Tutti i modelli di apprendimento automatico spiegati in 6 minuti
Spiegazioni intuitive dei modelli di apprendimento automatico più popolari.

In un mio precedente articolo, Ho spiegato che la regressione è stata e ha mostrato come potrebbe essere utilizzato nell’applicazione. Questa settimana, ho intenzione di andare oltre la maggior parte dei modelli di apprendimento automatico comuni utilizzati nella pratica, in modo da poter passare più tempo a costruire e migliorare i modelli piuttosto che spiegare la teoria dietro di esso. Tuffiamoci in esso.

Tutti i modelli di apprendimento sono classificati come supervisionato o non supervisionato. Se il modello è un modello supervisionato, viene quindi sottocategorato come modello di regressione o classificazione. Andremo oltre ciò che questi termini significano e i modelli corrispondenti che rientrano in ogni categoria di seguito.
L’apprendimento supervisionato implica l’apprendimento di una funzione che associa un input a un output in base a coppie di input-output di esempio .
Ad esempio, se avessi un set di dati con due variabili, età (input) e altezza (output), potrei implementare un modello di apprendimento supervisionato per prevedere l’altezza di una persona in base alla loro età.
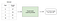
Per ripetere, all’interno di apprendimento supervisionato, ci sono due sotto-categorie: regressione e classificazione.
Regressione
Nei modelli di regressione, l’output è continuo. Di seguito sono riportati alcuni dei tipi più comuni di modelli di regressione.
di Regressione Lineare

L’idea di regressione lineare è semplicemente la ricerca di una linea che meglio si adatta ai dati. Estensioni di regressione lineare includono regressione lineare multipla (ad es. trovare un piano di migliore adattamento) e regressione polinomiale(ad es. trovare una curva di migliore vestibilità). Puoi saperne di più sulla regressione lineare nel mio precedente articolo.
struttura Decisionale
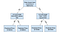
alberi di Decisione sono un modello popolare, utilizzato in operazioni di ricerca, di pianificazione strategica e di machine learning. Ogni quadrato sopra è chiamato nodo e più nodi hai, più accurato sarà il tuo albero decisionale (generalmente). Gli ultimi nodi dell’albero decisionale, in cui viene presa una decisione, sono chiamati le foglie dell’albero. Gli alberi decisionali sono intuitivi e facili da costruire, ma sono insufficienti quando si tratta di precisione.
Foresta casuale
Le foreste casuali sono una tecnica di apprendimento insieme che si basa su alberi decisionali. Le foreste casuali comportano la creazione di più alberi decisionali utilizzando set di dati bootstrap dei dati originali e selezionando casualmente un sottoinsieme di variabili ad ogni passaggio dell’albero delle decisioni. Il modello seleziona quindi la modalità di tutte le previsioni di ciascun albero delle decisioni. Che senso ha? Facendo affidamento su un modello “vince la maggioranza”, riduce il rischio di errore da un singolo albero.

Per esempio, se abbiamo creato un albero di decisione, il terzo, è in grado di prevedere 0. Ma se facessimo affidamento sulla modalità di tutti e 4 gli alberi decisionali, il valore previsto sarebbe 1. Questo è il potere delle foreste casuali.
StatQuest fa un lavoro incredibile a piedi attraverso questo in modo più dettagliato. Vedi qui.
Rete Neurale

Una Rete Neurale è essenzialmente una rete di equazioni matematiche. Richiede una o più variabili di input e, passando attraverso una rete di equazioni, si ottiene una o più variabili di output. Puoi anche dire che una rete neurale prende un vettore di input e restituisce un vettore di output, ma non entrerò nelle matrici in questo articolo.
I cerchi blu rappresentano il livello di input, i cerchi neri rappresentano i livelli nascosti e i cerchi verdi rappresentano il livello di output. Ogni nodo nei livelli nascosti rappresenta sia una funzione lineare che una funzione di attivazione che i nodi nel livello precedente attraversano, portando infine a un output nei cerchi verdi.
- Se vuoi saperne di più, dai un’occhiata alla mia spiegazione per principianti sulle reti neurali.
Classificazione
Nei modelli di classificazione, l’uscita è discreta. Di seguito sono riportati alcuni dei tipi più comuni di modelli di classificazione.
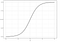
Regressione logistica
La regressione logistica è simile alla regressione lineare ma viene utilizzata per modellare la probabilità di un numero finito di risultati, in genere due. Ci sono una serie di motivi per cui la regressione logistica viene utilizzata sulla regressione lineare quando si modellano le probabilità dei risultati (vedi qui). In sostanza, viene creata un’equazione logistica in modo tale che i valori di output possano essere solo compresi tra 0 e 1 (vedi sotto).
Macchina di Vettore di Sostegno
Una Macchina di Vettore di Sostegno è una classificazione supervisionata tecnica che può effettivamente ottenere abbastanza complicato, ma è abbastanza intuitivo a livello più fondamentale.
Supponiamo che ci siano due classi di dati. Una macchina vettoriale di supporto troverà un iperpiano o un confine tra le due classi di dati che massimizza il margine tra le due classi (vedi sotto). Ci sono molti piani che possono separare le due classi, ma solo un piano può massimizzare il margine o la distanza tra le classi.

Se si desidera ottenere in dettaglio, Savan ha scritto un grande articolo su Support Vector Machines qui.
Naive Bayes
Naive Bayes è un altro classificatore popolare utilizzato nella scienza dei dati. L’idea alla base è guidata dal teorema di Bayes:
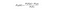
In un inglese semplice, questa è l’equazione utilizzata per rispondere alla seguente domanda. “Qual è la probabilità di y (la mia variabile di output) data X? E a causa dell’ipotesi ingenua che le variabili siano indipendenti data la classe, puoi dire che:

così, eliminando il denominatore, possiamo quindi dire che P(y|X) è proporzionale alla destra.

Pertanto l’obiettivo è per trovare la classe y con il massimo proporzionale alla probabilità.
Dai un’occhiata al mio articolo “Una spiegazione matematica di Naive Bayes” se vuoi una spiegazione più approfondita!
Albero decisionale, Foresta casuale, Rete neurale
Questi modelli seguono la stessa logica spiegata in precedenza. L’unica differenza è che quell’output è discreto piuttosto che continuo.
Unsupervised Learning

A differenza di apprendimento supervisionato, unsupervised learning è usato per trarre delle conclusioni e trovare modelli da dati di input, senza riferimenti a etichettati risultati. Due metodi principali utilizzati nell’apprendimento non supervisionato includono il clustering e la riduzione della dimensionalità.
Clustering

il Clustering è una senza supervisione tecnica che prevede il raggruppamento o il clustering, di punti di dati. Viene spesso utilizzato per la segmentazione dei clienti, il rilevamento delle frodi e la classificazione dei documenti.
Le tecniche comuni di clustering includono k-means clustering, hierarchical clustering, mean shift clustering e density-based clustering. Mentre ogni tecnica ha un metodo diverso nella ricerca di cluster, tutti mirano a ottenere la stessa cosa.
Riduzione della dimensionalità
La riduzione della dimensionalità è il processo di riduzione del numero di variabili casuali in esame ottenendo un insieme di variabili principali . In termini più semplici, è il processo di riduzione della dimensione del set di funzionalità (in termini ancora più semplici, riducendo il numero di funzionalità). La maggior parte delle tecniche di riduzione della dimensionalità può essere classificata come eliminazione o estrazione di funzionalità.
Un metodo popolare di riduzione della dimensionalità è chiamato analisi dei componenti principali.
Principal Component Analysis (PCA)
Nel senso più semplice, PCA coinvolge progetto dati dimensionali superiori (ad es. 3 dimensioni) ad uno spazio più piccolo(ad es. 2 dimensioni). Ciò si traduce in una dimensione inferiore dei dati, (2 dimensioni anziché 3 dimensioni) mantenendo tutte le variabili originali nel modello.
C’è un po ‘ di matematica coinvolta in questo. Se vuoi saperne di più
Dai un’occhiata a questo fantastico articolo su PCA qui.
Se preferisci guardare un video, StatQuest spiega PCA in 5 minuti qui.
Conclusione
Ovviamente, c’è un sacco di complessità se ti immergi in un particolare modello, ma questo dovrebbe darti una comprensione fondamentale di come funziona ogni algoritmo di apprendimento automatico!
Per più articoli come questo, check-out https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Intelligenza Artificiale: Un Approccio Moderno (2010), Prentice Hall
Roweis, S. T., Saul, L. K., Riduzione della dimensionalità non lineare mediante incorporamento localmente lineare (2000), Scienza