alle maskinindlæringsmodeller forklaret på 6 minutter
Intuitive forklaringer på de mest populære maskinindlæringsmodeller.

i min tidligere artikel forklarede jeg, hvad regression var og viste, hvordan det kunne bruges i applikationen. I denne uge vil jeg gennemgå de fleste almindelige maskinindlæringsmodeller, der bruges i praksis, så jeg kan bruge mere tid på at opbygge og forbedre modeller i stedet for at forklare teorien bag den. Lad os dykke ned i det.

alle machine learning modeller er kategoriseret som enten overvåget eller uden opsyn. Hvis modellen er en overvåget model, er den derefter underkategoriseret som enten en regressions-eller klassificeringsmodel. Vi gennemgår, hvad disse udtryk betyder, og de tilsvarende modeller, der falder ind under hver kategori nedenfor.
overvåget læring indebærer at lære en funktion, der kortlægger et input til et output baseret på eksempel input-output par .
for eksempel, hvis jeg havde et datasæt med to variabler, alder (input) og højde (output), kunne jeg implementere en overvåget læringsmodel for at forudsige en persons højde baseret på deres alder.
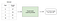
for at gentage, inden for overvåget læring, er der to underkategorier: regression og klassificering.
Regression
i regressionsmodeller er udgangen kontinuerlig. Nedenfor er nogle af de mest almindelige typer regressionsmodeller.
lineær Regression
div >
ideen om lineær regression er simpelthen at finde en linje, der bedst passer til dataene. Udvidelser af lineær regression inkluderer Multipel lineær regression (f.eks. at finde et plan med den bedste pasform) og polynomisk regression (f.eks. at finde en kurve med den bedste pasform). Du kan lære mere om lineær regression i min tidligere artikel.
beslutningstræ
>
beslutningstræer er en populær model, der anvendes i driftsforskning, strategisk planlægning og maskinindlæring. Hver firkant ovenfor kaldes en node, og jo flere noder du har, jo mere præcis bliver dit beslutningstræ (generelt). De sidste knudepunkter i beslutningstræet, hvor en beslutning træffes, kaldes træets blade. Beslutningstræer er intuitive og lette at bygge, men kommer til kort, når det kommer til nøjagtighed.
tilfældig Skov
tilfældige skove er en ensemblelæringsteknik, der bygger ud af beslutningstræer. Tilfældige skove involverer oprettelse af flere beslutningstræer ved hjælp af bootstrapped datasæt af de originale data og tilfældigt valg af en delmængde af variabler i hvert trin i beslutningstræet. Modellen vælger derefter tilstanden for alle forudsigelserne for hvert beslutningstræ. Hvad er meningen med dette? Ved at stole på en” flertalsvinder ” – model reducerer det risikoen for fejl fra et individuelt træ.

for eksempel, hvis vi oprettede et beslutningstræ, det tredje, ville det forudsige 0. Men hvis vi stolede på tilstanden for alle 4 beslutningstræer, ville den forudsagte værdi være 1. Dette er kraften i tilfældige skove.
status gør et fantastisk stykke arbejde med at gå gennem dette mere detaljeret. Se her.
neuralt netværk

et neuralt netværk er i det væsentlige et netværk af matematiske ligninger. Det tager en eller flere inputvariabler, og ved at gå gennem et netværk af ligninger resulterer det i en eller flere outputvariabler. Du kan også sige, at et neuralt netværk tager en vektor af input og returnerer en vektor af output, men jeg kommer ikke ind i matricer i denne artikel.
de blå cirkler repræsenterer inputlaget, de sorte cirkler repræsenterer de skjulte lag, og de grønne cirkler repræsenterer outputlaget. Hver knude i de skjulte lag repræsenterer både en lineær funktion og en aktiveringsfunktion, som knudepunkterne i det foregående lag gennemgår, hvilket i sidste ende fører til et output i de grønne cirkler.
- hvis du gerne vil lære mere om det, så tjek min begyndervenlige forklaring på neurale netværk.
klassificering
i klassificeringsmodeller er udgangen diskret. Nedenfor er nogle af de mest almindelige typer klassificeringsmodeller.
logistisk Regression
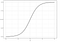
logistisk regression svarer til lineær regression, men bruges til at modellere sandsynligheden for et endeligt antal resultater, typisk to. Der er en række grunde til, at logistisk regression bruges over lineær regression, når man modellerer sandsynligheder for resultater (Se her). I det væsentlige oprettes en logistisk ligning på en sådan måde, at outputværdierne kun kan være mellem 0 og 1 (se nedenfor).
Support Vector Machine
en supportvektormaskine er en overvåget klassificeringsteknik, der faktisk kan blive ret kompliceret, men er temmelig intuitiv på det mest grundlæggende niveau.
lad os antage, at der er to klasser af data. En støttevektormaskine finder en hyperplan eller en grænse mellem de to klasser af data, der maksimerer margenen mellem de to klasser (se nedenfor). Der er mange fly, der kan adskille de to klasser, men kun et plan kan maksimere margenen eller afstanden mellem klasserne.

Hvis du vil komme nærmere ind på, skrev Savan en fantastisk artikel om supportvektormaskiner her.
Naive Bayes
Naive Bayes er en anden populær klassifikator, der anvendes i datalogi. Ideen bag den er drevet af Bayes sætning:
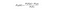
på almindeligt engelsk bruges denne ligning til at besvare følgende spørgsmål. “Hvad er sandsynligheden for y (min outputvariabel) givet? Og på grund af den naive antagelse om, at variabler er uafhængige i betragtning af klassen, kan du sige det:

Ved at fjerne nævneren kan vi så sige, at p(y / h) er proportional med højre side.

derfor er målet at finde klassen y med den maksimale proportionale sandsynlighed.
tjek min artikel” en matematisk forklaring af Naive Bayes”, hvis du vil have en mere dybdegående forklaring!
beslutningstræ, tilfældig Skov, neuralt netværk
disse modeller følger den samme logik som tidligere forklaret. Den eneste forskel er, at denne output er diskret snarere end kontinuerlig.
uovervåget læring
i modsætning til overvåget læring bruges uovervåget læring til at tegne slutninger og finde mønstre fra inputdata uden henvisninger til mærkede resultater. To hovedmetoder, der anvendes i uovervåget læring, omfatter klyngedannelse og dimensionalitetsreduktion.
Clustering
klyngedannelse er en uovervåget teknik, der involverer gruppering eller klyngedannelse af datapunkter. Det bruges ofte til kundesegmentering, afsløring af svig og klassificering af dokumenter.
almindelige klyngeteknikker inkluderer K-betyder klyngedannelse, hierarkisk klyngedannelse, gennemsnitlig skiftklyngedannelse og tæthedsbaseret klyngedannelse. Mens hver teknik har en anden metode til at finde klynger, sigter de alle mod at opnå det samme.
Dimensionalitetsreduktion
Dimensionalitetsreduktion er processen med at reducere antallet af tilfældige variabler under overvejelse ved at opnå et sæt hovedvariabler . I enklere termer er det processen med at reducere dimensionen af dit funktionssæt (i endnu enklere termer, hvilket reducerer antallet af funktioner). De fleste dimensionalitetsreduktionsteknikker kan kategoriseres som enten funktionsekstraktion eller funktionsekstraktion.
en populær metode til dimensionalitetsreduktion kaldes hovedkomponentanalyse.
Principal Component Analysis (PCA)
i den enkleste forstand involverer PCA projektdata med højere dimension (f.eks. 3 dimensioner) til et mindre rum (f.eks. 2 dimensioner). Dette resulterer i en lavere dimension af data (2 dimensioner i stedet for 3 dimensioner), mens alle originale variabler i modellen bevares.
der er en hel del matematik involveret i dette. Hvis du vil lære mere om det…
Tjek denne fantastiske artikel om PCA her.
Hvis du hellere vil se en video, forklarer statements PCA om 5 minutter her.
konklusion
der er naturligvis masser af kompleksitet, hvis du dykker ned i en bestemt model, men dette skal give dig en grundlæggende forståelse af, hvordan hver maskinlæringsalgoritme fungerer!
For Flere artikler som denne, tjek https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, kunstig intelligens: en moderne tilgang (2010), Prentice Hall
S. T., Saul, L. K., Ikke-lineær Dimensionalitetsreduktion ved lokalt lineær indlejring (2000), videnskab