Meltdown e Spectre, spiegato
Anche se in questi giorni sono principalmente conosciuto per il networking a livello di applicazione e sistemi distribuiti, ho trascorso la prima parte della mia carriera lavorando su sistemi operativi e hypervisor. Mantengo un profondo fascino con i dettagli di basso livello di come funzionano i moderni processori e sistemi software. Quando sono state annunciate le recenti vulnerabilità Meltdown e Spectre, ho scavato nelle informazioni disponibili ed ero desideroso di saperne di più.
Le vulnerabilità sono sorprendenti; Direi che sono una delle scoperte più importanti in informatica negli ultimi 10-20 anni. Le attenuanti sono anche difficili da capire e informazioni accurate su di loro è difficile da trovare. Questo non è sorprendente data la loro natura critica. Mitigare le vulnerabilità ha richiesto mesi di lavoro segreto da parte di tutti i principali fornitori di CPU, sistema operativo e cloud. Il fatto che i problemi siano stati tenuti nascosti per 6 mesi quando letteralmente centinaia di persone stavano probabilmente lavorando su di loro è sorprendente.
Anche se molto è stato scritto su Meltdown e Spectre dal loro annuncio, non ho visto una buona introduzione di medio livello alle vulnerabilità e alle mitigazioni. In questo post ho intenzione di tentare di correggere che, fornendo una delicata introduzione allo sfondo hardware e software necessari per comprendere le vulnerabilità, una discussione delle vulnerabilità stesse, così come una discussione delle attuali mitigazioni.
Nota importante: perché non ho lavorato direttamente sulle mitigazioni e non lavoro su Intel, Microsoft, Google, Amazon, Red Hat, ecc. alcuni dei dettagli che ho intenzione di fornire potrebbero non essere del tutto accurati. Ho messo insieme questo post in base alla mia conoscenza di come funzionano questi sistemi, alla documentazione disponibile pubblicamente e alle patch/discussioni pubblicate su LKML e xen-devel. Mi piacerebbe essere corretto se uno qualsiasi di questo post è impreciso, anche se dubito che accadrà presto dato quanto di questo argomento è ancora coperto da NDA.
In questa sezione fornirò alcuni background necessari per comprendere le vulnerabilità. La sezione sorvola su una grande quantità di dettagli ed è rivolta ai lettori con una comprensione limitata dell’hardware del computer e del software dei sistemi.
Memoria virtuale
La memoria virtuale è una tecnica utilizzata da tutti i sistemi operativi dal 1970. Fornisce uno strato di astrazione tra il layout degli indirizzi di memoria che la maggior parte del software vede e i dispositivi fisici che supportano tale memoria(RAM, dischi, ecc.). Ad un livello elevato, consente alle applicazioni di utilizzare più memoria di quella che la macchina ha effettivamente; ciò fornisce una potente astrazione che semplifica molte attività di programmazione.

la Figura 1 mostra un semplice computer con 400 byte di memoria di cui in “pagine” di 100 byte (reale i computer utilizzano potenze di due, in genere 4096). Il computer ha due processi, ciascuno con 200 byte di memoria su 2 pagine ciascuno. I processi potrebbero eseguire lo stesso codice utilizzando indirizzi fissi nell’intervallo 0-199 byte, tuttavia sono supportati da memoria fisica discreta in modo tale da non influenzarsi a vicenda. Sebbene i moderni sistemi operativi e computer utilizzino la memoria virtuale in un modo sostanzialmente più complicato di quello presentato in questo esempio, la premessa di base presentata sopra vale in tutti i casi. I sistemi operativi stanno astraendo gli indirizzi che l’applicazione vede dalle risorse fisiche che li supportano.
Tradurre indirizzi virtuali in fisici è un’operazione così comune nei computer moderni che se il sistema operativo dovesse essere coinvolto in tutti i casi il computer sarebbe incredibilmente lento. L’hardware moderno della CPU fornisce un dispositivo chiamato Translation Lookaside Buffer (TLB) che memorizza nella cache le mappature utilizzate di recente. Ciò consente alle CPU di eseguire la traduzione degli indirizzi direttamente nell’hardware la maggior parte del tempo.
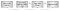
La figura 2 mostra il flusso di traduzione degli indirizzi:
- Un programma recupera un indirizzo virtuale.
- La CPU tenta di tradurlo usando il TLB. Se viene trovato l’indirizzo, viene utilizzata la traduzione.
- Se l’indirizzo non viene trovato, la CPU consulta una serie di “tabelle di pagina” per determinare la mappatura. Le tabelle di pagina sono un insieme di pagine di memoria fisica fornite dal sistema operativo in una posizione in cui l’hardware può trovarle (ad esempio il registro CR3 sull’hardware x86). Le tabelle delle pagine associano gli indirizzi virtuali agli indirizzi fisici e contengono anche metadati come le autorizzazioni.
- Se la tabella delle pagine contiene una mappatura, viene restituita, memorizzata nella cache del TLB e utilizzata per la ricerca. Se la tabella delle pagine non contiene una mappatura, viene generato un “errore di pagina” nel sistema operativo. Un errore di pagina è un tipo speciale di interrupt che consente al sistema operativo di prendere il controllo e determinare cosa fare quando è presente una mappatura mancante o non valida. Ad esempio, il sistema operativo potrebbe terminare il programma. Potrebbe anche allocare una certa memoria fisica e mapparla nel processo. Se un gestore di errori di pagina continua l’esecuzione, la nuova mappatura verrà utilizzata dal TLB.

la Figura 3 mostra un po ‘ più realistico di quello che la memoria virtuale appare come in un moderno computer (pre-Collasso — più su questo più avanti). In questa configurazione abbiamo le seguenti caratteristiche:
- La memoria del kernel è mostrata in rosso. È contenuto nell’intervallo di indirizzi fisici 0-99. La memoria del kernel è una memoria speciale a cui solo il sistema operativo dovrebbe essere in grado di accedere. I programmi utente non dovrebbero essere in grado di accedervi.
- La memoria utente è mostrata in grigio.
- La memoria fisica non allocata è mostrata in blu.
In questo esempio, iniziamo a vedere alcune delle utili funzionalità della memoria virtuale. Principalmente:
- La memoria utente in ogni processo è nell’intervallo virtuale 0-99, ma supportata da una memoria fisica diversa.
- La memoria del kernel in ogni processo è nell’intervallo virtuale 100-199, ma supportata dalla stessa memoria fisica.
Come ho brevemente menzionato nella sezione precedente, ogni pagina ha bit di autorizzazione associati. Anche se la memoria del kernel è mappata in ogni processo utente, quando il processo è in esecuzione in modalità utente non può accedere alla memoria del kernel. Se un processo tenta di farlo, attiverà un errore di pagina a quel punto il sistema operativo lo terminerà. Tuttavia, quando il processo è in esecuzione in modalità kernel (ad esempio durante una chiamata di sistema), il processore consentirà l’accesso.
A questo punto noterò che questo tipo di dual mapping (ogni processo con il kernel mappato direttamente in esso) è stata una pratica standard nella progettazione del sistema operativo per oltre trent’anni per motivi di prestazioni (le chiamate di sistema sono molto comuni e ci vorrebbe molto tempo per rimappare il kernel o lo spazio utente in ogni transizione).
cache della CPU topologia

Il prossimo pezzo di informazioni di base necessarie per comprendere le vulnerabilità è la topologia della CPU e della cache dei processori moderni. Figura 4 mostra una topologia generica che è comune alla maggior parte delle CPU moderne. È composto dai seguenti componenti:
- L’unità di base di esecuzione è il “thread CPU” o “thread hardware” o “hyper-thread.”Ogni thread della CPU contiene un set di registri e la possibilità di eseguire un flusso di codice macchina, proprio come un thread software.
- I thread della CPU sono contenuti all’interno di un ” core della CPU.”La maggior parte delle CPU moderne contiene due thread per core.
- Le CPU moderne contengono generalmente più livelli di memoria cache. I livelli di cache più vicini al thread della CPU sono più piccoli, più veloci e più costosi. Più lontano dalla CPU e più vicino alla memoria principale, la cache è più grande, più lenta e meno costosa.
- Il tipico design moderno della CPU utilizza una cache L1/L2 per core. Ciò significa che ogni thread della CPU sul core utilizza le stesse cache.
- Più core CPU sono contenuti in un ” pacchetto CPU.”Le CPU moderne potrebbero contenere fino a 30 core (60 thread) o più per pacchetto.
- Tutti i core della CPU nel pacchetto in genere condividono una cache L3.
- I pacchetti CPU si inseriscono in ” socket.”La maggior parte dei computer consumer sono socket singoli mentre molti server datacenter hanno socket multipli.
esecuzione Speculativa

L’ultimo pezzo di informazioni di base necessarie per comprendere le vulnerabilità è una moderna tecnica della CPU nota come ” esecuzione speculativa.”Figura 5 mostra un diagramma generico del motore di esecuzione all’interno di una CPU moderna.
L’asporto principale è che le CPU moderne sono incredibilmente complicate e non eseguono semplicemente le istruzioni della macchina in ordine. Ogni thread della CPU ha un complicato motore di pipelining che è in grado di eseguire istruzioni fuori servizio. La ragione di ciò ha a che fare con il caching. Come ho discusso nella sezione precedente, ogni CPU fa uso di più livelli di caching. Ogni cache miss aggiunge una notevole quantità di tempo di ritardo per l’esecuzione del programma. Al fine di mitigare questo, i processori sono in grado di eseguire in anticipo e fuori servizio durante l’attesa di carichi di memoria. Questo è noto come esecuzione speculativa. Il seguente frammento di codice lo dimostra.
if (x < array1_size) {
y = array2 * 256];
}
Nel frammento precedente, immagina che array1_sizenon sia disponibile nella cache, ma l’indirizzo di array1 lo sia. La CPU potrebbe indovinare (speculare) che x è inferiore a array1_size e andare avanti ed eseguire i calcoli all’interno dell’istruzione if. Una volta chearray1_size viene letto dalla memoria, la CPU può determinare se ha indovinato correttamente. Se lo ha fatto, può continuare a risparmiare un po ‘ di tempo. In caso contrario, può buttare via i calcoli speculativi e ricominciare da capo. Questo non è peggio che se avesse aspettato in primo luogo.
Un altro tipo di esecuzione speculativa è noto come previsione indiretta del ramo. Questo è estremamente comune nei programmi moderni a causa della spedizione virtuale.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(L’origine dello snippet precedente è questo post)
Il modo in cui lo snippet precedente è implementato nel codice macchina consiste nel caricare la “v-table” o “virtual dispatch table” dalla posizione di memoria a cuiobj punta e quindi chiamarla. Poiché questa operazione è così comune, le CPU moderne hanno varie cache interne e spesso indovinano (speculano) dove andrà il ramo indiretto e continuerà l’esecuzione a quel punto. Ancora una volta, se la CPU indovina correttamente, può continuare a risparmiare un po ‘ di tempo. In caso contrario, può buttare via i calcoli speculativi e ricominciare da capo.
Vulnerabilità Meltdown
Avendo ora coperto tutte le informazioni di base, possiamo immergerci nelle vulnerabilità.
Rogue data cache load
La prima vulnerabilità, nota come Meltdown, è sorprendentemente semplice da spiegare e quasi banale da sfruttare. Il codice di exploit assomiglia approssimativamente al seguente:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
Prendiamo ogni passo sopra, descriviamo cosa fa e come porta ad essere in grado di leggere la memoria dell’intero computer da un programma utente.
- Nella prima riga, viene allocato un “probe array”. Questa è la memoria nel nostro processo che viene utilizzata come canale laterale per recuperare i dati dal kernel. Come questo è fatto diventerà evidente presto.
- Dopo l’allocazione, l’attaccante si assicura che nessuna memoria nell’array probe sia memorizzata nella cache. Esistono vari modi per raggiungere questo obiettivo, il più semplice dei quali include istruzioni specifiche della CPU per cancellare una posizione di memoria dalla cache.
- L’attaccante procede quindi a leggere un byte dallo spazio degli indirizzi del kernel. Ricorda dalla nostra precedente discussione sulla memoria virtuale e sulle tabelle delle pagine che tutti i kernel moderni in genere mappano l’intero spazio degli indirizzi virtuali del kernel nel processo utente. I sistemi operativi si basano sul fatto che ogni voce della tabella delle pagine ha impostazioni di autorizzazione e che i programmi in modalità utente non sono autorizzati ad accedere alla memoria del kernel. Qualsiasi accesso di questo tipo comporterà un errore di pagina. Questo è davvero ciò che alla fine accadrà al punto 3.
- Tuttavia, i processori moderni eseguono anche l’esecuzione speculativa e verranno eseguiti prima dell’istruzione di errore. Pertanto, i passaggi 3-5 possono essere eseguiti nella pipeline della CPU prima che l’errore venga generato. In questo passaggio, il byte di memoria del kernel (che varia da 0 a 255) viene moltiplicato per la dimensione della pagina del sistema, che in genere è 4096.
- In questo passaggio, il byte moltiplicato della memoria del kernel viene quindi utilizzato per leggere dall’array probe in un valore fittizio. La moltiplicazione del byte per 4096 è quella di evitare una funzionalità della CPU chiamata “prefetcher” dalla lettura di più dati di quelli che vogliamo nella cache.
- Di questo passo, la CPU ha realizzato il suo errore e il rollback al passaggio 3. Tuttavia, i risultati delle istruzioni ipotizzate sono ancora visibili nella cache. L’utente malintenzionato utilizza la funzionalità del sistema operativo per intrappolare l’istruzione in errore e continuare l’esecuzione (ad esempio, la gestione di SIGFAULT).
- Nel passaggio 7, l’attaccante itera e vede quanto tempo ci vuole per leggere ciascuno dei 256 byte possibili nell’array probe che potrebbero essere stati indicizzati dalla memoria del kernel. La CPU avrà caricato una delle posizioni nella cache e questa posizione verrà caricata sostanzialmente più velocemente di tutte le altre posizioni (che devono essere lette dalla memoria principale). Questa posizione è il valore del byte nella memoria del kernel.
Utilizzando la tecnica di cui sopra, e il fatto che è pratica standard per i moderni sistemi operativi per mappare tutta la memoria fisica nello spazio degli indirizzi virtuali del kernel, un utente malintenzionato può leggere l’intera memoria fisica del computer.
Ora, potresti chiederti: “Hai detto che le tabelle delle pagine hanno bit di autorizzazione. Come può essere che il codice della modalità utente sia stato in grado di accedere speculativamente alla memoria del kernel?”Il motivo è che questo è un bug nei processori Intel. A mio parere, non c’è una buona ragione, prestazioni o altro, per questo sia possibile. Ricordiamo che tutto l’accesso alla memoria virtuale deve avvenire attraverso il TLB. È facilmente possibile durante l’esecuzione speculativa verificare che una mappatura memorizzata nella cache abbia autorizzazioni compatibili con il livello di privilegio corrente in esecuzione. L’hardware Intel semplicemente non lo fa. Altri fornitori di processori eseguono un controllo delle autorizzazioni e bloccano l’esecuzione speculativa. Quindi, per quanto ne sappiamo, Meltdown è una vulnerabilità Intel only.
Modifica: Sembra che almeno un processore ARM sia anche suscettibile di fusione come indicato qui e qui.
Meltdown mitigations
Meltdown è facile da capire, banale da sfruttare e fortunatamente ha anche una mitigazione relativamente semplice (almeno concettualmente — gli sviluppatori del kernel potrebbero non essere d’accordo sul fatto che sia semplice da implementare).
Kernel page table isolation (KPTI)
Ricordiamo che nella sezione sulla memoria virtuale ho descritto che tutti i sistemi operativi moderni utilizzano una tecnica in cui la memoria del kernel è mappata in ogni processo di modalità utente spazio di indirizzi di memoria virtuale. Questo è sia per motivi di prestazioni che di semplicità. Significa che quando un programma effettua una chiamata di sistema, il kernel è pronto per essere utilizzato senza ulteriori lavori. La correzione per Meltdown è di non eseguire più questa doppia mappatura.

la Figura 6 mostra una tecnica chiamata Kernel Pagina Tabella di Isolamento (KPTI). Questo si riduce fondamentalmente a non mappare la memoria del kernel in un programma quando è in esecuzione nello spazio utente. Se non è presente alcuna mappatura, l’esecuzione speculativa non è più possibile e si verificherà immediatamente.
oltre a rendere la memoria virtuale del sistema operativo manager (VMM) più complicato, senza assistenza hardware questa tecnica anche rallentare notevolmente i carichi di lavoro che fare un gran numero di user mode kernel mode transizioni, a causa del fatto che le tabelle di pagina devono essere modificati in ogni transizione e il TLB deve essere eliminato (dato che il TLB può tenere raffermo mapping).
Le nuove CPU x86 hanno una funzionalità nota come ASID (address space ID) o PCID (process context ID) che può essere utilizzata per rendere questa attività sostanzialmente più economica (ARM e altre microarchitetture hanno questa funzionalità per anni). PCID consente di associare un ID a una voce TLB e quindi di svuotare solo le voci TLB con quell’ID. L’uso di PCID rende KPTI più economico, ma non ancora gratuito.
In sintesi, Meltdown è una vulnerabilità estremamente grave e facile da sfruttare. Fortunatamente ha una mitigazione relativamente semplice che è già stata implementata da tutti i principali fornitori di sistemi operativi, l’avvertenza è che alcuni carichi di lavoro verranno eseguiti più lentamente fino a quando l’hardware futuro non sarà esplicitamente progettato per la separazione dello spazio degli indirizzi descritta.
Vulnerabilità Spectre
Spectre condivide alcune proprietà di Meltdown ed è composto da due varianti. A differenza di Meltdown, Spectre è sostanzialmente più difficile da sfruttare, ma colpisce quasi tutti i processori moderni prodotti negli ultimi venti anni. In sostanza, Spectre è un attacco contro la moderna progettazione della CPU e del sistema operativo rispetto a una specifica vulnerabilità di sicurezza.
Bounds check bypass (variante Spectre 1)
La prima variante Spectre è nota come “bounds check bypass.”Questo è dimostrato nel seguente frammento di codice (che è lo stesso frammento di codice che ho usato per introdurre l’esecuzione speculativa sopra).
if (x < array1_size) {
y = array2 * 256];
}
Nell’esempio precedente, assumere la seguente sequenza di eventi:
- L’attaccante controlla
x. -
array1_sizenon è memorizzato nella cache. -
array1è memorizzato nella cache. - La CPU indovina che
xè inferiore aarray1_size. (Le CPU impiegano vari algoritmi proprietari ed euristiche per determinare se speculare, motivo per cui i dettagli di attacco per Spectre variano tra produttori di processori e modelli.) - La CPU esegue il corpo dell’istruzione if mentre è in attesa del caricamento di
array1_size, influenzando la cache in modo simile a Meltdown. - L’utente malintenzionato può quindi determinare il valore effettivo di
array1tramite uno dei vari metodi. (Vedere il documento di ricerca per maggiori dettagli sugli attacchi di inferenza della cache.)
Spectre è considerevolmente più difficile da sfruttare rispetto a Meltdown perché questa vulnerabilità non dipende dall’escalation dei privilegi. L’attaccante deve convincere il kernel a eseguire il codice e speculare in modo errato. In genere l’attaccante deve avvelenare il motore di speculazione e ingannare in indovinare in modo errato. Detto questo, i ricercatori hanno dimostrato diversi exploit proof-of-concept.
Voglio ribadire quanto sia davvero incredibile questo exploit. Personalmente non considero questo un difetto di progettazione della CPU come Meltdown di per sé. Considero questa una rivelazione fondamentale su come hardware e software moderni lavorano insieme. Il fatto che le cache della CPU possano essere utilizzate indirettamente per conoscere i modelli di accesso è noto da tempo. Il fatto che le cache della CPU possano essere utilizzate come canale laterale per scaricare la memoria del computer è sorprendente, sia concettualmente che nelle sue implicazioni.
Branch target injection (Spectre variant 2)
Ricordiamo che la ramificazione indiretta è molto comune nei programmi moderni. La variante 2 di Spectre utilizza la previsione indiretta del ramo per avvelenare la CPU in modo speculativo eseguendo in una posizione di memoria che non avrebbe mai altrimenti eseguito. Se l’esecuzione di tali istruzioni può lasciare lo stato nella cache che può essere rilevato utilizzando gli attacchi di inferenza della cache, l’utente malintenzionato può quindi scaricare tutta la memoria del kernel. Come Spectre variant 1, Spectre variant 2 è molto più difficile da sfruttare rispetto a Meltdown, tuttavia i ricercatori hanno dimostrato di funzionare exploit proof-of-concept della variante 2.
Mitigazioni dello spettro
Le mitigazioni dello Spettro sono sostanzialmente più interessanti della mitigazione del Meltdown. In effetti, il documento Spectre accademico scrive che al momento non ci sono attenuanti note. Sembra che dietro le quinte e in parallelo al lavoro accademico, Intel (e probabilmente altri fornitori di CPU) e i principali fornitori di sistemi operativi e cloud abbiano lavorato furiosamente per mesi per sviluppare mitigazioni. In questa sezione tratterò le varie mitigazioni che sono state sviluppate e implementate. Questa è la sezione su cui sono più confuso in quanto è incredibilmente difficile ottenere informazioni accurate, quindi sto mettendo insieme le cose da varie fonti.
Static analysis and fencing (variant 1 mitigation)
L’unica mitigazione nota della variante 1 (bounds check bypass) è l’analisi statica del codice per determinare sequenze di codice che potrebbero essere controllate dall’attaccante per interferire con la speculazione. Le sequenze di codice vulnerabili possono avere un’istruzione di serializzazione come lfence inserita che interrompe l’esecuzione speculativa fino a quando tutte le istruzioni fino alla recinzione sono state eseguite. Bisogna fare attenzione quando si inseriscono le istruzioni di recinzione in quanto troppe possono avere gravi impatti sulle prestazioni.
Retpoline (variant 2 mitigation)
La prima mitigazione Spectre variant 2 (branch target injection) è stata sviluppata da Google ed è conosciuta come “retpoline.” Non è chiaro a me se è stato sviluppato in isolamento da Google o da Google in collaborazione con Intel. Vorrei speculare che è stato sviluppato sperimentalmente da Google e poi verificato da ingegneri hardware Intel, ma non sono sicuro. I dettagli sull’approccio” retpoline ” possono essere trovati nel documento di Google sull’argomento. Li riassumerò qui (sto sorvolando alcuni dettagli tra cui underflow che sono coperti nel documento).
Retpoline si basa sul fatto che la chiamata e il ritorno dalle funzioni e le manipolazioni dello stack associate sono così comuni nei programmi per computer che le CPU sono fortemente ottimizzate per eseguirle. (Se non si ha familiarità con il funzionamento dello stack in relazione alla chiamata e al ritorno dalle funzioni, questo post è un buon primer.) In poche parole, quando viene eseguita una “chiamata”, l’indirizzo di ritorno viene inserito nello stack. ” ret ” apre l’indirizzo di ritorno e continua l’esecuzione. L’hardware di esecuzione speculativa ricorderà l’indirizzo di ritorno spinto e continuerà speculativamente l’esecuzione a quel punto.
La costruzione retpoline sostituisce un salto indiretto alla posizione di memoria memorizzata nel registror11:
jmp *%r11
con:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
Vediamo cosa fa il codice assembly precedente un passo alla volta e come mitiga l’iniezione del target di branch.
- In questo passaggio il codice chiama una posizione di memoria che è nota in fase di compilazione, quindi è un offset hard coded e non indiretto. Questo pone l’indirizzo di ritorno di
capture_specin pila. - L’indirizzo di ritorno dalla chiamata viene sovrascritto con il target di salto effettivo.
- Un ritorno viene eseguito sul bersaglio reale.
- Quando la CPU viene eseguita speculativamente, tornerà in un ciclo infinito! Ricordate che la CPU speculare avanti fino a quando i carichi di memoria sono completi. In questo caso, la speculazione è stata manipolata per essere catturata in un ciclo infinito che non ha effetti collaterali osservabili da un utente malintenzionato. Quando la CPU alla fine esegue il ritorno reale, interromperà l’esecuzione speculativa che non ha avuto alcun effetto.
A mio parere, questa è una mitigazione davvero ingegnosa. Complimenti agli ingegneri che l’hanno sviluppato. L’aspetto negativo di questa mitigazione è che richiede che tutto il software sia ricompilato in modo tale che i rami indiretti vengano convertiti in rami retpoline. Per i servizi cloud come Google che possiedono l’intero stack, la ricompilazione non è un grosso problema. Per gli altri, può essere un grosso problema o impossibile.
IBRS, STIBP e IBPB (variant 2 mitigation)
Sembra che in concomitanza con lo sviluppo di retpoline, Intel (e AMD in una certa misura) abbiano lavorato furiosamente sulle modifiche hardware per mitigare gli attacchi di iniezione di target di filiale. Le tre nuove funzionalità hardware che vengono fornite come aggiornamenti del microcodice della CPU sono:
- Indirect Branch Restricted Speculation (IBRS)
- Single Thread Indirect Branch Predictors (STIBP)
- Indirect Branch Predictor Barrier (IBPB)
Informazioni limitate sulle nuove funzionalità del microcodice sono disponibili da Intel qui. Sono stato in grado di mettere insieme approssimativamente ciò che queste nuove funzionalità fanno leggendo la documentazione di cui sopra e guardando le patch del kernel Linux e dell’hypervisor Xen. Dalla mia analisi, ogni funzione è potenzialmente utilizzata come segue:
- IBRS svuota la cache di previsione del ramo tra i livelli di privilegio (dall’utente al kernel) e disabilita la previsione del ramo sul thread CPU fratello. Ricordiamo che ogni core della CPU ha in genere due thread della CPU. Sembra che sulle CPU moderne l’hardware di previsione del ramo sia condiviso tra i thread. Ciò significa che non solo il codice della modalità utente può avvelenare il predittore del ramo prima di inserire il codice del kernel, anche il codice in esecuzione sul thread CPU fratello può avvelenarlo. L’abilitazione di IBRS in modalità kernel impedisce essenzialmente qualsiasi esecuzione precedente in modalità utente e qualsiasi esecuzione sul thread CPU fratello di influenzare la previsione del ramo.
- STIBP sembra essere un sottoinsieme di IBRS che disabilita solo la previsione del ramo sul thread CPU fratello. Per quanto posso dire, il caso d’uso principale di questa funzione è impedire a un thread CPU fratello di avvelenare il predittore del ramo quando si eseguono due diversi processi in modalità utente (o macchine virtuali) sullo stesso core della CPU allo stesso tempo. Onestamente non mi è completamente chiaro in questo momento quando dovrebbe essere usato STIBP.
- IBPB sembra svuotare la cache di previsione del ramo per il codice in esecuzione allo stesso livello di privilegio. Questo può essere usato quando si passa da due programmi in modalità utente o due macchine virtuali per garantire che il codice precedente non interferisca con il codice che sta per essere eseguito (anche se senza STIBP credo che il codice in esecuzione sul thread CPU fratello potrebbe ancora avvelenare il predittore di ramo).
Al momento della stesura di questo articolo, le principali mitigazioni che vedo essere implementate per la vulnerabilità di iniezione del target di branch sembrano essere sia retpoline che IBRS. Presumibilmente questo è il modo più veloce per proteggere il kernel dai programmi in modalità utente o dall’hypervisor dagli ospiti della macchina virtuale. In futuro mi aspetterei che sia STIBP che IBPB vengano distribuiti a seconda del livello di paranoia dei diversi programmi in modalità utente che interferiscono l’uno con l’altro.
Anche il costo degli IBRS sembra variare molto tra le architetture della CPU con i processori Intel Skylake più recenti relativamente economici rispetto ai processori più vecchi. A Lyft, abbiamo visto un rallentamento di circa il 20% su determinati carichi di lavoro pesanti delle chiamate di sistema sulle istanze AWS C4 quando le mitigazioni sono state implementate. Vorrei speculare che Amazon srotolato IBRS e potenzialmente anche retpoline, ma non sono sicuro. Sembra che Google potrebbe aver srotolato solo retpoline nella loro nuvola.
Nel corso del tempo, mi aspetto che i processori passino a un modello IBRS “always on” in cui l’hardware si limita a pulire la separazione dei predittori dei rami tra i thread della CPU e svuota correttamente lo stato sulle modifiche a livello di privilegio. L’unica ragione per cui questo non sarebbe stato fatto oggi è il costo apparente delle prestazioni del retrofitting di questa funzionalità su microarchitetture già rilasciate tramite aggiornamenti di microcodice.
Conclusione
È molto raro che un risultato di ricerca cambi radicalmente il modo in cui i computer sono costruiti ed eseguiti. Meltdown e Spectre hanno fatto proprio questo. Questi risultati altereranno sostanzialmente la progettazione hardware e software nei prossimi 7-10 anni (il prossimo ciclo hardware della CPU) poiché i progettisti tengono conto della nuova realtà delle possibilità di perdita di dati tramite canali laterali della cache.
Nel frattempo, i risultati di Meltdown e Spectre e le relative mitigazioni avranno implicazioni sostanziali per gli utenti di computer per gli anni a venire. Nel breve termine, le mitigazioni avranno un impatto sulle prestazioni che potrebbe essere sostanziale a seconda del carico di lavoro e dell’hardware specifico. Ciò potrebbe richiedere modifiche operative per alcune infrastrutture (ad esempio, in Lyft stiamo spostando in modo aggressivo alcuni carichi di lavoro sulle istanze AWS C5 a causa del fatto che IBRS sembra funzionare sostanzialmente più velocemente sui processori Skylake e il nuovo hypervisor Nitro fornisce interrupt direttamente agli ospiti utilizzando SR-IOV e APICv, rimuovendo molte uscite di macchine virtuali per carichi di lavoro Gli utenti di computer desktop non sono immuni sia, a causa di attacchi browser proof-of-concept utilizzando JavaScript che OS e fornitori di browser stanno lavorando per mitigare. Inoltre, a causa della complessità delle vulnerabilità, è quasi certo che i ricercatori di sicurezza troveranno nuovi exploit non coperti dalle attuali mitigazioni che dovranno essere patchate.
Anche se amo lavorare in Lyft e sento che il lavoro che stiamo facendo nello spazio dell’infrastruttura dei sistemi microservizi è uno dei lavori più importanti del settore in questo momento, eventi come questo mi fanno perdere di lavorare su sistemi operativi e hypervisor. Sono estremamente geloso del lavoro eroico che è stato fatto negli ultimi sei mesi da un numero enorme di persone nella ricerca e mitigare le vulnerabilità. Mi sarebbe piaciuto farne parte!
bibliografia
- Crollo e di Spettro di pubblicazioni accademiche: https://spectreattack.com/
- Google Project Zero post del blog: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Intel Spettro hardware attenuazioni: https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- Retpoline post del blog: https://support.google.com/faqs/answer/7625886
- Buona sintesi delle informazioni note: https://github.com/marcan/speculation-bugs/blob/master/README.md