Egy kezdős útmutató a szórás és a standard hiba – a diákok 4 legjobb bizonyíték
feladta szeptember 26-án 2018 által Eveliina Ilola
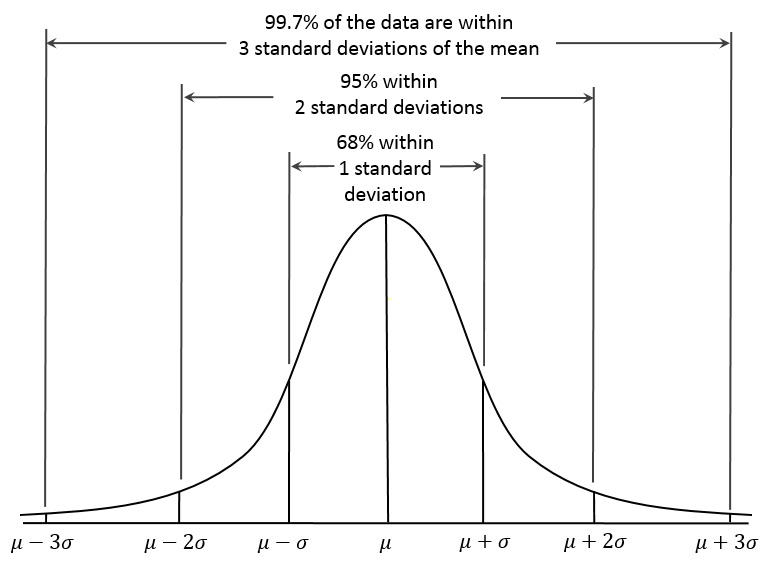
mi a szórás?
a szórás megmutatja, hogy az adatok mennyire vannak elosztva. Ez annak mértéke, hogy az egyes megfigyelt értékek milyen messze vannak az átlagtól. Bármely eloszlásban az értékek körülbelül 95% – a az átlag 2 szórásán belül lesz.
hogyan kell kiszámítani a szórást
a szórást ritkán számítják ki kézzel. Ez azonban megtehető az alábbi képlet segítségével, ahol x egy adathalmaz értékét képviseli, az adathalmaz átlagát, az N pedig az adathalmaz értékeinek számát jelenti.
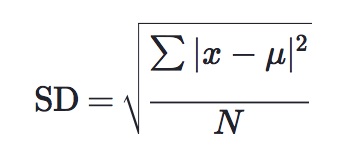
a szórás kiszámításának lépései a következők:
- minden értéknél keresse meg a távolságot az átlaghoz
- minden értéknél keresse meg ennek a távolságnak a négyzetét
- keresse meg ezeknek a négyzetértékeknek az összegét
- ossza el az összeget az adatkészlet értékeinek számával
- keresse meg ennek négyzetgyökét
mi a standard hiba?
amikor kutatást végez, gyakran csak a teljes populáció kis mintájának adatait gyűjti össze. Emiatt valószínűleg minden alkalommal kissé eltérő értékkészletekkel jár, kissé eltérő eszközökkel.
ha elegendő mintát vesz egy populációból, az eszközök eloszlásba kerülnek a valódi populációs átlag körül. Ennek az eloszlásnak a szórását, azaz a minta átlagának szórását standard hibának nevezzük.
a standard hiba megmutatja, hogy az adott populációból származó minta átlaga mennyire pontos a valós populációs átlaghoz képest. Amikor a standard hiba növekszik, vagyis az eszközök jobban eloszlanak, valószínűbbé válik, hogy bármely adott átlag pontatlan ábrázolása a valós populációs átlagnak.
A standard hiba kiszámítása
a Standard hiba az alábbi képlet segítségével számítható ki, ahol a ++ a szórást, az n pedig a minta méretét jelenti.
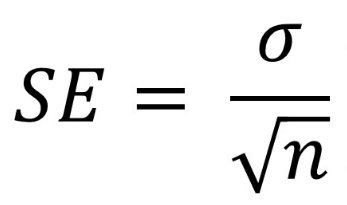
a Standard hiba növekszik, amikor a szórás, azaz a populáció varianciája növekszik. A Standard hiba csökken, amikor a minta mérete növekszik – ahogy a minta mérete közelebb kerül a populáció valódi méretéhez, a minta egyre inkább klasztert jelent a valódi populáció átlaga körül.
képek:
1. kép: Dan Kernler a Wikipedia Commons segítségével: https://commons.wikimedia.org/wiki/File:Empirical_Rule.PNGÂ
Image 2: https://www.khanacademy.org/math/probability/data-distributions-a1/summarizing-spread-distributions/a/calculating-standard-deviation-step-by-step
Image 3: https://toptipbio.com/standard-error-formula/