Todos los modelos de Aprendizaje automático explicados en 6 minutos
Explicaciones intuitivas de los modelos de aprendizaje automático más populares.

En mi artículo anterior, Me explicó lo de regresión fue y mostró cómo podría ser utilizada en la aplicación. Esta semana, voy a repasar la mayoría de los modelos de aprendizaje automático comunes utilizados en la práctica, para poder pasar más tiempo construyendo y mejorando modelos en lugar de explicar la teoría detrás de ellos. Vamos a sumergirnos en ello.

Todos los modelos de aprendizaje automático son categorizados como supervisado o no supervisado. Si el modelo es un modelo supervisado, se subcategoriza como modelo de regresión o de clasificación. Repasaremos lo que significan estos términos y los modelos correspondientes que caen en cada categoría a continuación.
El aprendizaje supervisado implica aprender una función que asigna una entrada a una salida basada en pares de entrada-salida de ejemplo .
Por ejemplo, si tuviera un conjunto de datos con dos variables, edad (entrada) y altura (salida), podría implementar un modelo de aprendizaje supervisado para predecir la altura de una persona en función de su edad.
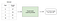
para volver A repetir, dentro del aprendizaje supervisado, hay dos sub-categorías: regresión y clasificación.
Regresión
En los modelos de regresión, la salida es continua. A continuación se presentan algunos de los tipos más comunes de modelos de regresión.
Regresión Lineal

La idea de la regresión lineal es simplemente encontrar una línea que mejor se ajusta a los datos. Las extensiones de regresión lineal incluyen regresión lineal múltiple(ej. encontrar un plano de mejor ajuste) y regresión polinómica (p. ej. encontrar una curva de mejor ajuste). Puedes aprender más sobre la regresión lineal en mi artículo anterior.
Árbol de Decisión
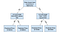
los árboles de Decisión son un modelo popular, utilizado en la investigación de operaciones, planificación estratégica y el aprendizaje de máquina. Cada cuadrado de arriba se llama nodo, y cuantos más nodos tenga, más preciso será su árbol de decisiones (generalmente). Los últimos nodos del árbol de decisión, donde se toma una decisión, se llaman las hojas del árbol. Los árboles de decisión son intuitivos y fáciles de construir, pero se quedan cortos cuando se trata de precisión.
Bosque aleatorio
Los bosques aleatorios son una técnica de aprendizaje en conjunto que se basa en árboles de decisión. Los bosques aleatorios implican la creación de varios árboles de decisión utilizando conjuntos de datos de arranque de los datos originales y la selección aleatoria de un subconjunto de variables en cada paso del árbol de decisión. A continuación, el modelo selecciona el modo de todas las predicciones de cada árbol de decisiones. ¿Qué sentido tiene esto? Al confiar en un modelo de» mayoría ganadora», reduce el riesgo de error de un árbol individual.

Por ejemplo, si hemos creado un árbol de decisión, el tercero, se podría predecir 0. Pero si nos basáramos en el modo de los 4 árboles de decisión, el valor predicho sería 1. Este es el poder de los bosques aleatorios.
StatQuest hace un trabajo increíble recorriendo esto con mayor detalle. Mira aquí.
de la Red Neuronal

Una Red Neuronal es esencialmente una red de ecuaciones matemáticas. Toma una o más variables de entrada, y al pasar por una red de ecuaciones, da como resultado una o más variables de salida. También se puede decir que una red neuronal toma un vector de entradas y devuelve un vector de salidas, pero no entraré en matrices en este artículo.
Los círculos azules representan la capa de entrada, los círculos negros representan las capas ocultas y los círculos verdes representan la capa de salida. Cada nodo de las capas ocultas representa tanto una función lineal como una función de activación por la que pasan los nodos de la capa anterior, lo que en última instancia conduce a una salida en los círculos verdes.
- Si quieres obtener más información al respecto, echa un vistazo a mi explicación para principiantes sobre redes neuronales.
Clasificación
En los modelos de clasificación, la salida es discreta. A continuación se presentan algunos de los tipos más comunes de modelos de clasificación.
Regresión logística
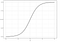
La regresión logística es similar a la regresión lineal, pero se utiliza para modelar la probabilidad de un número finito de resultados, típicamente dos. Hay una serie de razones por las que la regresión logística se utiliza sobre la regresión lineal al modelar probabilidades de resultados (ver aquí). En esencia, una ecuación logística se crea de tal manera que los valores de salida solo pueden estar entre 0 y 1 (ver más abajo).
la Máquina de Soporte Vectorial
Una Máquina de Soporte Vectorial es una clasificación supervisada de la técnica que en realidad puede ser bastante complicado, pero es bastante intuitivo en el nivel más fundamental.
supongamos que hay dos clases de datos. Una máquina vectorial de soporte encontrará un hiperplano o un límite entre las dos clases de datos que maximiza el margen entre las dos clases (consulte a continuación). Hay muchos planos que pueden separar las dos clases, pero solo un plano puede maximizar el margen o la distancia entre las clases.

Si quieres entrar en mayor detalle, Savan escribió un gran artículo sobre Máquinas de Vectores Soporte aquí.
Naive Bayes
Naive Bayes es otro clasificador popular utilizado en la Ciencia de datos. La idea detrás de esto es impulsada por el Teorema de Bayes:
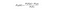
En la llanura inglés, esta ecuación se utiliza para responder a la siguiente pregunta. «¿Cuál es la probabilidad de y (mi variable de salida) dada X? Y debido a la ingenua suposición de que las variables son independientes dada la clase, se puede decir que:

así, quitando el denominador, podemos decir entonces que P(y|X) es proporcional a la mano derecha.

por lo Tanto, el objetivo es encontrar la clase y con la máxima probabilidad proporcional.
Echa un vistazo a mi artículo «Una explicación Matemática de Bayes Ingenuos» si quieres una explicación más profunda!
Árbol de decisión, Bosque aleatorio, Red Neuronal
Estos modelos siguen la misma lógica que se explicó anteriormente. La única diferencia es que esa salida es discreta en lugar de continua.
no supervisado Aprendizaje

A diferencia de aprendizaje supervisado, no supervisado de aprendizaje se utiliza para dibujar inferencias y encontrar patrones de entrada de datos sin referencias a la etiqueta de los resultados. Los dos métodos principales utilizados en el aprendizaje no supervisado incluyen la agrupación en grupos y la reducción de la dimensionalidad.
la Agrupación

la Agrupación es un sin supervisión técnica que consiste en la agrupación de puntos de datos. Se utiliza con frecuencia para la segmentación de clientes, la detección de fraudes y la clasificación de documentos.
Las técnicas comunes de agrupamiento incluyen agrupamiento de k-medias, agrupamiento jerárquico, agrupamiento de desplazamiento medio y agrupamiento basado en densidad. Si bien cada técnica tiene un método diferente para encontrar grupos, todas apuntan a lograr lo mismo.
Reducción de la dimensionalidad
La reducción de la dimensionalidad es el proceso de reducir el número de variables aleatorias bajo consideración mediante la obtención de un conjunto de variables principales . En términos más simples, es el proceso de reducir la dimensión de su conjunto de características (en términos aún más simples, reducir el número de características). La mayoría de las técnicas de reducción de dimensionalidad se pueden clasificar como eliminación de características o extracción de características.
Un método popular de reducción de dimensionalidad se llama análisis de componentes principales.
Análisis de componentes principales (PCA)
En el sentido más simple, el PCA implica datos dimensionales superiores del proyecto(p. ej. 3 dimensiones) a un espacio más pequeño (ej. 2 dimensiones). Esto da como resultado una dimensión más baja de los datos (2 dimensiones en lugar de 3 dimensiones) mientras se mantienen todas las variables originales en el modelo.
Hay un poco de matemáticas involucradas en esto. Si quieres obtener más información al respecto Check
Echa un vistazo a este increíble artículo sobre PCA aquí.
Si prefieres ver un video, StatQuest explica el PCA en 5 minutos aquí.
Conclusión
Obviamente, hay un montón de complejidad si te sumerges en cualquier modelo en particular, ¡pero esto debería darte una comprensión fundamental de cómo funciona cada algoritmo de aprendizaje automático!
Para obtener más artículos como este, consulte https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (2010), Prentice Hall
Roweis, S. T., Saul, L. K., Reducción de Dimensionalidad No Lineal mediante Incrustación Lineal Local (2000), Science