Meltdown y Spectre, explicados
Aunque en estos días soy conocido principalmente por redes a nivel de aplicación y sistemas distribuidos, pasé la primera parte de mi carrera trabajando en sistemas operativos e hipervisores. Mantengo una profunda fascinación por los detalles de bajo nivel de cómo funcionan los procesadores y sistemas modernos de software. Cuando se anunciaron las recientes vulnerabilidades Meltdown y Spectre, profundicé en la información disponible y estaba ansioso por aprender más.
Las vulnerabilidades son asombrosos; Yo diría que son uno de los descubrimientos más importantes en ciencias de la computación en los últimos 10-20 años. Las mitigaciones también son difíciles de entender y es difícil encontrar información precisa sobre ellas. Esto no es sorprendente dada su naturaleza crítica. Mitigar las vulnerabilidades ha requerido meses de trabajo secreto por parte de todos los principales proveedores de CPU, sistemas operativos y nube. El hecho de que los problemas se mantuvieran en secreto durante 6 meses, cuando literalmente cientos de personas probablemente estaban trabajando en ellos, es sorprendente.
Aunque se ha escrito mucho sobre Meltdown y Spectre desde su anuncio, no he visto una buena introducción de nivel medio a las vulnerabilidades y mitigaciones. En este post voy a intentar corregir esto proporcionando una introducción suave a los antecedentes de hardware y software necesarios para comprender las vulnerabilidades, una discusión de las vulnerabilidades en sí, así como una discusión de las mitigaciones actuales.
Nota importante: Porque no he trabajado directamente en las mitigaciones y no trabajo en Intel, Microsoft, Google, Amazon, Red Hat, etc. algunos de los detalles que voy a proporcionar pueden no ser del todo precisos. He juntado esta publicación en base a mi conocimiento de cómo funcionan estos sistemas, documentación disponible públicamente y parches/discusión publicados en LKML y xen-devel. Me encantaría que me corrigieran si algo de este post es inexacto, aunque dudo que eso suceda pronto, dado que gran parte de este tema aún está cubierto por el NDA.
En esta sección proporcionaré algunos antecedentes necesarios para comprender las vulnerabilidades. La sección pasa por alto una gran cantidad de detalles y está dirigida a lectores con un conocimiento limitado de hardware y software de sistemas informáticos.
Memoria virtual
La memoria virtual es una técnica utilizada por todos los sistemas operativos desde la década de 1970. Proporciona una capa de abstracción entre el diseño de direcciones de memoria que ve la mayoría del software y los dispositivos físicos que respaldan esa memoria (RAM, discos, etc.). A un alto nivel, permite que las aplicaciones utilicen más memoria de la que la máquina tiene en realidad; esto proporciona una poderosa abstracción que facilita muchas tareas de programación.

la Figura 1 muestra una visión simplista de la computadora con 400 bytes de memoria establecido en «páginas» de 100 bytes (real de los equipos utilizan potencias de dos, normalmente 4096). La computadora tiene dos procesos, cada uno con 200 bytes de memoria en 2 páginas cada uno. Los procesos pueden estar ejecutando el mismo código utilizando direcciones fijas en el rango de 0 a 199 bytes, sin embargo, están respaldados por una memoria física discreta de modo que no se influyen entre sí. Aunque los sistemas operativos y las computadoras modernas utilizan la memoria virtual de una manera sustancialmente más complicada de lo que se presenta en este ejemplo, la premisa básica presentada anteriormente se mantiene en todos los casos. Los sistemas operativos están abstrayendo las direcciones que la aplicación ve de los recursos físicos que las respaldan.
Traducir direcciones virtuales a físicas es una operación tan común en las computadoras modernas que si el sistema operativo tuviera que estar involucrado en todos los casos, la computadora sería increíblemente lenta. El hardware de CPU moderno proporciona un dispositivo llamado Búfer de búsqueda de traducción (TLB) que almacena en caché las asignaciones usadas recientemente. Esto permite a las CPU realizar la traducción de direcciones directamente en hardware la mayoría de las veces.
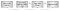
La figura 2 muestra el flujo de traducción de direcciones:
- Un programa obtiene una dirección virtual.
- La CPU intenta traducirlo usando el TLB. Si se encuentra la dirección, se utiliza la traducción.
- Si no se encuentra la dirección, la CPU consulta un conjunto de» tablas de páginas » para determinar la asignación. Las tablas de páginas son un conjunto de páginas de memoria física proporcionadas por el sistema operativo en una ubicación en la que el hardware puede encontrarlas (por ejemplo, el registro CR3 en el hardware x86). Las tablas de páginas asignan direcciones virtuales a direcciones físicas y también contienen metadatos, como permisos.
- Si la tabla de páginas contiene una asignación, se devuelve, se almacena en caché en el TLB y se utiliza para la búsqueda. Si la tabla de páginas no contiene una asignación, se genera un «error de página» en el sistema operativo. Un error de página es un tipo especial de interrupción que permite al sistema operativo tomar el control y determinar qué hacer cuando falta una asignación o no es válida. Por ejemplo, el sistema operativo puede terminar el programa. También puede asignar algo de memoria física y asignarla al proceso. Si un manejador de errores de página continúa la ejecución, el TLB utilizará la nueva asignación.

la Figura 3 se muestra un poco más de visión realista de lo que la memoria virtual se ve como en un ordenador moderno (pre-Crisis — más sobre esto más adelante). En esta configuración tenemos las siguientes características:
- La memoria del núcleo se muestra en rojo. Está contenido en el rango de direcciones físicas 0-99. La memoria del núcleo es una memoria especial a la que solo el sistema operativo debería poder acceder. Los programas de usuario no deberían poder acceder a él.
- La memoria de usuario se muestra en gris.
- La memoria física no asignada se muestra en azul.
En este ejemplo, comenzamos a ver algunas de las características útiles de la memoria virtual. Principalmente:
- La memoria de usuario en cada proceso está en el rango virtual 0-99, pero respaldada por una memoria física diferente.
- La memoria del núcleo en cada proceso está en el rango virtual 100-199, pero respaldada por la misma memoria física.
Como mencioné brevemente en la sección anterior, cada página tiene bits de permiso asociados. Aunque la memoria del núcleo se asigna a cada proceso de usuario, cuando el proceso se ejecuta en modo de usuario, no puede acceder a la memoria del núcleo. Si un proceso intenta hacerlo, desencadenará un error de página en el que el sistema operativo lo terminará. Sin embargo, cuando el proceso se ejecuta en modo kernel (por ejemplo, durante una llamada al sistema), el procesador permitirá el acceso.
En este punto, observaré que este tipo de asignación dual (cada proceso tiene el núcleo asignado directamente en él) ha sido una práctica estándar en el diseño de sistemas operativos durante más de treinta años por razones de rendimiento (las llamadas al sistema son muy comunes y llevaría mucho tiempo reasignar el núcleo o el espacio de usuario en cada transición).
caché de CPU topología

La siguiente información de fondo necesaria para comprender las vulnerabilidades es la topología de CPU y caché de los procesadores modernos. La Figura 4 muestra una topología genérica que es común a la mayoría de las CPU modernas. Se compone de los siguientes componentes:
- La unidad básica de ejecución es el «subproceso de CPU» o «subproceso de hardware» o » hiper-subproceso.»Cada subproceso de CPU contiene un conjunto de registros y la capacidad de ejecutar un flujo de código de máquina, al igual que un subproceso de software.
- Los subprocesos de CPU están contenidos dentro de un «núcleo de CPU».»La mayoría de las CPU modernas contienen dos hilos por núcleo.
- Las CPU modernas generalmente contienen varios niveles de memoria caché. Los niveles de caché más cercanos al subproceso de CPU son más pequeños, más rápidos y más caros. Cuanto más lejos de la CPU y más cerca de la memoria principal, la caché es más grande, más lenta y menos costosa.
- El diseño de CPU moderno típico utiliza una caché L1 / L2 por núcleo. Esto significa que cada subproceso de CPU en el núcleo hace uso de las mismas cachés.
- Varios núcleos de CPU están contenidos en un «paquete de CPU».»Las CPU modernas pueden contener más de 30 núcleos (60 hilos) o más por paquete.
- Todos los núcleos de CPU del paquete suelen compartir una caché L3.
- Los paquetes de CPU caben en «sockets».»La mayoría de las computadoras de consumo son de un solo zócalo, mientras que muchos servidores de centros de datos tienen múltiples zócalos.
Especulativo de ejecución

La última pieza de información de fondo necesaria para comprender las vulnerabilidades es una técnica de CPU moderna conocida como «ejecución especulativa».»La Figura 5 muestra un diagrama genérico del motor de ejecución dentro de una CPU moderna.
La principal conclusión es que las CPU modernas son increíblemente complicadas y no simplemente ejecutan las instrucciones de la máquina en orden. Cada subproceso de CPU tiene un motor de canalización complicado que es capaz de ejecutar instrucciones fuera de servicio. La razón de esto tiene que ver con el almacenamiento en caché. Como comenté en la sección anterior, cada CPU hace uso de múltiples niveles de almacenamiento en caché. Cada falta de caché agrega una cantidad sustancial de tiempo de retardo a la ejecución del programa. Para mitigar esto, los procesadores son capaces de ejecutarse con anticipación y fuera de servicio mientras esperan cargas de memoria. Esto se conoce como ejecución especulativa. El siguiente fragmento de código lo demuestra.
if (x < array1_size) {
y = array2 * 256];
}
En el fragmento anterior, imagina que el array1_size no está disponible en la caché, pero la dirección de array1 es. La CPU podría adivinar (especular) que x es menor que array1_size y seguir adelante y realizar los cálculos dentro de la instrucción if. Una vez que array1_size se lee de la memoria, la CPU puede determinar si adivinó correctamente. Si lo hizo, puede seguir ahorrando mucho tiempo. Si no lo hizo, puede desechar los cálculos especulativos y empezar de nuevo. Esto no es peor que si hubiera esperado en primer lugar.
Otro tipo de ejecución especulativa se conoce como predicción indirecta de ramas. Esto es extremadamente común en los programas modernos debido al envío virtual.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(El origen del fragmento anterior es este post)
La forma en que se implementa el fragmento anterior en el código máquina es cargar la» tabla v «o la» tabla de despacho virtual»desde la ubicación de memoria a la que apunta obj y luego llamarla. Debido a que esta operación es tan común, las CPU modernas tienen varios cachés internos y a menudo adivinan (especulan) hacia dónde irá la rama indirecta y continuarán la ejecución en ese momento. De nuevo, si la CPU adivina correctamente, puede seguir ahorrando mucho tiempo. Si no lo hizo, puede desechar los cálculos especulativos y empezar de nuevo.
Vulnerabilidad de fusión
Habiendo cubierto toda la información de fondo, podemos sumergirnos en las vulnerabilidades.
Carga de caché de datos falsos
La primera vulnerabilidad, conocida como Meltdown, es sorprendentemente fácil de explicar y casi trivial de explotar. El código de exploit se parece a lo siguiente:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
Tomemos cada paso anterior, describamos lo que hace y cómo conduce a poder leer la memoria de todo el equipo desde un programa de usuario.
- En la primera línea, se asigna un» array de sonda». Esta es la memoria en nuestro proceso que se utiliza como un canal lateral para recuperar datos del núcleo. Cómo se hace esto se hará evidente pronto.
- Después de la asignación, el atacante se asegura de que no se almacene en caché ninguna parte de la memoria de la matriz de pruebas. Hay varias formas de lograr esto, la más simple de las cuales incluye instrucciones específicas de la CPU para borrar una ubicación de memoria de la caché.
- El atacante procede a leer un byte del espacio de direcciones del núcleo. Recuerde de nuestra discusión anterior sobre la memoria virtual y las tablas de páginas que todos los núcleos modernos generalmente asignan todo el espacio de direcciones virtuales del núcleo al proceso de usuario. Los sistemas operativos se basan en el hecho de que cada entrada de la tabla de páginas tiene configuraciones de permisos, y que los programas en modo usuario no tienen permitido acceder a la memoria del núcleo. Cualquier acceso de este tipo resultará en un error de página. Eso es, de hecho, lo que finalmente sucederá en el paso 3.
- Sin embargo, los procesadores modernos también realizan ejecuciones especulativas y se ejecutan antes de la instrucción de errores. Por lo tanto, los pasos 3-5 pueden ejecutarse en la canalización de la CPU antes de que se genere el fallo. En este paso, el byte de la memoria del núcleo (que oscila entre 0 y 255) se multiplica por el tamaño de página del sistema, que normalmente es 4096.
- En este paso, el byte multiplicado de la memoria del núcleo se usa para leer desde la matriz de pruebas en un valor ficticio. La multiplicación del byte por 4096 es para evitar que una función de CPU llamada «prefetcher» lea más datos de los que queremos en la caché.
- En este paso, la CPU se ha dado cuenta de su error y ha retrocedido al paso 3. Sin embargo, los resultados de las instrucciones especuladas todavía son visibles en caché. El atacante utiliza la funcionalidad del sistema operativo para atrapar la instrucción con errores y continuar la ejecución (por ejemplo, manejar SIGFAULT).
- En el paso 7, el atacante itera y ve cuánto tiempo se tarda en leer cada uno de los 256 bytes posibles en la matriz de pruebas que podrían haber sido indexados por la memoria del núcleo. La CPU habrá cargado una de las ubicaciones en la caché y esta ubicación se cargará sustancialmente más rápido que todas las demás ubicaciones (que deben leerse desde la memoria principal). Esta ubicación es el valor del byte en la memoria del núcleo.
Usando la técnica anterior, y el hecho de que es una práctica estándar para los sistemas operativos modernos mapear toda la memoria física en el espacio de direcciones virtuales del núcleo, un atacante puede leer toda la memoria física de la computadora.
Ahora, te estarás preguntando :» Dijiste que las tablas de página tienen bits de permiso. ¿Cómo puede ser que el código de modo de usuario fuera capaz de acceder especulativamente a la memoria del núcleo?»La razón es que se trata de un error en los procesadores Intel. En mi opinión, no hay una buena razón, rendimiento o de otro tipo, para que esto sea posible. Recuerde que todo el acceso a la memoria virtual debe ocurrir a través de la TLB. Durante la ejecución especulativa es fácilmente posible comprobar que una asignación en caché tiene permisos compatibles con el nivel de privilegios en ejecución actual. El hardware Intel simplemente no hace esto. Otros proveedores de procesadores realizan una comprobación de permisos y bloquean la ejecución especulativa. Por lo tanto, hasta donde sabemos, Meltdown es solo una vulnerabilidad de Inteligencia.
Editar: Parece que al menos un procesador ARM también es susceptible a la fusión, como se indica aquí y aquí.
Mitigaciones de Meltdown
Meltdown es fácil de entender, trivial de explotar y, afortunadamente, también tiene una mitigación relativamente sencilla (al menos conceptualmente, los desarrolladores del núcleo podrían no estar de acuerdo en que sea fácil de implementar).
Aislamiento de tabla de páginas del núcleo (KPTI)
Recuerde que en la sección sobre memoria virtual describí que todos los sistemas operativos modernos utilizan una técnica en la que la memoria del núcleo se asigna a cada espacio de direcciones de memoria virtual de proceso en modo de usuario. Esto es por razones de rendimiento y simplicidad. Esto significa que cuando un programa hace una llamada al sistema, el núcleo está listo para ser utilizado sin más trabajo. La solución para Meltdown es dejar de realizar esta asignación dual.

la Figura 6 muestra una técnica llamada Núcleo de la Tabla de páginas de Aislamiento (KPTI). Esto básicamente se reduce a no asignar la memoria del núcleo a un programa cuando se está ejecutando en el espacio de usuario. Si no hay mapeo presente, la ejecución especulativa ya no es posible y fallará inmediatamente.
Además de hacer que el administrador de memoria virtual (VMM) del sistema operativo sea más complicado, sin asistencia de hardware, esta técnica también ralentizará considerablemente las cargas de trabajo que realizan un gran número de transiciones de modo de usuario a modo de núcleo, debido al hecho de que las tablas de páginas deben modificarse en cada transición y el TLB debe vaciarse (dado que el TLB puede retener asignaciones obsoletas).
Las CPU x86 más nuevas tienen una característica conocida como ASID (ID de espacio de direcciones) o PCID (ID de contexto de proceso) que se puede usar para hacer esta tarea sustancialmente más barata (ARM y otras microarquitecturas han tenido esta característica durante años). PCID permite que un ID se asocie con una entrada TLB y luego solo vaciar las entradas TLB con ese ID. El uso de PCID hace que KPTI sea más barato, pero aún no es gratuito.
En resumen, Meltdown es una vulnerabilidad extremadamente seria y fácil de explotar. Afortunadamente, tiene una mitigación relativamente sencilla que ya ha sido implementada por todos los principales proveedores de sistemas operativos, con la advertencia de que ciertas cargas de trabajo se ejecutarán más lentamente hasta que el hardware futuro esté diseñado explícitamente para la separación de espacio de direcciones descrita.
Vulnerabilidad de espectro
Espectro comparte algunas propiedades de Meltdown y se compone de dos variantes. A diferencia de Meltdown, Spectre es sustancialmente más difícil de explotar, pero afecta a casi todos los procesadores modernos producidos en los últimos veinte años. Esencialmente, Spectre es un ataque contra el diseño moderno de la CPU y el sistema operativo frente a una vulnerabilidad de seguridad específica.
Bypass de comprobación de límites (variante de espectro 1)
La primera variante de espectro se conoce como «bypass de comprobación de límites».»Esto se demuestra en el siguiente fragmento de código(que es el mismo fragmento de código que utilicé para introducir la ejecución especulativa anteriormente).
if (x < array1_size) {
y = array2 * 256];
}
En el ejemplo anterior, supongamos que la siguiente secuencia de eventos:
- El atacante controles
x. -
array1_sizeno se almacena en caché. -
array1se almacena en caché. - La CPU estima que
xes menor quearray1_size. (Las CPU emplean varios algoritmos y heurísticas patentados para determinar si especular, por lo que los detalles de ataque para Spectre varían entre los proveedores de procesadores y los modelos.) - La CPU ejecuta el cuerpo de la instrucción if mientras espera que
array1_sizese cargue, afectando a la caché de manera similar a Meltdown. - El atacante puede determinar el valor real de
array1a través de uno de varios métodos. (Consulte el documento de investigación para obtener más detalles sobre los ataques de inferencia de caché.)
Spectre es considerablemente más difícil de explotar que Meltdown porque esta vulnerabilidad no depende de la escalada de privilegios. El atacante debe convencer al núcleo para que ejecute el código y especule incorrectamente. Por lo general, el atacante debe envenenar el motor de especulación y engañarlo para que adivine incorrectamente. Dicho esto, los investigadores han demostrado varias hazañas de prueba de concepto.
Quiero reiterar lo increíble que es encontrar este exploit. Personalmente, no considero esto un defecto de diseño de CPU como Meltdown per se. Considero que esto es una revelación fundamental sobre cómo el hardware y el software modernos funcionan juntos. El hecho de que los cachés de CPU se pueden usar indirectamente para aprender sobre los patrones de acceso se conoce desde hace algún tiempo. El hecho de que los cachés de CPU se puedan usar como un canal lateral para volcar la memoria de la computadora es asombroso, tanto conceptualmente como en sus implicaciones.
Inyección de objetivo de ramificación (variante 2 del espectro)
Recuerde que la ramificación indirecta es muy común en los programas modernos. La variante 2 de Spectre utiliza la predicción de ramas indirectas para envenenar la CPU para que se ejecute especulativamente en una ubicación de memoria que de otra manera nunca habría ejecutado. Si ejecutar esas instrucciones puede dejar un estado en la caché que se puede detectar mediante ataques de inferencia de caché, el atacante puede volcar toda la memoria del núcleo. Al igual que la variante 1 de Spectre, la variante 2 de Spectre es mucho más difícil de explotar que Meltdown, sin embargo, los investigadores han demostrado que funciona la prueba de concepto de la variante 2.
Mitigaciones de espectro
Las mitigaciones de Espectro son sustancialmente más interesantes que la mitigación de fusión. De hecho, el artículo académico Spectre escribe que actualmente no hay mitigaciones conocidas. Parece que detrás de escena y en paralelo al trabajo académico, Intel (y probablemente otros proveedores de CPU) y los principales proveedores de sistemas operativos y nube han estado trabajando furiosamente durante meses para desarrollar mitigaciones. En esta sección cubriré las diversas mitigaciones que se han desarrollado y desplegado. Esta es la sección en la que estoy más confusa, ya que es increíblemente difícil obtener información precisa, por lo que estoy juntando cosas de varias fuentes.
Análisis estático y cercado (mitigación de la variante 1)
La única mitigación conocida de la variante 1 (bypass de verificación de límites) es el análisis estático de código para determinar secuencias de código que podrían ser controladas por atacantes para interferir con la especulación. Las secuencias de código vulnerables pueden tener una instrucción de serialización como lfence insertada que detiene la ejecución especulativa hasta que se hayan ejecutado todas las instrucciones hasta la valla. Se debe tener cuidado al insertar instrucciones de valla, ya que demasiadas pueden tener graves impactos en el rendimiento.
Retpoline (mitigación de la variante 2)
La primera mitigación de la variante 2 de Spectre (inyección de objetivo de rama) fue desarrollada por Google y se conoce como «retpoline».»No me queda claro si fue desarrollado de forma aislada por Google o por Google en colaboración con Intel. Yo especularía que fue desarrollado experimentalmente por Google y luego verificado por ingenieros de hardware de Intel, pero no estoy seguro. Los detalles sobre el enfoque de» retpoline » se pueden encontrar en el documento de Google sobre el tema. Los resumiré aquí (estoy pasando por alto algunos detalles, incluido el flujo insuficiente, que se cubren en el papel).
Retpoline se basa en el hecho de que la llamada y el retorno de funciones y las manipulaciones de pila asociadas son tan comunes en los programas de computadora que las CPU están muy optimizadas para realizarlas. (Si no está familiarizado con cómo funciona la pila en relación con llamar y regresar de funciones, este artículo es un buen manual.) En pocas palabras, cuando se realiza una» llamada», la dirección de retorno se coloca en la pila. «ret» desactiva la dirección de retorno y continúa la ejecución. El hardware de ejecución especulativa recordará la dirección de retorno empujada y continuará especulativamente la ejecución en ese punto.
La construcción retpoline reemplaza un salto indirecto a la ubicación de memoria almacenada en el registro r11:
jmp *%r11
con:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
Veamos qué hace el código de ensamblado anterior paso a paso y cómo mitiga la inyección de destino de rama.
- En este paso, el código llama a una ubicación de memoria que se conoce en tiempo de compilación, por lo que es un desplazamiento codificado duro y no indirecto. Esto coloca la dirección de retorno de
capture_specen la pila. - La dirección de retorno de la llamada se sobrescribe con el objetivo de salto real.
- Se realiza un retorno en el destino real.
- Cuando la CPU se ejecuta de forma especulativa, ¡volverá a un bucle infinito! Recuerde que la CPU especulará con anticipación hasta que se completen las cargas de memoria. En este caso, la especulación ha sido manipulada para ser capturada en un bucle infinito que no tiene efectos secundarios que sean observables por un atacante. Cuando la CPU finalmente ejecuta el retorno real, abortará la ejecución especulativa que no tuvo efecto.
En mi opinión, esta es una mitigación verdaderamente ingeniosa. Felicitaciones a los ingenieros que lo desarrollaron. La desventaja de esta mitigación es que requiere que todo el software se recompile de manera que las ramas indirectas se conviertan en ramas retropolíneas. Para los servicios en la nube como Google que poseen toda la pila, la recompilación no es un gran problema. Para otros, puede ser un gran problema o imposible.
IBRS, STIBP e IBPB (mitigación de variante 2)
Parece que, al mismo tiempo que el desarrollo de retpolines, Intel (y AMD en cierta medida) han estado trabajando furiosamente en cambios de hardware para mitigar los ataques de inyección de objetivo de rama. Las tres nuevas características de hardware que se envían como actualizaciones de microcódigo de CPU son:
- Especulación restringida de Ramas indirectas (IBRS)
- Predictores de Ramas Indirectas de Hilo único (STIBP)
- Barrera Predictora de Ramas Indirectas (IBPB)
Aquí Intel ofrece información limitada sobre las nuevas funciones de microcódigo. He podido reconstruir a grandes rasgos lo que hacen estas nuevas características leyendo la documentación anterior y mirando los parches de hipervisor del kernel de Linux y Xen. A partir de mi análisis, cada característica se usa potencialmente de la siguiente manera:
- IBRS vacía la caché de predicción de ramas entre los niveles de privilegios (usuario al núcleo) y deshabilita la predicción de ramas en el subproceso de CPU hermano. Recuerde que cada núcleo de CPU normalmente tiene dos subprocesos de CPU. Parece que en las CPU modernas el hardware de predicción de ramificaciones se comparte entre los subprocesos. Esto significa que el código de modo de usuario no solo puede envenenar el predictor de ramas antes de ingresar el código del núcleo, sino que el código que se ejecuta en el subproceso de CPU del hermano también puede envenenarlo. Habilitar los IBR mientras está en modo kernel esencialmente evita que cualquier ejecución anterior en modo usuario y cualquier ejecución en el subproceso de CPU hermano afecte la predicción de ramas.
- STIBP parece ser un subconjunto de IBR que solo deshabilita la predicción de ramas en el subproceso de CPU del hermano. Por lo que puedo decir, el caso de uso principal de esta característica es evitar que un subproceso de CPU hermano envenene el predictor de rama cuando se ejecutan dos procesos en modo de usuario diferentes (o máquinas virtuales) en el mismo núcleo de CPU al mismo tiempo. Honestamente, no está completamente claro para mí en este momento cuándo se debe usar STIBP.
- IBPB parece vaciar la caché de predicción de ramificación para el código que se ejecuta en el mismo nivel de privilegios. Esto se puede usar cuando se cambia entre dos programas en modo de usuario o dos máquinas virtuales para garantizar que el código anterior no interfiera con el código que está a punto de ejecutarse (aunque sin STIBP, creo que el código que se ejecuta en el subproceso de CPU hermano aún podría envenenar el predictor de ramas).
En el momento de escribir este artículo, las principales mitigaciones que veo que se están implementando para la vulnerabilidad de inyección de destino de rama parecen ser retpoline e IBRS. Presumiblemente, esta es la forma más rápida de proteger el núcleo de programas en modo usuario o el hipervisor de huéspedes de máquinas virtuales. En el futuro, esperaría que tanto STIBP como IBPB se implementaran dependiendo del nivel de paranoia de los diferentes programas de modo de usuario que interfieren entre sí.
El costo de los IBR también parece variar extremadamente entre arquitecturas de CPU con procesadores Intel Skylake más nuevos que son relativamente baratos en comparación con los procesadores más antiguos. En Lyft, vimos una desaceleración de aproximadamente el 20% en ciertas cargas de trabajo pesadas de llamadas al sistema en instancias de AWS C4 cuando se implementaron las mitigaciones. Especularía que Amazon implementó los RIB y, potencialmente, también la retpoline, pero no estoy seguro. Parece que Google solo ha lanzado retpoline en su nube.
Con el tiempo, esperaría que los procesadores eventualmente se movieran a un modelo IBRS «siempre encendido» donde el hardware simplemente limpia la separación de predictores de ramas entre subprocesos de CPU y limpia correctamente el estado en los cambios de nivel de privilegios. La única razón por la que esto no se haría hoy en día es el aparente costo de rendimiento de adaptar esta funcionalidad a microarquitecturas ya lanzadas a través de actualizaciones de microcódigo.
Conclusión
Es muy raro que un resultado de investigación cambie fundamentalmente la forma en que se construyen y ejecutan los ordenadores. Meltdown y Spectre han hecho precisamente eso. Estos hallazgos alterarán sustancialmente el diseño de hardware y software en los próximos 7-10 años (el próximo ciclo de hardware de la CPU) a medida que los diseñadores tengan en cuenta la nueva realidad de las posibilidades de fuga de datos a través de canales laterales de caché.
Mientras tanto, los hallazgos de Meltdown y Spectre y las mitigaciones asociadas tendrán implicaciones sustanciales para los usuarios de computadoras en los próximos años. A corto plazo, las mitigaciones tendrán un impacto en el rendimiento que puede ser sustancial dependiendo de la carga de trabajo y el hardware específico. Esto puede requerir cambios operativos para algunas infraestructuras (por ejemplo, en Lyft estamos trasladando agresivamente algunas cargas de trabajo a instancias de AWS C5 debido al hecho de que el IBR parece ejecutarse sustancialmente más rápido en procesadores Skylake y el nuevo hipervisor Nitro ofrece interrupciones directamente a los huéspedes que usan SR-IOV y APICv, eliminando muchas salidas de máquinas virtuales para cargas de trabajo pesadas de E / S). Los usuarios de computadoras de escritorio tampoco son inmunes, debido a los ataques de navegador de prueba de concepto que usan JavaScript que los proveedores de sistemas operativos y navegadores están trabajando para mitigar. Además, debido a la complejidad de las vulnerabilidades, es casi seguro que los investigadores de seguridad encontrarán nuevos exploits no cubiertos por las mitigaciones actuales que deberán ser parcheados.
Aunque me encanta trabajar en Lyft y siento que el trabajo que estamos haciendo en el espacio de infraestructura de sistemas de microservicios es uno de los trabajos más impactantes que se realizan en la industria en este momento, eventos como este me hacen extrañar trabajar en sistemas operativos e hipervisores. Estoy extremadamente celoso del trabajo heroico que se ha realizado en los últimos seis meses por un gran número de personas en la investigación y mitigación de las vulnerabilidades. ¡Me hubiera encantado ser parte de ella!
leer Más
- Crisis y Espectro de trabajos académicos: https://spectreattack.com/
- Google Project Zero post en el blog: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Intel Espectro de hardware mitigaciones: https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- Retpoline blog post: https://support.google.com/faqs/answer/7625886
- Buen resumen de la información conocida: https://github.com/marcan/speculation-bugs/blob/master/README.md