Apprentissage profond pour détecter la pneumonie à partir d’images radiographiques
Un pipeline de bout en bout pour détecter la pneumonie à partir d’images radiographiques
Coincé derrière le paywall? Cliquez ici pour lire l’histoire complète avec le lien de mon ami!
Le risque de pneumonie est immense pour beaucoup, en particulier dans les pays en développement où des milliards de personnes sont confrontées à la pauvreté énergétique et dépendent de formes d’énergie polluantes. L’OMS estime que plus de 4 millions de décès prématurés surviennent chaque année à cause de maladies liées à la pollution atmosphérique des ménages, y compris la pneumonie. Plus de 150 millions de personnes sont infectées par la pneumonie chaque année, en particulier les enfants de moins de 5 ans. Dans ces régions, le problème peut encore s’aggraver en raison de la pénurie de ressources médicales et de personnel. Par exemple, dans les 57 pays d’Afrique, il existe un déficit de 2,3 millions de médecins et d’infirmières. Pour ces populations, un diagnostic précis et rapide signifie tout. Elle peut garantir un accès rapide au traitement et permettre à ceux qui vivent déjà la pauvreté de gagner du temps et de l’argent.
Ce projet fait partie des Images radiographiques thoraciques (Pneumonie) réalisées sur Kaggle.
Construisez un algorithme pour identifier automatiquement si un patient souffre de pneumonie ou non en regardant des images radiographiques du thorax. L’algorithme devait être extrêmement précis car des vies de personnes sont en jeu.
Environnement et outils
- scikit-learn
- keras
- numpy
- pandas
- matplotlib
Data
L’ensemble de données peut être téléchargé à partir du site Web kaggle qui se trouve ici.
Où est le code ?
Sans trop tarder, commençons par le code. Le projet complet sur github peut être trouvé ici.
Commençons par charger toutes les bibliothèques et dépendances.
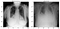
Ensuite, j’ai affiché des images normales et de pneumonie pour voir à quel point elles sont différentes à l’œil nu. Eh bien pas grand-chose!
Ensuite, je divise l’ensemble de données en trois ensembles – train, validation et ensembles de test.
Ensuite, j’ai écrit une fonction dans laquelle j’ai augmenté les données, alimenté les images de l’ensemble de formation et de test sur le réseau. J’ai également créé des étiquettes pour les images.
La pratique de l’augmentation des données est un moyen efficace d’augmenter la taille de l’ensemble d’entraînement. L’augmentation des exemples de formation permet au réseau de « voir” des points de données plus diversifiés, mais toujours représentatifs, pendant la formation.
Ensuite, j’ai défini deux générateurs de données: l’un pour les données d’entraînement et l’autre pour les données de validation. Un générateur de données est capable de charger la quantité de données requise (un mini lot d’images) directement à partir du dossier source, de les convertir en données d’entraînement (alimentées au modèle) et en cibles d’entraînement (un vecteur d’attributs — le signal de supervision).
Pour mes expériences, je règle généralement le
batch_size = 64. En général, une valeur comprise entre 32 et 128 devrait bien fonctionner. Habituellement, vous devez augmenter / diminuer la taille du lot en fonction des ressources de calcul et des performances du modèle.
Après cela, j’ai défini certaines constantes pour une utilisation ultérieure.
L’étape suivante consistait à construire le modèle. Ceci peut être décrit dans les 5 étapes suivantes.
- J’ai utilisé cinq blocs convolutifs composés d’une couche convolutive, d’une mise en commun maximale et d’une normalisation par lots.
- En plus, j’ai utilisé un calque aplati et l’ai suivi de quatre calques entièrement connectés.
- Entre les deux, j’ai également utilisé des abandons pour réduire le surajustement.
- La fonction d’activation était Relu partout sauf pour la dernière couche où elle était Sigmoïde car il s’agit d’un problème de classification binaire.
- J’ai utilisé Adam comme optimiseur et l’entropie croisée comme perte.
Avant l’entraînement, le modèle est utile pour définir un ou plusieurs rappels. Assez pratique, sont: ModelCheckpoint et EarlyStopping.
- ModelCheckpoint: lorsque l’entraînement nécessite beaucoup de temps pour obtenir un bon résultat, de nombreuses itérations sont souvent nécessaires. Dans ce cas, il est préférable d’enregistrer une copie du modèle le plus performant uniquement à la fin d’une époque qui améliore les métriques.
- EarlyStopping: parfois, pendant la formation, nous pouvons remarquer que l’écart de généralisation (c’est-à-dire la différence entre l’erreur de formation et de validation) commence à augmenter, au lieu de diminuer. Il s’agit d’un symptôme de surajustement qui peut être résolu de plusieurs manières (réduction de la capacité du modèle, augmentation des données de formation, augmentation des données, régularisation, abandon scolaire, etc.). Souvent, une solution pratique et efficace consiste à arrêter la formation lorsque l’écart de généralisation s’aggrave.

Ensuite, j’ai formé le modèle pour 10 époques avec une taille de lot de 32. Veuillez noter qu’une taille de lot plus élevée donne généralement de meilleurs résultats, mais au détriment d’une charge de calcul plus élevée. Certaines recherches affirment également qu’il existe une taille de lot optimale pour de meilleurs résultats, ce qui pourrait être trouvé en investissant du temps sur le réglage des hyperparamètres.
Visualisons les tracés de perte et de précision.

Jusqu’à présent, tout va bien. Le modèle est convergent, ce qui peut être observé à partir de la diminution de la perte et de la perte de validation avec les époques. En outre, il est capable d’atteindre une précision de validation de 90% en seulement 10 époques.
Traçons la matrice de confusion et obtenons d’autres résultats comme la précision, le rappel, le score F1 et la précision.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
Le modèle est capable d’atteindre une précision de 91,02%, ce qui est assez bon compte tenu de la taille des données utilisées.
Conclusions
Bien que ce projet soit loin d’être achevé, il est remarquable de voir le succès de l’apprentissage profond dans des problèmes réels aussi variés. J’ai démontré comment classer les données positives et négatives sur la pneumonie à partir d’une collection d’images radiographiques. Le modèle a été fabriqué à partir de zéro, ce qui le sépare des autres méthodes qui reposent fortement sur l’approche d’apprentissage par transfert. À l’avenir, ces travaux pourraient être étendus à la détection et à la classification des images radiographiques du cancer du poumon et de la pneumonie. Distinguer les images radiographiques contenant un cancer du poumon et une pneumonie a été un gros problème ces derniers temps, et notre prochaine approche devrait être de s’attaquer à ce problème.