minden gépi tanulási modell magyarázata 6 perc alatt
A legnépszerűbb gépi tanulási modellek intuitív magyarázata.

előző cikkemben elmagyaráztam, mi a regresszió, és megmutattam, hogyan lehet használni az alkalmazásban. Ezen a héten áttekintem a gyakorlatban használt általános gépi tanulási modellek többségét, hogy több időt tölthessek modellek építésével és fejlesztésével ahelyett, hogy elmagyaráznám a mögöttes elméletet. Merüljünk bele.

Minden gép tanulási modellek vannak kategorizálva, mint akár felügyelt vagy felügyelet nélkül. Ha a modell felügyelt modell, akkor regressziós vagy osztályozási modellként kategorizálódik. Áttekintjük, hogy mit jelentenek ezek a kifejezések, valamint a megfelelő modelleket, amelyek az alábbi kategóriákba tartoznak.
a felügyelt tanulás magában foglalja egy olyan funkció megtanulását, amely egy bemenetet egy kimenetre térképez fel a példa input-output párok alapján .
például, ha lenne egy adatkészletem két változóval, az életkor (input) és a magasság (output), akkor egy felügyelt tanulási modellt alkalmazhatnék, hogy megjósoljam egy személy magasságát az életkoruk alapján.
/figcaption >
a felügyelt tanuláson belül két alkategória létezik: regresszió és osztályozás.
regresszió
regressziós modellekben a kimenet folyamatos. Az alábbiakban bemutatjuk a regressziós modellek leggyakoribb típusait.
Lineáris Regresszió

Az ötlet, hogy a lineáris regresszió egyszerűen megtalálni a vonalat, amely a legjobban illeszkedik az adatokra. A lineáris regresszió kiterjesztései közé tartozik a többszörös lineáris regresszió(pl. a legjobban illeszkedő sík megtalálása) és a polinom regresszió (pl. a legjobban illeszkedő görbe megtalálása). A lineáris regresszióról többet megtudhat az előző cikkemben.
döntési Fa
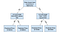
döntési fák egy népszerű modell, használt műveletek a kutatás, a stratégiai tervezés, valamint a gépi tanulás. Minden fenti négyzetet csomópontnak nevezünk, és minél több csomópont van, annál pontosabb lesz a döntési fa (általában). A döntési fa utolsó csomópontjait, ahol döntést hoznak, a fa leveleinek nevezzük. A döntési fák intuitívak és könnyen felépíthetők, de a pontosság szempontjából elmaradnak.
véletlenszerű erdő
a véletlenszerű erdők egy együttes tanulási technika, amely döntési fákból épül fel. A véletlenszerű erdők magukban foglalják több döntési fa létrehozását az eredeti adatok bootstrappolt adatkészleteinek felhasználásával, valamint a változók egy részhalmazának véletlenszerű kiválasztását a döntési fa minden lépésénél. A modell ezután kiválasztja az egyes döntési fák összes előrejelzésének módját. Mi értelme van ennek? A “többségi győzelem” modellre támaszkodva csökkenti az egyes fa hibakockázatát.

például, ha létrehoznánk egy döntési fát, a harmadikat, az 0-t jósolna. De ha mind a 4 döntési fa módjára támaszkodnánk, akkor az előre jelzett érték 1 lenne. Ez a véletlenszerű erdők ereje.
a StatQuest csodálatos munkát végez ezen részletesebben. Lásd itt.
Neurális Hálózat

A Neurális Hálózat lényegében egy hálózat matematikai egyenletek. Egy vagy több bemeneti változót vesz igénybe, és az egyenletek hálózatán keresztül egy vagy több kimeneti változót eredményez. Azt is mondhatjuk, hogy egy neurális hálózat bevesz egy bemeneti vektort, és visszaad egy kimeneti vektort, de ebben a cikkben nem fogok bejutni a mátrixokba.
a kék körök a bemeneti réteget, a fekete körök a rejtett rétegeket, a zöld körök pedig a kimeneti réteget képviselik. A rejtett rétegek minden csomópontja mind lineáris függvényt, mind aktiválási funkciót képvisel, amelyen az előző réteg csomópontjai átmennek, végül a zöld körök kimenetéhez vezet.
- Ha többet szeretne megtudni róla, nézze meg a kezdőbarát magyarázatomat a neurális hálózatokról.
osztályozás
osztályozási modellekben a kimenet diszkrét. Az alábbiakban bemutatjuk az osztályozási modellek leggyakoribb típusait.
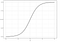
logisztikai regresszió
a logisztikai regresszió hasonló a lineáris regresszióhoz, de a véges számú kimenetel valószínűségének modellezésére szolgál, jellemzően kettő. Számos oka van annak, hogy a logisztikai regressziót a lineáris regresszióval szemben alkalmazzák az eredmények valószínűségének modellezésekor (lásd itt). Lényegében egy logisztikai egyenlet úgy jön létre, hogy a kimeneti értékek csak 0 és 1 között lehetnek (lásd alább).
support vector machine
a Support Vector Machine egy felügyelt osztályozási technika, amely valójában elég bonyolult, de a legalapvetőbb szinten elég intuitív.
tegyük fel, hogy két adatosztály létezik. A támogató vektor gép hipersíkot vagy határt talál a két adatosztály között, amely maximalizálja a két osztály közötti margót (lásd alább). Sok sík képes elválasztani a két osztályt, de csak egy sík képes maximalizálni az osztályok közötti margót vagy távolságot.
Ha azt szeretnénk, hogy részletesebben, Savan írt egy nagy cikket támogató vektor gépek itt.
naiv Bayes
a naiv Bayes egy másik népszerű osztályozó, amelyet az Adattudományban használnak. A mögöttes ötletet a Bayes-tétel vezérli:
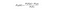
egyszerű angol nyelven ez az egyenlet a következő kérdés megválaszolására szolgál. “Mi a valószínűsége annak, hogy y (a kimeneti változó) adott X? A naiv feltételezés miatt, miszerint a változók függetlenek az osztálytól függően, azt mondhatjuk, hogy:

a nevező eltávolításával azt is mondhatjuk, hogy p(y / x) arányos a jobb oldallal.

ezért a cél az Y osztály megtalálása a maximális arányos valószínűséggel.
nézze meg a “naiv Bayes matematikai magyarázata” című cikkemet, ha mélyebb magyarázatot szeretne!
döntési fa, véletlenszerű erdő, neurális hálózat
ezek a modellek ugyanazt a logikát követik, mint korábban kifejtettük. Az egyetlen különbség az, hogy ez a kimenet diszkrét, nem pedig folyamatos.
felügyelet nélküli tanulás

a felügyelt tanulással ellentétben a felügyelet nélküli tanulást arra használják, hogy következtetéseket vonjanak le és mintákat találjanak a bemeneti adatokból, anélkül, hogy hivatkoznának a címkézett eredményekre. A felügyelet nélküli tanulásban alkalmazott két fő módszer a klaszterezés és a dimenziócsökkentés.