nedsmeltning og Spectre, forklaret
selvom jeg i disse dage mest er kendt for netværk på applikationsniveau og distribuerede systemer, tilbragte jeg den første del af min karriere med at arbejde med operativsystemer og hypervisorer. Jeg opretholder en dyb fascination af de lave detaljer om, hvordan moderne processorer og systemprogrammer fungerer. Da den nylige nedsmeltning og Spectre-sårbarheder blev annonceret, Jeg gravede ind i de tilgængelige oplysninger og var ivrig efter at lære mere.
sårbarhederne er forbløffende; Jeg vil hævde, at de er en af de vigtigste opdagelser inden for datalogi i de sidste 10-20 år. Afbødningerne er også vanskelige at forstå, og nøjagtige oplysninger om dem er svære at finde. Dette er ikke overraskende i betragtning af deres kritiske karakter. Afbødning af sårbarhederne har krævet måneder med hemmelighedsfuldt arbejde af alle de store CPU -, Operativsystem-og cloud-leverandører. Det faktum, at problemerne blev holdt under omslag i 6 måneder, hvor bogstaveligt talt hundreder af mennesker sandsynligvis arbejdede på dem, er forbløffende.
selvom der er skrevet meget om nedsmeltning og Spectre siden deres meddelelse, har jeg ikke set en god introduktion på mellemniveau til sårbarhederne og afbødningerne. I dette indlæg vil jeg forsøge at rette op på det ved at give en blid introduktion til den udstyrs-og programbaggrund, der kræves for at forstå sårbarhederne, en diskussion af sårbarhederne selv, samt en diskussion af de aktuelle afbødninger.
vigtig note: fordi jeg ikke har arbejdet direkte på afbødningerne og ikke arbejder hos Intel, Microsoft, Google,
i dette afsnit vil jeg give nogle baggrund kræves for at forstå sårbarhederne. Afsnittet dækker over en stor mængde detaljer og er rettet mod læsere med en begrænset forståelse af computerudstyr og systemprogrammer.
virtuel hukommelse
virtuel hukommelse er en teknik, der bruges af alle operativsystemer siden 1970 ‘ erne. Det giver et lag af abstraktion mellem hukommelsesadresselayoutet, som de fleste programmer ser, og de fysiske enheder, der understøtter den hukommelse (RAM, diske osv.). På et højt niveau giver det applikationer mulighed for at bruge mere hukommelse, end maskinen faktisk har; dette giver en kraftig abstraktion, der gør mange programmeringsopgaver lettere.

figur 1 viser en forenklet computer med 400 bytes hukommelse lagt ud i “sider” på 100 bytes (rigtige computere bruger kræfter på to, typisk 4096). Computeren har to processer, hver med 200 bytes hukommelse på 2 sider hver. Processerne kører muligvis den samme kode ved hjælp af faste adresser i 0-199 byte-området, men de understøttes af diskret fysisk hukommelse, så de ikke påvirker hinanden. Selvom moderne operativsystemer og computere bruger virtuel hukommelse på en væsentligt mere kompliceret måde end hvad der præsenteres i dette eksempel, gælder den grundlæggende forudsætning, der er præsenteret ovenfor, i alle tilfælde. Operativsystemer abstraherer de adresser, som applikationen ser fra de fysiske ressourcer, der understøtter dem.
oversættelse af virtuelle til fysiske adresser er en så almindelig operation i moderne computere, at hvis operativsystemet skulle være involveret i alle tilfælde, ville computeren være utrolig langsom. Moderne CPU-udstyr giver en enhed kaldet en oversættelse Lookaside Buffer (TLB), der cacher nyligt anvendte kortlægninger. Dette gør det muligt for CPU ‘ er at udføre adresseoversættelse direkte i udstyr det meste af tiden.
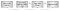
figur 2 viser adresseoversættelsesstrømmen:
- et program henter en virtuel adresse.
- CPU ‘ en forsøger at oversætte den ved hjælp af TLB. Hvis adressen findes, bruges oversættelsen.
- hvis adressen ikke findes, konsulterer CPU ‘ en et sæt “sidetabeller” for at bestemme kortlægningen. Sidetabeller er et sæt fysiske hukommelsessider, der leveres af operativsystemet et sted, hvor udstyret kan finde dem (f.eks. Sidetabeller kortlægger virtuelle adresser til fysiske adresser og indeholder også metadata såsom tilladelser.
- hvis sidetabellen indeholder en kortlægning, returneres den, cachelagres i TLB ‘ en og bruges til opslag. Hvis sidetabellen ikke indeholder en kortlægning, hæves en” sidefejl ” til operativsystemet. En sidefejl er en særlig form for afbrydelse, der gør det muligt for operativsystemet at tage kontrol og bestemme, hvad der skal gøres, når der mangler eller ugyldig kortlægning. For eksempel kan operativsystemet afslutte programmet. Det kan også tildele nogle fysiske hukommelse og kortlægge det i processen. Hvis en sidefejlbehandler fortsætter udførelsen, vil den nye kortlægning blive brugt af TLB.

figur 3 viser et lidt mere realistisk billede af, hvordan virtuel hukommelse ser ud i en moderne computer (pre-nedsmeltning — mere om dette nedenfor). I denne opsætning har vi følgende funktioner:
- Kernelhukommelse vises med rødt. Det er indeholdt i fysisk adresseområde 0-99. Kernelhukommelse er speciel hukommelse, som kun operativsystemet skal have adgang til. Brugerprogrammer bør ikke kunne få adgang til det.
- brugerhukommelse vises i gråt.
- ikke-allokeret fysisk hukommelse vises med blåt.
i dette eksempel begynder vi at se nogle af de nyttige funktioner i virtuel hukommelse. Primært:
- brugerhukommelse i hver proces er i det virtuelle interval 0-99, men bakkes op af forskellige fysiske hukommelse.
- Kernelhukommelse i hver proces er i det virtuelle interval 100-199, men bakket op af den samme fysiske hukommelse.
som jeg kort nævnt i det foregående afsnit, har hver side tilknyttede tilladelsesbit. Selvom kernehukommelse er kortlagt i hver brugerproces, når processen kører i brugertilstand, kan den ikke få adgang til kernehukommelsen. Hvis en proces forsøger at gøre det, vil det udløse en sidefejl, på hvilket tidspunkt operativsystemet afslutter det. Men når processen kører i kernetilstand (for eksempel under et systemopkald), tillader processoren adgangen.
på dette tidspunkt vil jeg bemærke, at denne type dobbelt kortlægning (hver proces, der har kernen kortlagt direkte i den) har været standardpraksis i operativsystemdesign i over tredive år af ydeevneårsager (systemopkald er meget almindelige, og det ville tage lang tid at omforme kernen eller brugerrummet ved hver overgang).
CPU cache topologi
figur 4: CPU tråd, kerne, pakke og cache topologi.
det næste stykke baggrundsinformation, der kræves for at forstå sårbarhederne, er CPU og cache-topologi for moderne processorer. Figur 4 viser en generisk topologi, der er fælles for de fleste moderne CPU ‘ er. Den består af følgende komponenter:
- den grundlæggende enhed for udførelse er “CPU-tråden” eller “maskintråd” eller “hyper-tråd.”Hver CPU-tråd indeholder et sæt registre og evnen til at udføre en strøm af maskinkode, ligesom en programtråd.
- CPU-tråde er indeholdt i en “CPU-kerne.”De fleste moderne CPU’ er indeholder to tråde pr.
- moderne CPU ‘ er indeholder generelt flere niveauer af cachehukommelse. Cache-niveauerne tættere på CPU-tråden er mindre, hurtigere og dyrere. Jo længere væk fra CPU ‘ en og tættere på hovedhukommelsen cachen er, jo større, langsommere og billigere er den.
- typisk moderne CPU-design bruger en L1 / L2-cache pr. Det betyder, at hver CPU tråd på kernen gør brug af de samme caches.
- flere CPU-kerner er indeholdt i en “CPU-pakke.”Moderne CPU’ er kan indeholde op til 30 kerner (60 tråde) eller mere pr.
- alle CPU-kernerne i pakken deler typisk en L3-cache.
- CPU-pakker passer ind i ” stikkontakter.”De fleste forbrugercomputere er single socket, mens mange datacenter-servere har flere stikkontakter.
spekulativ udførelse

det sidste stykke baggrundsinformation, der kræves for at forstå sårbarhederne, er en moderne CPU-teknik kendt som “spekulativ udførelse.”Figur 5 viser et generisk diagram over eksekveringsmotoren inde i en moderne CPU.
den primære afhentning er, at moderne CPU ‘ er er utroligt komplicerede og ikke blot udfører maskininstruktioner i rækkefølge. Hver CPU-tråd har en kompliceret rørledningsmotor, der er i stand til at udføre instruktioner ude af drift. Årsagen til dette har at gøre med caching. Som jeg diskuterede i det foregående afsnit, bruger hver CPU flere niveauer af caching. Hver cache-miss tilføjer en betydelig delay-tid til programudførelse. For at afbøde dette er processorer i stand til at udføre fremad og ude af drift, mens de venter på hukommelsesbelastninger. Dette er kendt som spekulativ udførelse. Følgende kodestykke viser dette.
if (x < array1_size) {
y = array2 * 256];
}
forestil dig, atarray1_size ikke er tilgængelig i cache, men adressen tilarray1 er. CPU ‘ en kan gætte (spekulere), at x er mindre end array1_size og gå videre og udfør beregningerne inde i if-sætningen. Når array1_size læses fra hukommelsen, kan CPU ‘ en bestemme, om den gættede korrekt. Hvis det gjorde det, kan det fortsætte med at have sparet en masse tid. Hvis det ikke gjorde det, kan det smide de spekulative beregninger og starte forfra. Dette er ikke værre, end hvis det havde ventet i første omgang.
en anden type spekulativ udførelse er kendt som indirekte gren forudsigelse. Dette er ekstremt almindeligt i moderne programmer på grund af virtuel forsendelse.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(kilden til det forrige uddrag er dette indlæg)
den måde, hvorpå det forrige uddrag implementeres i maskinkode, er at indlæse “v-table” eller “virtual dispatch table” fra hukommelsesplaceringen, somobj peger på og derefter kalder det. Fordi denne operation er så almindelig, har moderne CPU ‘ er forskellige interne caches og vil ofte gætte (spekulere), hvor den indirekte gren vil gå og fortsætte udførelsen på det tidspunkt. Igen, hvis CPU ‘ en gætter korrekt, kan den fortsætte med at have sparet en masse tid. Hvis det ikke gjorde det, kan det smide de spekulative beregninger og starte forfra.
nedsmeltningssårbarhed
Når vi nu har dækket alle baggrundsoplysningerne, kan vi dykke ned i sårbarhederne.
Rogue data cache load
den første sårbarhed, kendt som nedsmeltning, er overraskende enkel at forklare og næsten triviel at udnytte. Udnyttelseskoden ser stort set ud som følgende:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
lad os tage hvert trin ovenfor, beskrive hvad det gør, og hvordan det fører til at kunne læse hukommelsen på hele computeren fra et brugerprogram.
- i den første linje tildeles et “probe array”. Dette er hukommelse i vores proces, der bruges som en sidekanal til at hente data fra kernen. Hvordan dette gøres, vil snart blive tydeligt.
- efter tildelingen sørger angriberen for, at ingen af hukommelsen i probearrayet er cachelagret. Der er forskellige måder at opnå dette på, hvoraf den enkleste inkluderer CPU-specifikke instruktioner til at rydde en hukommelsesplacering fra cache.
- angriberen fortsætter derefter med at læse en byte fra kernens adresserum. Husk fra vores tidligere diskussion om virtuel hukommelse og sidetabeller, at alle moderne kerner typisk kortlægger hele kernens virtuelle adresserum i brugerprocessen. Operativsystemer er afhængige af, at hver sidetabelindgang har tilladelsesindstillinger, og at brugertilstandsprogrammer ikke har adgang til kernehukommelse. Enhver sådan adgang vil resultere i en sidefejl. Det er faktisk, hvad der i sidste ende vil ske i trin 3.
- moderne processorer udfører imidlertid også spekulativ udførelse og vil udføre forud for fejlinstruktionen. Således kan trin 3-5 udføres i CPU ‘ ens rørledning, før fejlen hæves. I dette trin multipliceres byten af kernehukommelse (som varierer fra 0-255) med systemets sidestørrelse, som typisk er 4096.
- i dette trin bruges den multiplicerede byte af kernehukommelse derefter til at læse fra sondearrayet til en dummy-værdi. Multiplikationen af byte med 4096 er at undgå en CPU-funktion kaldet “prefetcher” fra at læse flere data, end vi ønsker i cachen.
- ved dette trin har CPU ‘ en indset sin fejl og rullet tilbage til trin 3. Resultaterne af de spekulerede instruktioner er dog stadig synlige i cache. Angriberen bruger operativsystemfunktionalitet til at fange den fejlagtige instruktion og fortsætte udførelsen (f.eks.
- i trin 7 gentager angriberen sig og ser, hvor lang tid det tager at læse hver af de 256 mulige bytes i sondearrayet, der kunne have været indekseret af kernehukommelsen. CPU ‘ en har indlæst en af placeringerne i cachen, og denne placering indlæses væsentligt hurtigere end alle de andre placeringer (som skal læses fra hovedhukommelsen). Denne placering er værdien af byte i kernehukommelsen.
Ved hjælp af ovenstående teknik og det faktum, at det er standardpraksis for moderne operativsystemer at kortlægge al fysisk hukommelse i kernens virtuelle adresserum, kan en angriber læse hele computerens fysiske hukommelse.
nu undrer du dig måske: “du sagde, at sidetabeller har tilladelsesbit. Hvordan kan det være, at brugertilstandskoden var i stand til spekulativt at få adgang til kernehukommelse?”Årsagen er, at dette er en fejl i Intel-processorer. Efter min mening er der ingen god grund, ydeevne eller på anden måde, for at dette er muligt. Husk, at al virtuel hukommelsesadgang skal ske via TLB. Det er let muligt under spekulativ udførelse at kontrollere, at en cachelagret kortlægning har tilladelser, der er kompatible med det aktuelle kørende privilegieniveau. Intel gør det simpelthen ikke. Andre processorleverandører udfører en tilladelseskontrol og blokerer spekulativ udførelse. Så vidt vi ved, er nedsmeltning således en Intel-sårbarhed.
Rediger: det ser ud til, at mindst en ARM-processor også er modtagelig for nedsmeltning som angivet her og her.
nedsmeltningsbegrænsninger
nedsmeltning er let at forstå, trivielt at udnytte og har heldigvis også en relativt ligetil afbødning (i det mindste konceptuelt — kerneludviklere er muligvis ikke enige om, at det er ligetil at implementere).
kernel page table isolation (KPTI)
Husk at i afsnittet om virtuel hukommelse beskrev jeg, at alle moderne operativsystemer bruger en teknik, hvor kernelhukommelse er kortlagt i hver brugertilstandsproces virtuel hukommelsesadresserum. Dette er for både ydeevne og enkelhed grunde. Det betyder, at når ET program foretager et systemopkald, er kernen klar til brug uden yderligere arbejde. Løsningen til nedsmeltning er ikke længere at udføre denne dobbelte kortlægning.

figur 6 viser en teknik kaldet kernel page Table isolation (kpti). Dette koger dybest set ned til ikke at kortlægge kernehukommelse til et program, når det kører i brugerrummet. Hvis der ikke er nogen kortlægning til stede, er spekulativ udførelse ikke længere mulig og vil straks fejle.
ud over at gøre operativsystemets virtual memory manager (VMM) mere kompliceret, vil denne teknik også betydeligt sænke arbejdsbyrden, der gør et stort antal brugertilstand til kernemodusovergange på grund af det faktum, at sidetabellerne skal ændres ved hver overgang, og TLB skal skylles (da TLB kan holde fast i forældede kortlægninger).86 CPU ‘ er har en funktion kendt som ASID (address space ID) eller PCID (process kontekst ID), der kan bruges til at gøre denne opgave væsentligt billigere (ARM og andre mikroarkitekturer har haft denne funktion i årevis). PCID tillader, at et ID knyttes til en TLB-post og derefter kun skylle TLB-poster med det ID. Brugen af PCID gør KPTI billigere, men stadig ikke gratis.
Sammenfattende er nedsmeltning en ekstremt alvorlig og let at udnytte sårbarhed. Heldigvis har det en relativt ligetil afbødning, der allerede er implementeret af alle større OS-leverandører, advarslen er, at visse arbejdsbelastninger vil køre langsommere, indtil fremtidig udstyr eksplicit er designet til den beskrevne adresserumseparation.
Spectre sårbarhed
Spectre deler nogle egenskaber ved nedsmeltning og består af to varianter. I modsætning til nedsmeltning er Spectre væsentligt sværere at udnytte, men påvirker næsten alle moderne processorer produceret i de sidste tyve år. I det væsentlige er Spectre et angreb mod moderne CPU-og operativsystemdesign versus en specifik sikkerhedssårbarhed.
Bounds check bypass (Spectre variant 1)
den første Spectre variant er kendt som “bounds check bypass.”Dette demonstreres i følgende kodestykke (som er det samme kodestykke, jeg brugte til at introducere spekulativ udførelse ovenfor).
if (x < array1_size) {
y = array2 * 256];
}
i det foregående eksempel antager du følgende rækkefølge af begivenheder:
- angriberen kontrollerer
x. -
array1_sizeer ikke cachelagret. -
array1er cachelagret. - CPU ‘ en gætter på, at
xer mindre endarray1_size. (CPU ‘ er anvender forskellige proprietære algoritmer og heuristik for at afgøre, om de skal spekulere, hvorfor angrebsdetaljer for Spectre varierer mellem processorleverandører og modeller.) - CPU ‘ en udfører kroppen af if-sætningen, mens den venter på
array1_sizefor at indlæse, hvilket påvirker cachen på samme måde som nedsmeltning. - angriberen kan derefter bestemme den faktiske værdi af
array1via en af forskellige metoder. (Se forskning papir for flere detaljer om cache inferens angreb.)
Spectre er betydeligt vanskeligere at udnytte end nedsmeltning, fordi denne sårbarhed ikke afhænger af rettighedsforøgelse. Angriberen skal overbevise kernen om at køre kode og spekulere forkert. Typisk skal angriberen forgifte spekulationsmotoren og narre den til at gætte forkert. Når det er sagt, har forskere vist flere proof-of-concept udnyttelser.
Jeg vil gerne gentage, hvad en virkelig utrolig finde denne udnytte er. Jeg betragter ikke personligt dette som en CPU-designfejl som nedsmeltning i sig selv. Jeg betragter dette som en grundlæggende åbenbaring om, hvordan moderne udstyr og programmer fungerer sammen. Det faktum, at CPU-cacher kan bruges indirekte til at lære om adgangsmønstre, har været kendt i nogen tid. Det faktum, at CPU-cacher kan bruges som en sidekanal til at dumpe computerhukommelse, er forbløffende, både konceptuelt og i dens implikationer.
Branch target injection (Spectre variant 2)
Husk at indirekte forgrening er meget almindelig i moderne programmer. Variant 2 af Spectre bruger indirekte grenforudsigelse til at forgifte CPU ‘ en til spekulativt udførelse til en hukommelsesplacering, som den ellers aldrig ville have udført. Hvis udførelse af disse instruktioner kan efterlade tilstand i cachen, der kan detekteres ved hjælp af cache inference-angreb, kan angriberen derefter dumpe hele kernehukommelsen. Ligesom Spectre-variant 1 er Spectre-variant 2 meget sværere at udnytte end nedsmeltning, men forskere har demonstreret fungerende proof-of-concept-udnyttelse af variant 2.
Spectre-afbødninger
Spectre-afbødningerne er væsentligt mere interessante end nedsmeltningen. Faktisk skriver academic Spectre-papiret, at der i øjeblikket ikke er nogen kendte afbødninger. Det ser ud til, at Intel (og sandsynligvis andre CPU-leverandører) og de store OS-og cloud-leverandører bag kulisserne og parallelt med det akademiske arbejde har arbejdet rasende i flere måneder for at udvikle afbødninger. I dette afsnit vil jeg dække de forskellige afbødninger, der er udviklet og implementeret. Dette er det afsnit, jeg er mest uklar på, da det er utroligt vanskeligt at få nøjagtige oplysninger, så jeg samler ting fra forskellige kilder.
statisk analyse og hegn (variant 1 afbødning)
den eneste kendte variant 1 (bounds check bypass) afbødning er statisk analyse af kode for at bestemme kodesekvenser, der kan være angriberen kontrolleret for at forstyrre spekulation. Sårbare kodesekvenser kan have en serialiserende instruktion som lfence indsat, som stopper spekulativ udførelse, indtil alle instruktioner op til hegnet er udført. Der skal udvises forsigtighed, når du indsætter hegninstruktioner, da for mange kan have alvorlige ydeevnepåvirkninger.
Retpoline (variant 2 mitigation)
den første Spectre variant 2 (branch target injection) mitigation blev udviklet af Google og er kendt som “retpoline.”Det er uklart for mig, om det blev udviklet isoleret af Google eller af Google i samarbejde med Intel. Jeg ville spekulere i, at det blev eksperimentelt udviklet af Google og derefter verificeret af Intel-Maskiningeniører, men jeg er ikke sikker. Detaljer om” retpoline ” – tilgangen findes i Googles papir om emnet. Jeg vil opsummere dem her (jeg gloser over nogle detaljer, herunder understrøm, der er dækket af papiret).
Retpoline er afhængig af, at opkald og retur fra funktioner og de tilhørende stakmanipulationer er så almindelige i computerprogrammer, at CPU ‘ er er stærkt optimeret til at udføre dem. (Hvis du ikke er bekendt med, hvordan stakken fungerer i forhold til at ringe og vende tilbage fra funktioner, er dette indlæg en god primer.) I en nøddeskal, når et “opkald” udføres, skubbes returadressen på stakken. “ret” popper returadressen fra og fortsætter udførelsen. Spekulativt eksekveringsudstyr vil huske den skubbede returadresse og spekulativt fortsætte udførelsen på det tidspunkt.
retpoline-konstruktionen erstatter et indirekte Spring til hukommelsesplaceringen gemt i register r11:
jmp *%r11
med:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
lad os se, hvad den forrige samlingskode gør et trin ad gangen, og hvordan det mindsker grenmålinjektion.
- i dette trin kalder koden en hukommelsesplacering, der er kendt på kompileringstidspunktet, så det er en hård kodet forskydning og ikke indirekte. Dette placerer returadressen til
capture_specpå stakken. - returadressen fra opkaldet overskrives med det faktiske springmål.
- et afkast udføres på det virkelige mål.
- når CPU ‘ en spekulativt udfører, vender den tilbage til en uendelig løkke! Husk, at CPU ‘ en vil spekulere fremad, indtil hukommelsesbelastningen er færdig. I dette tilfælde er spekulationen blevet manipuleret til at blive fanget i en uendelig løkke, der ikke har nogen bivirkninger, der kan observeres for en angriber. Når CPU ‘ en til sidst udfører det reelle afkast, vil det afbryde den spekulative udførelse, som ikke havde nogen effekt.
efter min mening er dette en virkelig genial afbødning. Kudos til de ingeniører, der udviklede det. Ulempen ved denne afbødning er, at det kræver, at alle programmer skal kompileres igen, således at indirekte grene konverteres til retpoline-grene. For skytjenester som Google, der ejer hele stakken, er genkompilering ikke en big deal. For andre, det kan være en meget big deal eller umuligt.
IBRS, STIBP og IBPB (variant 2 mitigation)
det ser ud til, at Intel (og AMD til en vis grad) sammen med retpoline-udviklingen har arbejdet rasende på ændringer i udstyr for at afbøde angreb på grenmålinjektion. De tre nye udstyrsfunktioner, der sendes som CPU-mikrokodeopdateringer, er:
- indirekte gren begrænset spekulation (Ibrs)
- enkelt tråd indirekte gren prædiktorer (STIBP)
- indirekte gren prædiktor barriere (IBPB)
begrænset information om de nye mikrokode funktioner er tilgængelige fra Intel her. Jeg har været i stand til groft at dele sammen, hvad disse nye funktioner gør ved at læse ovenstående dokumentation og se på hypervisor patches. Fra min analyse bruges hver funktion potentielt som følger:
- IBRS både skyller gren forudsigelse cache mellem privilegium niveauer (bruger til kerne) og deaktiverer gren forudsigelse på søskende CPU tråd. Husk, at hver CPU-kerne typisk har to CPU-tråde. Det ser ud til, at på moderne CPU ‘ er deles grenforudsigelsesudstyret mellem trådene. Dette betyder, at ikke kun brugertilstandskode kan forgifte grenprædiktoren inden indtastning af kernekode, kode, der kører på søskende CPU-tråden, kan også forgifte den. Aktivering af ibrs i kernetilstand forhindrer i det væsentlige enhver tidligere udførelse i brugertilstand og enhver udførelse på søskende CPU-tråden i at påvirke grenforudsigelsen.
- STIBP ser ud til at være en delmængde af IBRS, der bare deaktiverer grenforudsigelse på søskende CPU-tråden. Så vidt jeg kan fortælle, er den vigtigste brugssag for denne funktion at forhindre en søskende CPU-tråd i at forgifte grenprædiktoren, når du kører to forskellige brugertilstandsprocesser (eller virtuelle maskiner) på samme CPU-kerne på samme tid. Det er ærligt ikke helt klart for mig lige nu, når STIBP skal bruges.
- IBPB ser ud til at skylle grenforudsigelsescachen for kode, der kører på samme privilegieniveau. Dette kan bruges, når du skifter mellem to brugertilstandsprogrammer eller to virtuelle maskiner for at sikre, at den forrige kode ikke forstyrrer den kode, der er ved at køre (dog uden STIBP tror jeg, at kode, der kører på søskende CPU-tråden, stadig kan forgifte grenprædiktoren).
fra denne skrivning synes de vigtigste afbødninger, som jeg ser implementeret for filialmålinjektionssårbarheden, at være både retpoline og ibrs. Formentlig er dette den hurtigste måde at beskytte kernen mod brugertilstandsprogrammer eller hypervisoren fra virtuelle maskingæster. I fremtiden ville jeg forvente, at både STIBP og IBPB vil blive implementeret afhængigt af paranoia-niveauet for forskellige brugertilstandsprogrammer, der forstyrrer hinanden.
omkostningerne ved ibrs ser også ud til at variere ekstremt meget mellem CPU-arkitekturer, hvor nyere Intel Skylake-processorer er relativt billige sammenlignet med ældre processorer. 20% afmatning på visse systemopkald tunge arbejdsbyrder på Av C4-tilfælde, hvor afbødningerne blev rullet ud. Jeg ville spekulere i, at
Over tid forventer jeg, at processorer til sidst flytter til en ibrs “altid på” – model, hvor udstyret bare er standard for ren grenforudsigelsesadskillelse mellem CPU-tråde og korrekt skyller tilstand på ændringer i privilegieniveau. Den eneste grund til, at dette ikke ville ske i dag, er de tilsyneladende ydelsesomkostninger ved eftermontering af denne funktionalitet på allerede frigivne mikroarkitekturer via mikrokodeopdateringer.
konklusion
det er meget sjældent, at et forskningsresultat grundlæggende ændrer, hvordan computere bygges og køres. Nedsmeltning og Spectre har gjort netop det. Disse resultater vil ændre udstyrs-og programmeldesign væsentligt i løbet af de næste 7-10 år (den næste CPU-maskincyklus), da designere tager højde for den nye virkelighed af mulighederne for datalækage via cache-sidekanaler.
i mellemtiden vil Nedsmeltnings-og Spectre-fundene og tilhørende afbødninger have betydelige konsekvenser for computerbrugere i de kommende år. På kort sigt vil afbødningerne have en ydeevnepåvirkning, der kan være betydelig afhængigt af arbejdsbyrden og det specifikke udstyr. Dette kan nødvendiggøre operationelle ændringer for nogle infrastrukturer (for eksempel flytter vi aggressivt nogle arbejdsbelastninger til AV C5-tilfælde på grund af det faktum, at Ibrs ser ud til at køre væsentligt hurtigere på Skylake-processorer, og den nye Nitro hypervisor leverer afbrydelser direkte til gæster, der bruger SR-Iov og APICv, og fjerner mange virtuelle maskinudgange til io-tunge arbejdsbelastninger). Stationære computerbrugere er heller ikke immune på grund af proof-of-concept-angreb ved hjælp af JavaScript, som OS og bro.ser-leverandører arbejder på at afbøde. På grund af sårbarhedernes kompleksitet er det næsten sikkert, at sikkerhedsforskere vil finde nye udnyttelser, der ikke er dækket af de nuværende afbødninger, der skal patches.
selvom jeg elsker at arbejde hos Lyft og føler, at det arbejde, vi laver i microservice systems infrastructure space, er noget af det mest effektive arbejde, der udføres i branchen lige nu, får begivenheder som dette mig til at savne at arbejde på operativsystemer og hypervisorer. Jeg er meget misundelig på det heroiske arbejde, der blev udført i løbet af de sidste seks måneder af et stort antal mennesker med at undersøge og afbøde sårbarhederne. Jeg ville have elsket at have været en del af det!
yderligere læsning
- nedsmeltning og Spectre akademiske papirer:https://spectreattack.com/
- Google-projekt nul blogindlæg:https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Intel Spectre-udstyrsbegrænsninger:https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- retpoline blogindlæg:https://support.google.com/faqs/answer/7625886
- god oversigt over kendte oplysninger:https://github.com/marcan/speculation-bugs/blob/master/README.md