Tous les modèles d’Apprentissage Automatique expliqués en 6 Minutes
Explications intuitives des modèles d’apprentissage automatique les plus populaires.

Dans mon article précédent, j’ai expliqué ce qu’était la régression et montré comment elle pouvait être utilisée en application. Cette semaine, je vais passer en revue la majorité des modèles d’apprentissage automatique courants utilisés dans la pratique, afin de pouvoir passer plus de temps à construire et à améliorer des modèles plutôt qu’à expliquer la théorie qui les sous-tend. Plongeons-y.

Tous les modèles d’apprentissage automatique sont classés comme supervisés ou non supervisés. Si le modèle est un modèle supervisé, il est alors sous-catégorisé en tant que modèle de régression ou de classification. Nous examinerons ce que signifient ces termes et les modèles correspondants qui entrent dans chaque catégorie ci-dessous.
L’apprentissage supervisé implique l’apprentissage d’une fonction qui mappe une entrée à une sortie sur la base d’exemples de paires entrée-sortie.
Par exemple, si j’avais un ensemble de données avec deux variables, l’âge (entrée) et la taille (sortie), je pourrais implémenter un modèle d’apprentissage supervisé pour prédire la taille d’une personne en fonction de son âge.
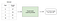
Pour ré-itérer, dans l’apprentissage supervisé, il existe deux sous-catégories: la régression et la classification.
Régression
Dans les modèles de régression, la sortie est continue. Voici quelques-uns des types de modèles de régression les plus courants.
Régression linéaire

L’idée de régression linéaire consiste simplement à trouver une ligne qui correspond le mieux aux données. Les extensions de la régression linéaire comprennent la régression linéaire multiple (p. ex. trouver un plan de meilleur ajustement) et une régression polynomiale (par exemple. trouver une courbe de meilleur ajustement). Vous pouvez en savoir plus sur la régression linéaire dans mon article précédent.
Arbre de décision
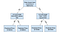
Les arbres de décision sont un modèle populaire, utilisé dans la recherche opérationnelle, la planification stratégique et l’apprentissage automatique. Chaque carré ci-dessus est appelé nœud, et plus vous avez de nœuds, plus votre arbre de décision sera précis (généralement). Les derniers nœuds de l’arbre de décision, où une décision est prise, sont appelés les feuilles de l’arbre. Les arbres de décision sont intuitifs et faciles à construire, mais manquent de précision.
Forêt aléatoire
Les forêts aléatoires sont une technique d’apprentissage d’ensemble qui se construit à partir d’arbres de décision. Les forêts aléatoires impliquent la création de plusieurs arbres de décision à l’aide d’ensembles de données amorçés des données d’origine et la sélection aléatoire d’un sous-ensemble de variables à chaque étape de l’arbre de décision. Le modèle sélectionne ensuite le mode de toutes les prédictions de chaque arbre de décision. À quoi ça sert ? En s’appuyant sur un modèle ”majority wins », il réduit le risque d’erreur d’un arbre individuel.

Par exemple, si nous créions un arbre de décision, le troisième, il prédirait 0. Mais si nous nous fiions au mode des 4 arbres de décision, la valeur prévue serait 1. C’est le pouvoir des forêts aléatoires.
StatQuest fait un travail incroyable en parcourant cela plus en détail. Voir ici.
Réseau neuronal

Un réseau de neurones est essentiellement un réseau d’équations mathématiques. Il faut une ou plusieurs variables d’entrée, et en passant par un réseau d’équations, il en résulte une ou plusieurs variables de sortie. Vous pouvez également dire qu’un réseau de neurones prend un vecteur d’entrées et renvoie un vecteur de sorties, mais je n’entrerai pas dans les matrices dans cet article.
Les cercles bleus représentent le calque d’entrée, les cercles noirs représentent les calques cachés et les cercles verts représentent le calque de sortie. Chaque nœud des couches cachées représente à la fois une fonction linéaire et une fonction d’activation que les nœuds de la couche précédente traversent, conduisant finalement à une sortie dans les cercles verts.
- Si vous souhaitez en savoir plus à ce sujet, consultez mon explication adaptée aux débutants sur les réseaux de neurones.
Classification
Dans les modèles de classification, la sortie est discrète. Voici quelques-uns des types de modèles de classification les plus courants.
Régression logistique
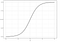
La régression logistique est similaire à la régression linéaire, mais elle est utilisée pour modéliser la probabilité d’un nombre fini de résultats, généralement deux. Il existe un certain nombre de raisons pour lesquelles la régression logistique est utilisée par rapport à la régression linéaire lors de la modélisation des probabilités de résultats (voir ici). En substance, une équation logistique est créée de telle sorte que les valeurs de sortie ne peuvent être comprises qu’entre 0 et 1 (voir ci-dessous).
Machine Vectorielle de support
Une Machine Vectorielle de Support est une technique de classification supervisée qui peut en fait devenir assez compliquée mais qui est assez intuitive au niveau le plus fondamental.
Supposons qu’il existe deux classes de données. Une machine vectorielle de support trouvera un hyperplan ou une limite entre les deux classes de données qui maximise la marge entre les deux classes (voir ci-dessous). Il existe de nombreux plans qui peuvent séparer les deux classes, mais un seul plan peut maximiser la marge ou la distance entre les classes.

Si vous voulez entrer plus en détail, Savan a écrit un excellent article sur les machines vectorielles de support ici.
Bayes naïfs
Bayes Naïfs est un autre classificateur populaire utilisé en science des données. L’idée derrière elle est motivée par le théorème de Bayes:
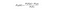
En clair, cette équation est utilisée pour répondre à la question suivante. « Quelle est la probabilité de y (ma variable de sortie) donnée X? Et en raison de l’hypothèse naïve que les variables sont indépendantes compte tenu de la classe, vous pouvez dire que:

De même, en supprimant le dénominateur, on peut alors dire que P(y/X) est proportionnel au côté droit.

Par conséquent, le but est de trouver la classe y avec la probabilité proportionnelle maximale.
Consultez mon article « Une explication mathématique des Bayes naïves » si vous voulez une explication plus approfondie!
Arbre de décision, Forêt aléatoire, Réseau neuronal
Ces modèles suivent la même logique que précédemment expliquée. La seule différence est que cette sortie est discrète plutôt que continue.
Apprentissage non supervisé

Contrairement à l’apprentissage supervisé, l’apprentissage non supervisé est utilisé pour tirer des inférences et trouver des modèles à partir des données d’entrée sans références aux résultats étiquetés. Deux méthodes principales utilisées dans l’apprentissage non supervisé comprennent le clustering et la réduction de la dimensionnalité.
Clustering

Le clustering est une technique non supervisée qui implique le regroupement, ou le clustering, de points de données. Il est fréquemment utilisé pour la segmentation des clients, la détection des fraudes et la classification des documents.
Les techniques de clustering les plus courantes comprennent le clustering à k moyennes, le clustering hiérarchique, le clustering à décalage moyen et le clustering basé sur la densité. Bien que chaque technique ait une méthode différente pour trouver des clusters, elles visent toutes à réaliser la même chose.
Réduction de dimensionnalité
La réduction de dimensionnalité est le processus de réduction du nombre de variables aléatoires considérées en obtenant un ensemble de variables principales. En termes plus simples, c’est le processus de réduction de la dimension de votre ensemble de fonctionnalités (en termes encore plus simples, en réduisant le nombre de fonctionnalités). La plupart des techniques de réduction de la dimensionnalité peuvent être classées comme élimination de caractéristiques ou extraction de caractéristiques.
Une méthode populaire de réduction de la dimensionnalité est appelée analyse en composantes principales.
Analyse en composantes principales (APC)
Au sens le plus simple, l’APC implique de projeter des données de dimensions supérieures (p. ex. 3 dimensions) à un espace plus petit (par exemple. 2 dimensions). Il en résulte une dimension inférieure des données (2 dimensions au lieu de 3 dimensions) tout en conservant toutes les variables d’origine dans le modèle.
Il y a pas mal de mathématiques impliquées dans cela. Si vous voulez en savoir plus à ce sujet
Consultez cet article génial sur PCA ici.
Si vous préférez regarder une vidéo, StatQuest explique PCA en 5 minutes ici.
Conclusion
Évidemment, il y a une tonne de complexité si vous plongez dans un modèle particulier, mais cela devrait vous donner une compréhension fondamentale du fonctionnement de chaque algorithme d’apprentissage automatique!
Pour plus d’articles comme celui-ci, consultez https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (2010), Prentice Hall
Roweis , S. T., Saul, L. K., Réduction de la Dimensionnalité Non linéaire par Incorporation Localement Linéaire (2000), Science