すべての機械学習モデルを6分で説明
最も人気のある機械学習モデルの直感的な説明。/div>
前回の記事では、回帰とは何かを説明し、アプリケーションでどのように使用できるかを示しました。 今週は、実際に使用されている一般的な機械学習モデルの大部分を説明するので、その背後にある理論を説明するのではなく、モデルの構築と改善に それに飛び込んでみましょう。Div>
すべての機械学習モデルは、教師ありまたは教師なしのいずれかに分類されます。 モデルが教師ありモデルの場合は、回帰モデルまたは分類モデルのいずれかとしてサブ分類されます。 これらの用語の意味と、以下の各カテゴリに分類される対応するモデルについて説明します。教師あり学習には、入力と出力のペアの例に基づいて入力を出力にマップする関数を学習することが含まれます。
教師あり学習には、入力と出力たとえば、年齢(入力)と身長(出力)の2つの変数を持つデータセットがある場合、教師あり学習モデルを実装して、年齢に基づいて人の身長を予測できます。Div>
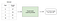
再反復するには、教師あり学習内には、回帰と分類の二つのサブカテゴリがあります。
回帰
回帰モデルでは、出力は連続しています。 以下は、回帰モデルの最も一般的なタイプのいくつかです。
線形回帰

線形回帰のアイデアは、単にデータに最も適した線を見つけることです。 線形回帰の拡張には、多重線形回帰(例えば、線形回帰)が含まれる。 最適な平面を見つける)および多項式回帰(例えば。 ベストフィットの曲線を見つける)。 線形回帰の詳細については、前回の記事で学ぶことができます。
決定ツリー
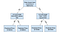
意思決定ツリーは、運用研究、戦略計画、および機械学習で使用される一般的なモデルです。 上記の各正方形はノードと呼ばれ、ノードが多いほど、決定ツリーは(一般的に)より正確になります。 決定が行われる決定木の最後のノードは、木の葉と呼ばれます。 意思決定ツリーは直感的で簡単に構築できますが、精度に関しては不足しています。
ランダムフォレスト
ランダムフォレストは、決定木から構築されるアンサンブル学習技術です。 ランダムフォレストでは、元のデータのブートストラップデータセットを使用して複数の決定木を作成し、決定木の各ステップで変数のサブセットを無 次に、モデルは、各決定木のすべての予測のモードを選択します。 これのポイントは何ですか? “多数決勝利”モデルに依存することにより、個々のツリーからのエラーのリスクを軽減します。/div>たとえば、1つの決定木、3つ目の決定木を作成した場合、0を予測します。 しかし、4つの決定木すべてのモードに依存している場合、予測値は1になります。 これはランダムな森林の力です。
StatQuestは、これをより詳細に歩いて素晴らしい仕事をしています。 ここを参照してください。P>
ニューラルネットワーク

ニューラルネットワークは本質的に数学的方程式のネットワークです。 これは、1つ以上の入力変数を取り、方程式のネットワークを通過することによって、1つ以上の出力変数が得られます。 また、ニューラルネットワークは入力のベクトルを取り込み、出力のベクトルを返すと言うこともできますが、この記事では行列には入りません。
青い円は入力レイヤーを表し、黒い円は非表示レイヤーを表し、緑の円は出力レイヤーを表します。 隠れ層の各ノードは、前の層のノードが通過する線形関数と活性化関数の両方を表し、最終的には緑色の円の出力につながります。あなたはそれについての詳細を学びたい場合は、ニューラルネットワーク上の私の初心者に優しい説明をチェックしてください。
分類
分類モデルでは、出力は離散です。 以下は、分類モデルの最も一般的なタイプのいくつかです。
ロジスティック回帰
ロジスティック回帰は線形回帰に似ていますが、有限数の結果、通常は二つの確率をモデル化するために使用されます。 結果の確率をモデル化するときに線形回帰よりもロジスティック回帰が使用される理由はいくつかあります(ここを参照)。 本質的に、ロジスティック方程式は、出力値が0と1の間にしかならないように作成されます(下記参照)。/div>サポートベクターマシン
サポートベクターマシンは、実際にはかなり複雑になることができますが、最も基本的なレベルではかなり直感的です教師
データには2つのクラスがあると仮定しましょう。 サポートベクターマシンは、2つのクラス間のマージンを最大化する超平面または2つのクラスのデータ間の境界を見つけます(下記参照)。 二つのクラスを分けることができる多くの平面がありますが、一つの平面だけがクラス間のマージンまたは距離を最大化することができます。div>バンはここでサポートベクターマシンに関する素晴らしい記事を書いた。
Naive Bayes
Naive Bayesは、データサイエンスで使用される別の一般的な分類器です。 その背後にあるアイデアは、ベイズの定理によって駆動されます:div>
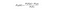
平易な英語では、この方程式は次のように使用されます次の質問に答えてください。 「Xが与えられたy(私の出力変数)の確率は何ですか? そして、クラスが与えられたときに変数が独立しているという素朴な仮定のために、あなたはそれを言うことができます:p>

同様に、分母を削除することにより、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々は、我々次に、P(y|X)は右辺に比例すると言うことができます。div>

したがって、目標は次のものを見つけることです。最大比例確率を持つクラスy。より詳細な説明が必要な場合は、私の記事「Naive Bayesの数学的説明」をチェックしてください!
決定木、ランダムフォレスト、ニューラルネットワーク
これらのモデルは、前に説明したのと同じロジックに従います。 唯一の違いは、その出力が連続的ではなく離散的であることです。
教師なし学習

iv id=”教師なし学習とは異なり、教師なし学習は、推論を描画し、ラベル付きの結果への参照なしで入力データからパターンを見つけるために使用されます。 教師なし学習で使用される2つの主な方法には、クラスタリングと次元削減があります。
クラスタリング

クラスタリングは、データポイントのグループ化またはクラスタリングを含む教師なし手法です。 これは、顧客のセグメンテーション、詐欺の検出、および文書の分類に頻繁に使用されます。
一般的なクラスタリング手法には、k平均クラスタリング、階層クラスタリング、平均シフトクラスタリング、密度ベースクラスタリングが含まれます。 それぞれの手法はクラスターを見つける方法が異なりますが、それらはすべて同じことを達成することを目指しています。
次元削減
次元削減は、主変数のセットを取得することによって検討中のランダム変数の数を減らすプロセスです。 簡単に言えば、機能セットの次元を減らすプロセスです(さらに簡単に言えば、機能の数を減らす)。 ほとんどの次元削減技術は、特徴除去または特徴抽出のいずれかとして分類することができる。
次元削減の一般的な方法は、主成分分析と呼ばれています。
主成分分析(PCA)
最も簡単な意味では、PCAはプロジェクトの高次元データ(例えば。 より小さいスペースへの3次元)(例えば。 2次元)。 これにより、元の変数をすべてモデルに保持しながら、データの次元が低くなります(3次元ではなく2次元)。これにはかなりの数学が関与しています。
これにはかなりの数学が関与しています。
なたはそれについての詳細を学びたい場合…
ここでPCA上のこの素晴らしい記事をチェックしてください。あなたはむしろビデオを見たい場合は、StatQuestはここで5分でPCAを説明しています。
結論
明らかに、特定のモデルに飛び込むと複雑さがたくさんありますが、これは各機械学習アルゴリズムがどのように機能するかを基本的に理解する必要があります!このようなより多くの記事については、チェックアウトhttps://blog.datatron.com/
Stuart J.Russell、Peter Norvig、Artificial Intelligence:A Modern Approach(2010)、Prentice Hall
Roweis、S.t.、ソール、l.k.,局所線形埋め込みによる非線形次元削減(2000),Science