Deep Learning per la Rilevazione di Polmonite da raggi X Immagini
Un gasdotto per polmonite di rilevamento a raggi x. le immagini
Bloccato dietro il paywall? Clicca qui per leggere la storia completa con il mio amico Link!
Il rischio di polmonite è immenso per molti, specialmente nei paesi in via di sviluppo dove miliardi di persone affrontano la povertà energetica e si affidano a forme di energia inquinanti. L’OMS stima che oltre 4 milioni di morti premature si verificano ogni anno da malattie legate all’inquinamento atmosferico domestico, tra cui la polmonite. Oltre 150 milioni di persone vengono infettate da polmonite su base annuale, in particolare i bambini sotto i 5 anni. In tali regioni, il problema può essere ulteriormente aggravato a causa della carenza di risorse mediche e personale. Ad esempio, nelle 57 nazioni africane esiste un divario di 2,3 milioni di medici e infermieri. Per queste popolazioni, una diagnosi accurata e veloce significa tutto. Può garantire un accesso tempestivo alle cure e risparmiare tempo e denaro per coloro che già soffrono di povertà.
Questo progetto è una parte delle immagini a raggi X del torace (polmonite) tenuto su Kaggle.
Crea un algoritmo per identificare automaticamente se un paziente soffre di polmonite o meno guardando le immagini a raggi X del torace. L’algoritmo doveva essere estremamente preciso perché la vita delle persone è in gioco.
Ambiente e strumenti
- scikit-imparare
- keras
- numpy
- panda
- matplotlib
Dati
Il set di dati possono essere scaricati dal kaggle sito web che può essere trovato qui.
Dov’è il codice?
Senza molto rumore, iniziamo con il codice. Il progetto completo su github può essere trovato qui.
Iniziamo con il caricamento di tutte le librerie e le dipendenze.
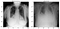
Successivamente ho visualizzato alcune immagini normali e polmoniti per dare un’occhiata a quanto sono diverse dall’occhio nudo. Beh, non molto!
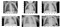
Poi ho diviso il set di dati in tre set — treno, validazione e test set.
Successivamente ho scritto una funzione in cui ho fatto un po ‘ di aumento dei dati, alimentato le immagini di formazione e test set alla rete. Inoltre ho creato etichette per le immagini.
La pratica dell’aumento dei dati è un modo efficace per aumentare le dimensioni del set di allenamento. L’aumento degli esempi di formazione consente alla rete di” vedere ” punti dati più diversificati, ma comunque rappresentativi, durante l’allenamento.
Quindi ho definito un paio di generatori di dati: uno per i dati di allenamento e l’altro per i dati di convalida. Un generatore di dati è in grado di caricare la quantità richiesta di dati (un mini batch di immagini) direttamente dalla cartella di origine, convertirli in dati di allenamento (alimentati al modello) e obiettivi di allenamento (un vettore di attributi — il segnale di supervisione).
Per i miei esperimenti, di solito imposto il
batch_size = 64. In generale un valore compreso tra 32 e 128 dovrebbe funzionare bene. Di solito è necessario aumentare / diminuire la dimensione del batch in base alle risorse computazionali e alle prestazioni del modello.
Dopo di che ho definito alcune costanti per un uso successivo.
Il passo successivo è stato quello di costruire il modello. Questo può essere descritto nei seguenti 5 passaggi.
- Ho usato cinque blocchi convoluzionali composti da livello convoluzionale, max-pooling e normalizzazione batch.
- Sopra di esso ho usato uno strato appiattito e lo ho seguito da quattro strati completamente collegati.
- Anche in mezzo ho usato forcellini per ridurre il montaggio eccessivo.
- La funzione di attivazione era Relu in tutto tranne che per l’ultimo livello in cui era Sigmoid in quanto questo è un problema di classificazione binaria.
- Ho usato Adam come ottimizzatore e cross-entropy come perdita.
Prima dell’allenamento il modello è utile per definire uno o più callback. Uno piuttosto utile, sono: ModelCheckpointeEarlyStopping.
- ModelCheckpoint: quando l’allenamento richiede molto tempo per ottenere un buon risultato, spesso sono necessarie molte iterazioni. In questo caso, è meglio salvare una copia del modello con le migliori prestazioni solo quando termina un’epoca che migliora le metriche.
- EarlyStopping: a volte, durante l’allenamento possiamo notare che il divario di generalizzazione (cioè la differenza tra allenamento e errore di convalida) inizia ad aumentare, invece di diminuire. Questo è un sintomo di overfitting che può essere risolto in molti modi (riduzione della capacità del modello, aumento dei dati di allenamento, aumento dei dati, regolarizzazione, abbandono, ecc.). Spesso una soluzione pratica ed efficiente è quella di interrompere l’allenamento quando il divario di generalizzazione sta peggiorando.

poi mi sono allenato il modello per 10 epoche con un batch dimensione di 32. Si prega di notare che di solito una maggiore dimensione del lotto dà risultati migliori, ma a scapito di un maggiore carico computazionale. Alcune ricerche affermano anche che esiste una dimensione del lotto ottimale per i migliori risultati che potrebbero essere trovati investendo un po ‘ di tempo sulla messa a punto dei parametri iper.
Visualizziamo i grafici di perdita e precisione.

fin qui tutto bene. Il modello sta convergendo che può essere osservato dalla diminuzione della perdita e della perdita di convalida con le epoche. Inoltre è in grado di raggiungere il 90% di precisione di convalida in soli 10 epoche.
Tracciamo la matrice confusione e ottenere alcuni degli altri risultati anche come precisione, richiamo, punteggio F1 e precisione.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
Il modello è in grado di ottenere una precisione del 91,02% che è abbastanza buona considerando la dimensione dei dati utilizzati.
Conclusioni
Anche se questo progetto è lungi dall’essere completo, ma è notevole vedere il successo di apprendimento profondo in tali vari problemi del mondo reale. Ho dimostrato come classificare i dati di polmonite positivi e negativi da una raccolta di immagini a raggi X. Il modello è stato fatto da zero, che lo separa da altri metodi che si basano molto sul trasferimento approccio di apprendimento. In futuro questo lavoro potrebbe essere esteso per rilevare e classificare le immagini a raggi X costituite da cancro ai polmoni e polmonite. Distinguere le immagini a raggi X che contengono cancro ai polmoni e polmonite è stato un grosso problema negli ultimi tempi, e il nostro prossimo approccio dovrebbe essere quello di affrontare questo problema.