Aprendizaje Profundo para Detectar la Neumonía de Imágenes de rayos X
Un extremo a extremo de la tubería para la neumonía de detección de imágenes de rayos X
quedó detrás de la paywall? Haz clic aquí para la continuación de la historia con mi amigo Link!
El riesgo de neumonía es inmenso para muchos, especialmente en los países en desarrollo, donde miles de millones de personas se enfrentan a la pobreza energética y dependen de formas de energía contaminantes. La OMS estima que anualmente se producen más de 4 millones de muertes prematuras por enfermedades relacionadas con la contaminación del aire en el hogar, incluida la neumonía. Más de 150 millones de personas se infectan con neumonía anualmente, especialmente niños menores de 5 años. En esas regiones, el problema puede agravarse aún más debido a la escasez de recursos y personal médicos. Por ejemplo, en las 57 naciones de África, existe una brecha de 2,3 millones de médicos y enfermeras. Para estas poblaciones, el diagnóstico preciso y rápido lo significa todo. Puede garantizar el acceso oportuno al tratamiento y ahorrar el tiempo y el dinero que tanto necesitan las personas que ya viven en la pobreza.
Este proyecto forma parte de las Imágenes Radiográficas de Tórax (Neumonía) que se toman en Kaggle.
Cree un algoritmo para identificar automáticamente si un paciente sufre de neumonía o no al observar imágenes de rayos X de tórax. El algoritmo tenía que ser extremadamente preciso porque la vida de las personas está en juego.
Entorno y las herramientas
- scikit-learn
- keras
- colección
- los pandas
- matplotlib
Datos
El conjunto de datos puede ser descargado desde el kaggle sitio web que se puede encontrar aquí.
¿Dónde está el código?
Sin más preámbulos, comencemos con el código. El proyecto completo en github se puede encontrar aquí.
Comencemos cargando todas las bibliotecas y dependencias.
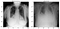
A continuación, mostré algunas imágenes normales y de neumonía para ver cuán diferentes se ven a simple vista. Bueno, no mucho!
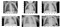
a Continuación, se divide el conjunto de datos en tres conjuntos de entrenamiento, validación y prueba.
A continuación escribí una función en la que realicé un aumento de datos, alimenté las imágenes del conjunto de entrenamiento y prueba a la red. También creé etiquetas para las imágenes.
La práctica del aumento de datos es una forma efectiva de aumentar el tamaño del conjunto de entrenamiento. El aumento de los ejemplos de capacitación permite a la red «ver» puntos de datos más diversificados, pero aún representativos, durante la capacitación.
Luego definí un par de generadores de datos: uno para datos de entrenamiento y otro para datos de validación. Un generador de datos es capaz de cargar la cantidad de datos requerida (un mini lote de imágenes) directamente desde la carpeta de origen, convertirlos en datos de entrenamiento (alimentados al modelo) y objetivos de entrenamiento (un vector de atributos, la señal de supervisión).
Para mis experimentos, me suele definir el
batch_size = 64. En general, un valor entre 32 y 128 debería funcionar bien. Por lo general, debe aumentar/disminuir el tamaño del lote de acuerdo con los recursos computacionales y el rendimiento del modelo.
Después de que he definido algunas constantes para su posterior uso.
El siguiente paso fue construir el modelo. Esto se puede describir en los siguientes 5 pasos.
- Utilicé cinco bloques convolucionales compuestos de capa convolucional, agrupación máxima y normalización por lotes.
- Encima usé una capa plana y la seguí por cuatro capas completamente conectadas.
- También he usado dropouts para reducir el ajuste excesivo.
- La función de activación era Relu en todas partes, excepto en la última capa donde era Sigmoide, ya que se trata de un problema de clasificación binaria.
- He utilizado Adam como optimizador y entropía cruzada como pérdida.
Antes de entrenar, el modelo es útil para definir una o más devoluciones de llamada. Bastante útil, son: ModelCheckpoint y EarlyStopping.
- Punto de control del modelo: cuando el entrenamiento requiere mucho tiempo para lograr un buen resultado, a menudo se requieren muchas iteraciones. En este caso, es mejor guardar una copia del modelo de mejor rendimiento solo cuando finaliza una época que mejora las métricas.
- Salto temprano: a veces, durante el entrenamiento podemos notar que la brecha de generalización (es decir, la diferencia entre el entrenamiento y el error de validación) comienza a aumentar, en lugar de disminuir. Este es un síntoma de sobreajuste que se puede resolver de muchas maneras (reducir la capacidad del modelo, aumentar los datos de entrenamiento, aumentar los datos, regularizar, abandonar, etc.). A menudo, una solución práctica y eficiente es dejar de entrenar cuando la brecha de generalización está empeorando.

a continuación, he entrenado el modelo de 10 épocas con un tamaño de lote de 32. Tenga en cuenta que, por lo general, un tamaño de lote más alto da mejores resultados, pero a expensas de una mayor carga computacional. Algunas investigaciones también afirman que hay un tamaño de lote óptimo para obtener los mejores resultados que se podrían encontrar invirtiendo algo de tiempo en el ajuste de hiper-parámetros.
Vamos a visualizar la pérdida y la precisión de las parcelas.

hasta ahora Tan bueno. El modelo está convergiendo, lo que se puede observar a partir de la disminución de la pérdida y la pérdida de validación con las épocas. También es capaz de alcanzar una precisión de validación del 90% en solo 10 épocas.
Vamos a trazar la matriz de confusión y obtener algunos de los otros resultados también como precisión, recuperación, puntuación de F1 y precisión.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
El modelo es capaz de lograr una precisión del 91,02%, lo que es bastante bueno teniendo en cuenta el tamaño de los datos que se utilizan.
Conclusiones
Aunque este proyecto está lejos de completarse, es notable ver el éxito del aprendizaje profundo en tan variados problemas del mundo real. He demostrado cómo clasificar los datos de neumonía positivos y negativos de una colección de imágenes de rayos X. El modelo se hizo desde cero, lo que lo separa de otros métodos que dependen en gran medida del enfoque de aprendizaje de transferencia. En el futuro, este trabajo podría ampliarse para detectar y clasificar imágenes radiográficas consistentes en cáncer de pulmón y neumonía. Distinguir las imágenes de rayos X que contienen cáncer de pulmón y neumonía ha sido un gran problema en los últimos tiempos, y nuestro próximo enfoque debería ser abordar este problema.