Meltdown et Spectre, expliqués
Bien que de nos jours je sois surtout connu pour la mise en réseau au niveau des applications et les systèmes distribués, j’ai passé la première partie de ma carrière à travailler sur les systèmes d’exploitation et les hyperviseurs. Je garde une profonde fascination pour les détails de bas niveau du fonctionnement des processeurs et des logiciels de systèmes modernes. Lorsque les récentes vulnérabilités Meltdown et Spectre ont été annoncées, j’ai fouillé dans les informations disponibles et j’étais impatient d’en savoir plus.
Les vulnérabilités sont étonnantes; Je dirais qu’il s’agit de l’une des découvertes les plus importantes en informatique des 10 à 20 dernières années. Les mesures d’atténuation sont également difficiles à comprendre et il est difficile de trouver des informations précises à leur sujet. Cela n’est pas surprenant compte tenu de leur nature critique. L’atténuation des vulnérabilités a nécessité des mois de travail secret de la part de tous les principaux fournisseurs de processeurs, de systèmes d’exploitation et de cloud. Le fait que les questions aient été gardées secrètes pendant 6 mois alors que des centaines de personnes y travaillaient probablement est incroyable.
Bien que beaucoup de choses aient été écrites sur Meltdown et Spectre depuis leur annonce, je n’ai pas vu une bonne introduction de niveau intermédiaire aux vulnérabilités et aux atténuations. Dans cet article, je vais essayer de corriger cela en fournissant une introduction douce à l’arrière-plan matériel et logiciel nécessaire pour comprendre les vulnérabilités, une discussion sur les vulnérabilités elles-mêmes, ainsi qu’une discussion sur les atténuations actuelles.
Note importante: Parce que je n’ai pas travaillé directement sur les atténuations, et que je ne travaille pas chez Intel, Microsoft, Google, Amazon, Red Hat, etc. certains des détails que je vais fournir ne sont peut-être pas tout à fait exacts. J’ai rassemblé cet article en fonction de mes connaissances du fonctionnement de ces systèmes, de la documentation accessible au public et des correctifs / discussions postés sur LKML et xen-devel. J’aimerais être corrigé si l’un de ces articles est inexact, bien que je doute que cela se produise de sitôt étant donné la quantité de ce sujet qui est toujours couverte par NDA.
Dans cette section, je fournirai quelques informations nécessaires pour comprendre les vulnérabilités. La section passe sous silence une grande quantité de détails et s’adresse aux lecteurs ayant une compréhension limitée du matériel informatique et des logiciels de systèmes.
Mémoire virtuelle
La mémoire virtuelle est une technique utilisée par tous les systèmes d’exploitation depuis les années 1970.Elle fournit une couche d’abstraction entre la disposition des adresses mémoire que la plupart des logiciels voient et les périphériques physiques sauvegardant cette mémoire (RAM, disques, etc.). À un niveau élevé, il permet aux applications d’utiliser plus de mémoire que la machine n’en a réellement; cela fournit une abstraction puissante qui facilite de nombreuses tâches de programmation.

La figure 1 montre un ordinateur simpliste avec 400 octets de mémoire disposés en « pages” de 100 octets (les ordinateurs réels utilisent des puissances de deux, typiquement 4096). L’ordinateur dispose de deux processus, chacun avec 200 octets de mémoire sur 2 pages chacun. Les processus peuvent exécuter le même code en utilisant des adresses fixes dans la plage de 0 à 199 octets, mais ils sont soutenus par une mémoire physique discrète de sorte qu’ils ne s’influencent pas les uns les autres. Bien que les systèmes d’exploitation et les ordinateurs modernes utilisent la mémoire virtuelle de manière beaucoup plus compliquée que ce qui est présenté dans cet exemple, la prémisse de base présentée ci-dessus est valable dans tous les cas. Les systèmes d’exploitation extraient les adresses que l’application voit des ressources physiques qui les soutiennent.
La traduction d’adresses virtuelles en adresses physiques est une opération si courante dans les ordinateurs modernes que si le système d’exploitation devait être impliqué dans tous les cas, l’ordinateur serait incroyablement lent. Le matériel CPU moderne fournit un périphérique appelé tampon de regard de traduction (TLB) qui met en cache les mappages récemment utilisés. Cela permet aux PROCESSEURS d’effectuer une traduction d’adresse directement dans le matériel la majorité du temps.
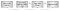
La figure 2 montre le flux de traduction d’adresses :
- Un programme récupère une adresse virtuelle.
- Le CPU tente de le traduire en utilisant le TLB. Si l’adresse est trouvée, la traduction est utilisée.
- Si l’adresse n’est pas trouvée, la CPU consulte un ensemble de ”tables de pages » pour déterminer le mappage. Les tables de pages sont un ensemble de pages de mémoire physique fournies par le système d’exploitation à un emplacement où le matériel peut les trouver (par exemple le registre CR3 sur le matériel x86). Les tables de pages mappent les adresses virtuelles aux adresses physiques et contiennent également des métadonnées telles que des autorisations.
- Si la table de pages contient un mappage, elle est renvoyée, mise en cache dans le TLB et utilisée pour la recherche. Si la table de pages ne contient pas de mappage, un « défaut de page” est déclenché sur le système d’exploitation. Un défaut de page est un type spécial d’interruption qui permet au système d’exploitation de prendre le contrôle et de déterminer quoi faire en cas de mappage manquant ou invalide. Par exemple, le système d’exploitation peut mettre fin au programme. Il peut également allouer de la mémoire physique et la mapper dans le processus. Si un gestionnaire de défaut de page continue l’exécution, le nouveau mappage sera utilisé par le TLB.

La figure 3 montre une vue légèrement plus réaliste de ce à quoi ressemble la mémoire virtuelle dans un ordinateur moderne (pré-fusion — plus à ce sujet ci-dessous). Dans cette configuration, nous avons les fonctionnalités suivantes:
- La mémoire du noyau est affichée en rouge. Il est contenu dans la plage d’adresses physiques 0-99. La mémoire du noyau est une mémoire spéciale à laquelle seul le système d’exploitation devrait pouvoir accéder. Les programmes utilisateurs ne devraient pas pouvoir y accéder.
- La mémoire utilisateur est affichée en gris.
- La mémoire physique non allouée est affichée en bleu.
Dans cet exemple, nous commençons à voir certaines des fonctionnalités utiles de la mémoire virtuelle. Principalement:
- La mémoire de l’utilisateur dans chaque processus est dans la plage virtuelle 0-99, mais soutenue par une mémoire physique différente.
- La mémoire du noyau dans chaque processus est dans la plage virtuelle 100-199, mais soutenue par la même mémoire physique.
Comme je l’ai brièvement mentionné dans la section précédente, chaque page a des bits d’autorisation associés. Même si la mémoire du noyau est mappée dans chaque processus utilisateur, lorsque le processus s’exécute en mode utilisateur, il ne peut pas accéder à la mémoire du noyau. Si un processus tente de le faire, il déclenchera un défaut de page auquel le système d’exploitation le mettra fin. Cependant, lorsque le processus s’exécute en mode noyau (par exemple lors d’un appel système), le processeur autorise l’accès.
À ce stade, je noterai que ce type de double mappage (chaque processus ayant le noyau directement mappé dedans) est une pratique courante dans la conception du système d’exploitation depuis plus de trente ans pour des raisons de performances (les appels système sont très courants et il faudrait beaucoup de temps pour remapper le noyau ou l’espace utilisateur à chaque transition).
Topologie du cache CPU

La prochaine information de base nécessaire pour comprendre les vulnérabilités est la topologie du processeur et du cache des processeurs modernes. La figure 4 montre une topologie générique commune à la plupart des PROCESSEURS modernes. Il est composé des composants suivants:
- L’unité d’exécution de base est le « thread CPU » ou « thread matériel » ou « hyper-thread. »Chaque thread CPU contient un ensemble de registres et la possibilité d’exécuter un flux de code machine, un peu comme un thread logiciel.
- Les threads CPU sont contenus dans un » noyau CPU.” La plupart des PROCESSEURS modernes contiennent deux threads par cœur.
- Les PROCESSEURS modernes contiennent généralement plusieurs niveaux de mémoire cache. Les niveaux de cache plus proches du thread CPU sont plus petits, plus rapides et plus chers. Plus le cache est éloigné du processeur et plus proche de la mémoire principale, plus il est grand, lent et moins cher.
- La conception moderne typique du processeur utilise un cache L1/L2 par cœur. Cela signifie que chaque thread CPU du cœur utilise les mêmes caches.
- Plusieurs cœurs de CPU sont contenus dans un » paquet CPU. » Les PROCESSEURS modernes peuvent contenir plus de 30 cœurs (60 threads) ou plus par paquet.
- Tous les cœurs de processeur du package partagent généralement un cache L3.
- Les paquets CPU s’insèrent dans « sockets ».”La plupart des ordinateurs grand public sont à socket unique, tandis que de nombreux serveurs de centres de données ont plusieurs sockets.
Exécution spéculative

La dernière information de base nécessaire pour comprendre les vulnérabilités est une technique CPU moderne appelée « exécution spéculative. »La figure 5 montre un diagramme générique du moteur d’exécution à l’intérieur d’un processeur moderne.
Le principal point à retenir est que les PROCESSEURS modernes sont incroyablement compliqués et n’exécutent pas simplement les instructions de la machine dans l’ordre. Chaque thread CPU dispose d’un moteur de pipelinage compliqué capable d’exécuter des instructions en panne. La raison en est liée à la mise en cache. Comme je l’ai discuté dans la section précédente, chaque CPU utilise plusieurs niveaux de mise en cache. Chaque manque de cache ajoute une quantité importante de temps de retard à l’exécution du programme. Afin d’atténuer cela, les processeurs sont capables de s’exécuter à l’avance et en panne en attendant des charges de mémoire. C’est ce qu’on appelle l’exécution spéculative. L’extrait de code suivant le démontre.
if (x < array1_size) {
y = array2 * 256];
}
Dans l’extrait précédent, imaginez que array1_size n’est pas disponible en cache, mais l’adresse de array1 l’est. Le processeur peut deviner (spéculer) que x est inférieur à array1_size et allez-y et effectuez les calculs à l’intérieur de l’instruction if. Une fois que array1_size est lu de la mémoire, le processeur peut déterminer s’il a deviné correctement. Si c’est le cas, cela peut continuer d’avoir économisé beaucoup de temps. Si ce n’est pas le cas, cela peut jeter les calculs spéculatifs et recommencer. Ce n’est pas pire que s’il avait attendu en premier lieu.
Un autre type d’exécution spéculative est connu sous le nom de prédiction de branche indirecte. Ceci est extrêmement courant dans les programmes modernes en raison de la répartition virtuelle.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(La source de l’extrait de code précédent est ce post)
La façon dont l’extrait de code précédent est implémenté dans le code machine consiste à charger la « table v” ou la « table de répartition virtuelle” à partir de l’emplacement de mémoire vers lequel obj, puis à l’appeler. Parce que cette opération est si courante, les PROCESSEURS modernes ont divers caches internes et devinent souvent (spéculent) où la branche indirecte ira et continueront l’exécution à ce stade. Encore une fois, si le processeur devine correctement, il peut continuer à gagner beaucoup de temps. Si ce n’est pas le cas, cela peut jeter les calculs spéculatifs et recommencer.
Vulnérabilité Meltdown
Après avoir couvert toutes les informations de base, nous pouvons plonger dans les vulnérabilités.
Chargement du cache de données non autorisé
La première vulnérabilité, connue sous le nom de Meltdown, est étonnamment simple à expliquer et presque triviale à exploiter. Le code d’exploit ressemble à peu près à ce qui suit:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
Prenons chaque étape ci-dessus, décrivons ce qu’il fait et comment il permet de lire la mémoire de l’ordinateur entier à partir d’un programme utilisateur.
- Dans la première ligne, un « tableau de sondes” est alloué. C’est la mémoire dans notre processus qui est utilisée comme canal latéral pour récupérer des données du noyau. La façon dont cela est fait deviendra bientôt évidente.
- Après l’allocation, l’attaquant s’assure qu’aucune mémoire du tableau de sondes n’est mise en cache. Il existe différentes façons d’y parvenir, dont la plus simple comprend des instructions spécifiques au processeur pour effacer un emplacement de mémoire du cache.
- L’attaquant procède alors à la lecture d’un octet dans l’espace d’adressage du noyau. Rappelez-vous de notre discussion précédente sur la mémoire virtuelle et les tables de pages que tous les noyaux modernes mappent généralement l’ensemble de l’espace d’adressage virtuel du noyau dans le processus utilisateur. Les systèmes d’exploitation reposent sur le fait que chaque entrée de table de pages possède des paramètres d’autorisation et que les programmes en mode utilisateur ne sont pas autorisés à accéder à la mémoire du noyau. Un tel accès entraînera un défaut de page. C’est en effet ce qui arrivera finalement à l’étape 3.
- Cependant, les processeurs modernes effectuent également une exécution spéculative et s’exécuteront avant l’instruction défaillante. Ainsi, les étapes 3 à 5 peuvent s’exécuter dans le pipeline de la CPU avant que la panne ne soit déclenchée. Dans cette étape, l’octet de la mémoire du noyau (qui va de 0 à 255) est multiplié par la taille de page du système, qui est généralement de 4096.
- Dans cette étape, l’octet multiplié de la mémoire du noyau est ensuite utilisé pour lire à partir du tableau de sondes dans une valeur fictive. La multiplication de l’octet par 4096 est d’éviter qu’une fonctionnalité CPU appelée « prefetcher” ne lise plus de données que nous ne le souhaitons dans le cache.
- À cette étape, la CPU a réalisé son erreur et est revenue à l’étape 3. Cependant, les résultats des instructions spéculées sont toujours visibles dans le cache. L’attaquant utilise les fonctionnalités du système d’exploitation pour intercepter l’instruction défaillante et poursuivre l’exécution (par exemple, gérer SIGFAULT).
- À l’étape 7, l’attaquant parcourt et voit combien de temps il faut pour lire chacun des 256 octets possibles dans le tableau de sondes qui auraient pu être indexés par la mémoire du noyau. Le PROCESSEUR aura chargé l’un des emplacements dans le cache et cet emplacement se chargera beaucoup plus rapidement que tous les autres emplacements (qui doivent être lus dans la mémoire principale). Cet emplacement est la valeur de l’octet dans la mémoire du noyau.
En utilisant la technique ci-dessus, et le fait qu’il est de pratique courante pour les systèmes d’exploitation modernes de mapper toute la mémoire physique dans l’espace d’adressage virtuel du noyau, un attaquant peut lire toute la mémoire physique de l’ordinateur.
Maintenant, vous vous demandez peut-être: « Vous avez dit que les tables de pages ont des bits d’autorisation. Comment se fait-il que le code du mode utilisateur ait pu accéder de manière spéculative à la mémoire du noyau?”La raison en est qu’il s’agit d’un bug dans les processeurs Intel. À mon avis, il n’y a aucune bonne raison, performance ou autre, pour que cela soit possible. Rappelons que tout accès à la mémoire virtuelle doit se faire via le TLB. Il est facilement possible lors d’une exécution spéculative de vérifier qu’un mappage mis en cache possède des autorisations compatibles avec le niveau de privilège en cours d’exécution. Le matériel Intel ne fait tout simplement pas cela. D’autres fournisseurs de processeurs effectuent une vérification des autorisations et bloquent l’exécution spéculative. Ainsi, pour autant que nous le sachions, Meltdown est une vulnérabilité Intel uniquement.
Edit: Il semble qu’au moins un processeur ARM soit également susceptible de fondre comme indiqué ici et ici.
Atténuations de fusion
Meltdown est facile à comprendre, trivial à exploiter, et heureusement a également une atténuation relativement simple (du moins conceptuellement — les développeurs du noyau pourraient ne pas être d’accord pour dire qu’elle est simple à implémenter).
Isolation de la table de page du noyau (KPTI)
Rappelons que dans la section sur la mémoire virtuelle, j’ai décrit que tous les systèmes d’exploitation modernes utilisent une technique dans laquelle la mémoire du noyau est mappée dans chaque espace d’adressage de mémoire virtuelle de processus de mode utilisateur. C’est à la fois pour des raisons de performance et de simplicité. Cela signifie que lorsqu’un programme effectue un appel système, le noyau est prêt à être utilisé sans autre travail. Le correctif pour Meltdown est de ne plus effectuer ce double mappage.

La figure 6 montre une technique appelée Isolation de la Table de page du noyau (KPTI). Cela se résume essentiellement à ne pas mapper la mémoire du noyau dans un programme lorsqu’il s’exécute dans l’espace utilisateur. S’il n’y a pas de mappage présent, l’exécution spéculative n’est plus possible et sera immédiatement fautive.
En plus de compliquer le gestionnaire de mémoire virtuelle (VMM) du système d’exploitation, sans assistance matérielle, cette technique ralentira considérablement les charges de travail qui font un grand nombre de transitions mode utilisateur vers mode noyau, du fait que les tables de pages doivent être modifiées à chaque transition et que la TLB doit être vidée (étant donné que la TLB peut conserver des mappages périmés).
Les PROCESSEURS x86 les plus récents ont une fonctionnalité appelée ASID (address space ID) ou PCID (process context ID) qui peut être utilisée pour rendre cette tâche nettement moins chère (ARM et d’autres microarchitectures ont cette fonctionnalité depuis des années). PCID permet à un ID d’être associé à une entrée TLB, puis de vider uniquement les entrées TLB avec cet ID. L’utilisation du PCID rend le KPTI moins cher, mais toujours pas gratuit.
En résumé, Meltdown est une vulnérabilité extrêmement grave et facile à exploiter. Heureusement, il a une atténuation relativement simple qui a déjà été déployée par tous les principaux fournisseurs de systèmes d’exploitation, la mise en garde étant que certaines charges de travail s’exécuteront plus lentement jusqu’à ce que le matériel futur soit explicitement conçu pour la séparation de l’espace d’adressage décrite.
Vulnérabilité Spectre
Spectre partage certaines propriétés de Meltdown et est composé de deux variantes. Contrairement à Meltdown, Spectre est beaucoup plus difficile à exploiter, mais affecte presque tous les processeurs modernes produits au cours des vingt dernières années. Essentiellement, Spectre est une attaque contre la conception moderne du processeur et du système d’exploitation par rapport à une vulnérabilité de sécurité spécifique.
Contournement de la vérification des limites (variante Spectre 1)
La première variante Spectre est connue sous le nom de « contournement de la vérification des limites. »Cela est démontré dans l’extrait de code suivant (qui est le même extrait de code que j’ai utilisé pour introduire l’exécution spéculative ci-dessus).
if (x < array1_size) {
y = array2 * 256];
}
Dans l’exemple précédent, supposons la séquence d’événements suivante :
- L’attaquant contrôle
x. -
array1_sizen’est pas mis en cache. -
array1est mis en cache. - Le processeur suppose que
xest inférieur àarray1_size. (Les processeurs utilisent divers algorithmes propriétaires et heuristiques pour déterminer s’il faut spéculer, c’est pourquoi les détails d’attaque de Spectre varient entre les fournisseurs de processeurs et les modèles.) - Le PROCESSEUR exécute le corps de l’instruction if pendant qu’il attend le chargement de
array1_size, affectant le cache de la même manière que Meltdown. - L’attaquant peut alors déterminer la valeur réelle de
array1via l’une des différentes méthodes. (Voir le document de recherche pour plus de détails sur les attaques par inférence de cache.)
Spectre est beaucoup plus difficile à exploiter que Meltdown car cette vulnérabilité ne dépend pas de l’escalade des privilèges. L’attaquant doit convaincre le noyau d’exécuter du code et de spéculer de manière incorrecte. En règle générale, l’attaquant doit empoisonner le moteur de spéculation et le tromper en devinant de manière incorrecte. Cela dit, les chercheurs ont montré plusieurs exploits de preuve de concept.
Je tiens à réitérer à quel point cet exploit est vraiment incroyable. Je ne considère pas personnellement cela comme un défaut de conception du processeur comme Meltdown en soi. Je considère cela comme une révélation fondamentale sur la façon dont le matériel et les logiciels modernes fonctionnent ensemble. Le fait que les caches CPU puissent être utilisés indirectement pour en savoir plus sur les modèles d’accès est connu depuis un certain temps. Le fait que les caches CPU puissent être utilisés comme canal latéral pour vider la mémoire de l’ordinateur est étonnant, à la fois conceptuellement et dans ses implications.
Injection de cible de branche (variante Spectre 2)
Rappelons que la ramification indirecte est très courante dans les programmes modernes. La variante 2 de Spectre utilise une prédiction de branche indirecte pour empoisonner le CPU en l’exécutant spéculativement dans un emplacement de mémoire qu’il n’aurait jamais exécuté autrement. Si l’exécution de ces instructions peut laisser un état dans le cache qui peut être détecté à l’aide d’attaques d’inférence de cache, l’attaquant peut alors vider toute la mémoire du noyau. Comme la variante Spectre 1, la variante Spectre 2 est beaucoup plus difficile à exploiter que Meltdown, mais les chercheurs ont démontré des exploits de preuve de concept de la variante 2.
Atténuations de Spectre
Les atténuations de Spectre sont nettement plus intéressantes que l’atténuation de Meltdown. En fait, le document académique Spectre écrit qu’il n’y a actuellement aucune atténuation connue. Il semble que dans les coulisses et parallèlement au travail académique, Intel (et probablement d’autres fournisseurs de processeurs) et les principaux fournisseurs de systèmes d’exploitation et de cloud travaillent furieusement depuis des mois pour développer des atténuations. Dans cette section, je couvrirai les différentes mesures d’atténuation qui ont été élaborées et déployées. C’est la section sur laquelle je suis le plus flou car il est incroyablement difficile d’obtenir des informations précises, donc je reconstitue des choses à partir de diverses sources.
Analyse statique et clôture (atténuation de la variante 1)
La seule atténuation connue de la variante 1 (contournement de la vérification des limites) est l’analyse statique du code pour déterminer les séquences de code qui pourraient être contrôlées par l’attaquant pour interférer avec la spéculation. Les séquences de code vulnérables peuvent avoir une instruction de sérialisation telle que lfence insérée qui arrête l’exécution spéculative jusqu’à ce que toutes les instructions jusqu’à la clôture aient été exécutées. Des précautions doivent être prises lors de l’insertion d’instructions de clôture, car un trop grand nombre peut avoir de graves impacts sur les performances.
Retpoline (atténuation de la variante 2)
La première atténuation de la variante Spectre 2 (injection de cible de branche) a été développée par Google et est connue sous le nom de « retpoline. »Je ne sais pas s’il a été développé isolément par Google ou par Google en collaboration avec Intel. Je suppose qu’il a été développé expérimentalement par Google puis vérifié par les ingénieurs matériels Intel, mais je ne suis pas sûr. Des détails sur l’approche ”retpoline » peuvent être trouvés dans l’article de Google sur le sujet. Je vais les résumer ici (je passe sous silence certains détails, y compris le sous-écoulement, qui sont couverts dans le document).
Retpoline repose sur le fait que les fonctions d’appel et de retour et les manipulations de pile associées sont si courantes dans les programmes informatiques que les PROCESSEURS sont fortement optimisés pour les exécuter. (Si vous n’êtes pas familier avec le fonctionnement de la pile en ce qui concerne l’appel et le retour de fonctions, cet article est un bon début.) En un mot, lorsqu’un ”appel » est effectué, l’adresse de retour est poussée sur la pile. « ret » désactive l’adresse de retour et poursuit l’exécution. Le matériel d’exécution spéculative se souviendra de l’adresse de retour poussée et poursuivra spéculativement l’exécution à ce stade.
La construction retpoline remplace un saut indirect vers l’emplacement mémoire stocké dans le registre r11:
jmp *%r11
avec:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
Voyons ce que le code d’assemblage précédent fait une étape à la fois et comment il atténue l’injection de cible de branche.
- Dans cette étape, le code appelle un emplacement mémoire connu au moment de la compilation, donc un décalage codé en dur et non indirect. Cela place l’adresse de retour de
capture_specsur la pile. - L’adresse de retour de l’appel est écrasée par la cible de saut réelle.
- Un retour est effectué sur la cible réelle.
- Lorsque le CPU s’exécute spéculativement, il retourne dans une boucle infinie! N’oubliez pas que le processeur spéculera à l’avance jusqu’à ce que les charges de mémoire soient terminées. Dans ce cas, la spéculation a été manipulée pour être capturée dans une boucle infinie qui n’a aucun effet secondaire observable pour un attaquant. Lorsque le PROCESSEUR exécute finalement le retour réel, il interrompt l’exécution spéculative qui n’a eu aucun effet.
À mon avis, c’est une atténuation vraiment ingénieuse. Bravo aux ingénieurs qui l’ont développé. L’inconvénient de cette atténuation est qu’elle nécessite que tous les logiciels soient recompilés de sorte que les branches indirectes soient converties en branches de retpoline. Pour les services cloud tels que Google qui possèdent la pile entière, la recompilation n’est pas une grosse affaire. Pour d’autres, cela peut être très important ou impossible.
IBRS, STIBP et IBPB (atténuation de la variante 2)
Il semble que parallèlement au développement de retpoline, Intel (et AMD dans une certaine mesure) ont travaillé furieusement sur des modifications matérielles pour atténuer les attaques par injection de cibles de branche. Les trois nouvelles fonctionnalités matérielles livrées sous forme de mises à jour de microcode CPU sont les suivantes:
- Spéculation Restreinte de Branche Indirecte (IBRS)
- Prédicteurs de Branche Indirecte à Thread Unique (STIBP)
- Barrière de Prédicteur de branche indirecte (IBPB)
Des informations limitées sur les nouvelles fonctionnalités du microcode sont disponibles sur Intel ici. J’ai pu reconstituer à peu près ce que font ces nouvelles fonctionnalités en lisant la documentation ci-dessus et en regardant les correctifs du noyau Linux et de l’hyperviseur Xen. D’après mon analyse, chaque fonctionnalité est potentiellement utilisée comme suit:
- IBRS vide le cache de prédiction de branche entre les niveaux de privilèges (utilisateur au noyau) et désactive la prédiction de branche sur le thread CPU frère. Rappelons que chaque cœur de PROCESSEUR a généralement deux threads de processeur. Il semble que sur les PROCESSEURS modernes, le matériel de prédiction de branche soit partagé entre les threads. Cela signifie que non seulement le code du mode utilisateur peut empoisonner le prédicteur de branche avant d’entrer le code du noyau, mais le code exécuté sur le thread CPU frère peut également l’empoisonner. L’activation d’IBRS en mode noyau empêche essentiellement toute exécution précédente en mode utilisateur et toute exécution sur le thread CPU frère d’affecter la prédiction de branche.
- STIBP semble être un sous-ensemble d’IBRS qui désactive simplement la prédiction de branche sur le thread CPU frère. Pour autant que je sache, le principal cas d’utilisation de cette fonctionnalité est d’empêcher un thread CPU frère d’empoisonner le prédicteur de branche lors de l’exécution de deux processus en mode utilisateur différents (ou machines virtuelles) sur le même cœur de PROCESSEUR en même temps. Honnêtement, je ne sais pas complètement quand STIBP devrait être utilisé.
- IBPB semble vider le cache de prédiction de branche pour le code s’exécutant au même niveau de privilège. Cela peut être utilisé lors de la commutation entre deux programmes en mode utilisateur ou deux machines virtuelles pour s’assurer que le code précédent n’interfère pas avec le code sur le point de s’exécuter (bien que sans STIBP, je pense que le code exécuté sur le thread CPU frère pourrait toujours empoisonner le prédicteur de branche).
Au moment d’écrire ces lignes, les principales atténuations que je vois implémentées pour la vulnérabilité d’injection de cible de branche semblent être à la fois retpoline et IBRS. C’est probablement le moyen le plus rapide de protéger le noyau des programmes en mode utilisateur ou l’hyperviseur des invités de la machine virtuelle. À l’avenir, je m’attendrais à ce que STIBP et IBPB soient déployés en fonction du niveau de paranoïa des différents programmes en mode utilisateur interférant les uns avec les autres.
Le coût des IBR semble également varier extrêmement largement entre les architectures de CPU, les nouveaux processeurs Intel Skylake étant relativement bon marché par rapport aux processeurs plus anciens. Chez Lyft, nous avons constaté un ralentissement d’environ 20 % de certaines charges de travail lourdes des appels système sur les instances AWS C4 lorsque les mesures d’atténuation ont été déployées. Je suppose qu’Amazon a déployé IBRS et potentiellement aussi retpoline, mais je ne suis pas sûr. Il semble que Google n’ait peut-être déployé que retpoline dans son nuage.
Au fil du temps, je m’attendrais à ce que les processeurs finissent par passer à un modèle IBRS « toujours activé” où le matériel ne fait que nettoyer la séparation des prédicteurs de branche entre les threads du PROCESSEUR et vide correctement l’état lors des changements de niveau de privilège. La seule raison pour laquelle cela ne serait pas fait aujourd’hui est le coût de performance apparent de la mise à niveau de cette fonctionnalité sur des microarchitectures déjà publiées via des mises à jour de microcode.
Conclusion
Il est très rare qu’un résultat de recherche modifie fondamentalement la façon dont les ordinateurs sont construits et exécutés. Meltdown et Spectre ont fait exactement cela. Ces résultats modifieront considérablement la conception du matériel et des logiciels au cours des 7 à 10 prochaines années (le prochain cycle matériel du processeur), car les concepteurs prendront en compte la nouvelle réalité des possibilités de fuite de données via des canaux latéraux du cache.
Entre-temps, les résultats de Meltdown et Spectre et les mesures d’atténuation associées auront des implications substantielles pour les utilisateurs d’ordinateurs pour les années à venir. À court terme, les mesures d’atténuation auront un impact sur les performances qui peut être important en fonction de la charge de travail et du matériel spécifique. Cela peut nécessiter des modifications opérationnelles pour certaines infrastructures (par exemple, chez Lyft, nous déplaçons agressivement certaines charges de travail vers des instances AWS C5 en raison du fait qu’IBRS semble fonctionner beaucoup plus rapidement sur les processeurs Skylake et que le nouvel hyperviseur Nitro fournit des interruptions directement aux invités utilisant SR-IOV et APICv, supprimant de nombreuses sorties de machines virtuelles pour les charges de travail lourdes d’E/S). Les utilisateurs d’ordinateurs de bureau ne sont pas non plus à l’abri, en raison des attaques de navigateur de preuve de concept utilisant JavaScript que les fournisseurs de systèmes d’exploitation et de navigateurs s’efforcent d’atténuer. De plus, en raison de la complexité des vulnérabilités, il est presque certain que les chercheurs en sécurité trouveront de nouveaux exploits non couverts par les mesures d’atténuation actuelles qui devront être corrigées.
Bien que j’adore travailler chez Lyft et que j’estime que le travail que nous faisons dans l’espace de l’infrastructure des systèmes de microservices est l’un des travaux les plus percutants de l’industrie en ce moment, des événements comme celui-ci me font manquer de travailler sur les systèmes d’exploitation et les hyperviseurs. Je suis extrêmement jaloux du travail héroïque accompli au cours des six derniers mois par un grand nombre de personnes pour rechercher et atténuer les vulnérabilités. J’aurais aimé en faire partie !
Pour en savoir plus
- Articles académiques Meltdown et Spectre: https://spectreattack.com/
- Article de blog de Google Project Zero: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Atténuations matérielles Intel Spectre: https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- Article de blog de Retpoline: https://support.google.com/faqs/answer/7625886
- Bon résumé des informations connues: https://github.com/marcan/speculation-bugs/blob/master/README.md