoku.
- návrat se provádí na skutečný cíl.
- když CPU spekulativně provede, vrátí se do nekonečné smyčky! Nezapomeňte, že CPU bude spekulovat dopředu, dokud nebude dokončeno zatížení paměti. V tomto případě byly spekulace manipulovány tak, aby byly zachyceny do nekonečné smyčky, která nemá žádné vedlejší účinky, které jsou pozorovatelné pro útočníka. Když CPU nakonec provede skutečný návrat, přeruší spekulativní provedení, které nemělo žádný účinek.
podle mého názoru je to skutečně důmyslné zmírnění. Sláva inženýrům, kteří ji vyvinuli. Nevýhodou tohoto zmírnění je, že vyžaduje, aby byl veškerý software překompilován tak, aby nepřímé větve byly převedeny na retpolinové větve. U cloudových služeb, jako je Google, které vlastní celý zásobník, není rekompilace velkým problémem. Pro ostatní, může to být velmi velký problém nebo nemožné.
IBRS, STIBP, a IBPB (varianta 2 zmírňování)
zdá se, že současně s retpoline rozvoj, Intel (a AMD do jisté míry) pracoval zuřivě na změny hardwaru zmírnit branch target injection útoky. Tři nové hardwarové funkce jsou dodávány jako aktualizace mikrokódu CPU:
- Nepřímé Pobočky Omezeny Spekulace (IBRS)
- Jeden Závit Nepřímé Pobočky Prediktorů (STIBP)
- Nepřímé Branch Predictor Bariéru (IBPB)
pouze Omezené informace o nové microcode funkce jsou k dispozici od společnosti Intel. Byl jsem schopen zhruba poskládat, co tyto nové funkce dělají, přečtením výše uvedené dokumentace a pohledem na záplaty linuxového jádra a Xen hypervisor. Z mé analýzy, každá funkce je potenciálně použita následovně:
- IBRS propláchne mezipaměť predikce větve mezi úrovněmi oprávnění (uživatel k jádru) a zakáže predikci větve na vlákně sourozeneckého CPU. Připomeňme, že každé jádro CPU má obvykle dvě vlákna CPU. Zdá se, že na moderních procesorech je hardware predikce větví sdílen mezi vlákny. To znamená, že kód uživatelského režimu může nejen otrávit prediktor větve před zadáním kódu jádra, ale také jej může otrávit kód běžící na vlákně sourozence CPU. Povolení IBRS v režimu jádra v podstatě zabraňuje jakémukoli předchozímu spuštění v uživatelském režimu a jakémukoli spuštění na vlákně sourozeneckého CPU v ovlivnění predikce větve.
- STIBP se jeví jako podmnožina IBRS, která pouze zakáže predikci větve na vlákně sourozeneckého CPU. Pokud mohu říci, hlavním případem použití této funkce je zabránit tomu, aby vlákno sourozence CPU otrávilo prediktor větve při spuštění dvou různých procesů uživatelského režimu (nebo virtuálních strojů) na stejném jádru CPU současně. Upřímně mi teď není úplně jasné, kdy by měl být použit STIBP.
- zdá se, že IBPB propláchne mezipaměť predikce větve pro kód běžící na stejné úrovni oprávnění. To může být použit při přepínání mezi dvěma programům v uživatelském režimu nebo dva virtuální stroje, aby bylo zajištěno, že předchozí kód není v rozporu s kodexem, která se chystá spustit (i když bez STIBP domnívám se, že kód běží na sourozence CPU vlákno ještě mohla otrávit branch predictor).
od tohoto psaní se zdá, že hlavní zmírnění, která vidím implementována pro zranitelnost branch target injection, jsou retpoline i IBRS. Pravděpodobně je to nejrychlejší způsob, jak chránit jádro před programy v uživatelském režimu nebo hypervizorem před hosty virtuálních strojů. V budoucnu bych očekával, že budou nasazeny jak STIBP, tak IBPB v závislosti na úrovni paranoie různých programů uživatelského režimu, které se navzájem zasahují.
náklady Na IBRS také se zdá lišit velmi široce mezi CPU architekturách s novějšími procesory Intel Skylake jsou relativně levné ve srovnání se staršími procesory. V Lyftu jsme viděli přibližně 20% zpomalení některých těžkých pracovních zátěží systémových volání na instancích AWS C4, když byly zmírněny. Spekuloval bych, že Amazon zavedl IBRS a potenciálně také retpoline, ale nejsem si jistý. Zdá se, že Google mohl retpoline spustit pouze ve svém cloudu.
v Průběhu času, očekával bych, procesory, aby nakonec přesunout do IBRS „vždy na“ model, kde je hardware jen, že výchozí čisté branch predictor oddělení mezi CPU a správně horka státu na změny úrovně oprávnění. Jediným důvodem, proč by to dnes nebylo provedeno, jsou zjevné náklady na výkon dovybavení této funkce na již vydané mikroarchitektury prostřednictvím aktualizací mikrokódu.
závěr
je velmi vzácné, že výsledek výzkumu zásadně mění způsob, jakým jsou počítače stavěny a provozovány. Meltdown a Spectre to udělali. Tato zjištění podstatně změní návrh hardwaru a softwaru v příštích 7-10 letech (další hardwarový cyklus CPU), protože návrháři berou v úvahu novou realitu možností úniku dat prostřednictvím postranních kanálů mezipaměti.
mezitím budou mít nálezy Meltdown a Spectre a související zmírnění podstatné důsledky pro uživatele počítačů pro nadcházející roky. V blízké budoucnosti budou mít zmírnění dopad na výkon, který může být podstatný v závislosti na pracovní zátěži a konkrétním hardwaru. To může vyžadovat operativní změny u některých infrastruktur (například v Lyft jsme agresivně, pohybující se některé pracovní vytížení AWS C5 instancí vzhledem k tomu, že IBRS se zdá běžet podstatně rychleji na Skylake a nové Nitro hypervisor poskytuje přerušení přímo na hotel pomocí SR-IOV a APICv, odstranění mnoho virtuální stroj východy pro IO těžké pracovní vytížení). Uživatelé stolních počítačů nejsou imunní ani kvůli útokům prohlížeče proof-of-concept pomocí JavaScriptu, které OS a prodejci prohlížečů pracují na zmírnění. Navíc, vzhledem ke složitosti zranitelnosti, je téměř jisté, že bezpečnostní výzkumníci najdou nové exploity, které nejsou pokryty stávající skutečnosti snižující závažnost rizika, že bude muset být oprava.
i když miluju práci na Lyft a pocit, že práci, kterou děláme v microservice systémů infrastruktury prostor je některé z nejvíce působivých práce v průmyslu právě teď, události, jako to udělat, aby mi slečna pracuje na operační systémy a hypervisory. Jsem velmi žárlivý na hrdinskou práci, kterou za posledních šest měsíců odvedlo obrovské množství lidí při zkoumání a zmírňování zranitelností. Byl bych rád, kdybych byl jeho součástí!
Další čtení
- Zhroucení a Spectre akademických prací: https://spectreattack.com/
- Google Project Zero blogu: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Intel Spectre hardware skutečnosti snižující závažnost rizika: https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- Retpoline blogu: https://support.google.com/faqs/answer/7625886
- Dobré shrnutí známých informací: https://github.com/marcan/speculation-bugs/blob/master/README.md