Alle Maskinlæringsmodeller Forklart på 6 Minutter
Intuitive forklaringer på de mest populære maskinlæringsmodellene.

i min forrige artikkel forklarte jeg hva regresjon var og viste hvordan den kunne brukes i søknad. Denne uken skal jeg gå over de fleste vanlige maskinlæringsmodeller som brukes i praksis, slik at jeg kan bruke mer tid på å bygge og forbedre modeller i stedet for å forklare teorien bak den. La oss dykke inn i det.

fundamental Segmentering av maskinlæringsmodeller
alle maskinlæringsmodeller er kategorisert som enten overvåket eller uten tilsyn. Hvis modellen er en overvåket modell, blir den deretter underkategorisert som enten en regresjons-eller klassifikasjonsmodell. Vi går over hva disse begrepene betyr og de tilsvarende modellene som faller inn i hver kategori nedenfor.Overvåket læring innebærer å lære en funksjon som tilordner en inngang til en utgang basert på eksempelinngangsutgangspar .hvis jeg for eksempel hadde et datasett med to variabler, alder (inngang) og høyde( utgang), kunne jeg implementere en veiledet læringsmodell for å forutsi høyden til en person basert på deres alder.
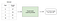
Eksempel På Veiledet Læring figcaption>
for å re-iterate, innenfor veiledet læring, er det to underkategorier: regresjon og klassifisering.
Regresjon
i regresjonsmodeller er utgangen kontinuerlig. Nedenfor er noen av de vanligste typene regresjonsmodeller.
Lineær Regresjon

Div >
ideen om lineær regresjon er ganske enkelt å finne en linje som passer best til dataene. Utvidelser av lineær regresjon inkluderer flere lineære regresjon (f.eks. finne et plan med best passform) og polynomregresjon (f.eks. finne en kurve med best passform). Du kan lære mer om lineær regresjon i min forrige artikkel.
Beslutningstreet
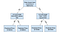
beslutningstrær er en populær modell som brukes i operasjonsforskning, strategisk planlegging og maskinlæring. Hver firkant over kalles en node, og jo flere noder du har, jo mer nøyaktig vil beslutningstreet ditt være (generelt). De siste noder av beslutningstreet, der en beslutning fattes, kalles bladene på treet. Beslutningstrær er intuitive og enkle å bygge, men blir korte når det gjelder nøyaktighet.
Tilfeldig Skog
Tilfeldige skoger Er en ensemble læringsteknikk som bygger av beslutningstrær. Tilfeldige skoger innebærer å skape flere beslutningstrær ved hjelp av bootstrapped datasett av de opprinnelige dataene og tilfeldig velge et delsett av variabler ved hvert trinn i beslutningstreet. Modellen velger deretter modusen for alle spådommer for hvert beslutningstreet. Hva er poenget med dette? Ved å stole på en» majority wins » – modell, reduserer det risikoen for feil fra et enkelt tre.

for eksempel, hvis vi opprettet ett beslutningstre, den tredje, ville det forutsi 0. Men hvis vi stolte på modusen for alle 4 beslutningstrær, ville den forventede verdien være 1. Dette er kraften i tilfeldige skoger.
StatQuest gjør en fantastisk jobb å gå gjennom dette i større detalj. Se her.
Nevrale Nettverk

Visual representasjon av et nevralt nettverk
et nevralt nettverk er i hovedsak et nettverk av matematiske ligninger. Det tar en eller flere inngangsvariabler, og ved å gå gjennom et nettverk av ligninger, resulterer det i en eller flere utgangsvariabler. Du kan også si at et nevralt nettverk tar inn en vektor av innganger og returnerer en vektor av utganger, men jeg kommer ikke inn i matriser i denne artikkelen.
de blå sirklene representerer inngangslaget, de svarte sirklene representerer de skjulte lagene, og de grønne sirklene representerer utgangslaget. Hver node i de skjulte lagene representerer både en lineær funksjon og en aktiveringsfunksjon som nodene i det forrige laget går gjennom, noe som til slutt fører til en utgang i de grønne kretsene.
- hvis du vil lære mer om det, sjekk ut min nybegynnervennlige forklaring på nevrale nettverk.
Klassifisering
i klassifiseringsmodeller er utgangen diskret. Nedenfor er noen av de vanligste typene klassifikasjonsmodeller.
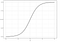
Logistisk Regresjon
Logistisk regresjon ligner lineær regresjon, men brukes til å modellere sannsynligheten for et endelig antall utfall, vanligvis to. Det er flere grunner til at logistisk regresjon brukes over lineær regresjon når man modellerer sannsynligheter for utfall (se her). I hovedsak opprettes en logistisk ligning på en slik måte at utgangsverdiene bare kan være mellom 0 og 1 (se nedenfor).
støtte vektormaskin
en støtte vektormaskin er en overvåket klassifiseringsteknikk som faktisk kan bli ganske komplisert, men er ganske intuitiv på det mest grunnleggende nivået.
la oss anta at det er to klasser av data. En støttevektormaskin vil finne en hyperplan eller en grense mellom de to klassene av data som maksimerer marginen mellom de to klassene (se nedenfor). Det er mange fly som kan skille de to klassene, men bare ett plan kan maksimere marginen eller avstanden mellom klassene.

hvis du vil komme inn i større detalj, skrev savan en flott artikkel om støttevektormaskiner her.
Naive Bayes
Naive Bayes er en annen populær klassifikator som brukes I Datavitenskap. Ideen bak den er drevet Av Bayes Theorem:
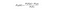
på vanlig engelsk brukes denne ligningen til å svare på følgende spørsmål. «Hva er sannsynligheten for y (min utgangsvariabel) gitt X? Og på grunn av den naive antagelsen om at variabler er uavhengige gitt klassen, kan du si det:

også, ved å fjerne nevneren, kan vi da si at p(y / x) er proporsjonal med høyre side.

derfor er målet å finne klassen y med maksimal proporsjonal sannsynlighet.
Sjekk ut artikkelen min «En Matematisk Forklaring På Naive Bayes» hvis du vil ha en mer grundig forklaring!
Decision Tree, Random Forest, Neural Network
disse modellene følger samme logikk som tidligere forklart. Den eneste forskjellen er at utgangen er diskret i stedet for kontinuerlig.
Læring Uten Tilsyn

i motsetning til veiledet læring brukes ikke-overvåket læring til å trekke slutninger og finne mønstre fra inngangsdata uten referanser til merkede utfall. To hovedmetoder som brukes i unsupervised learning inkluderer clustering og dimensionality reduction.
Clustering

clustering er en unsupervised teknikk som involverer gruppering, eller clustering, av datapunkter. Den brukes ofte til kundesegmentering, svindeloppdagelse og dokumentklassifisering.Vanlige clustering teknikker inkluderer k-betyr clustering, hierarkisk clustering, mean shift clustering og tetthetsbasert clustering. Mens hver teknikk har en annen metode for å finne klynger, tar de alle sikte på å oppnå det samme.
Dimensjonsreduksjon
Dimensjonsreduksjon er prosessen med å redusere antall tilfeldige variabler som vurderes ved å oppnå et sett med hovedvariabler . I enklere termer er det prosessen med å redusere dimensjonen til funksjonssettet ditt (i enda enklere termer, redusere antall funksjoner). De fleste dimensjonsreduksjonsteknikker kan kategoriseres som enten feature elimination eller feature extraction.
en populær metode for dimensjonsreduksjon kalles hovedkomponentanalyse.
Hovedkomponentanalyse (PCA)
I enkleste forstand innebærer PCA prosjekt høyere dimensjonsdata (f.eks. 3 dimensjoner) til en mindre plass (f.eks. 2 dimensjoner). Dette resulterer i en lavere dimensjon av data, (2 dimensjoner i stedet for 3 dimensjoner) mens alle originale variabler i modellen holdes.
det er ganske mye matematikk involvert i dette. Hvis du vil lære mer om DET…
Sjekk ut denne fantastiske artikkelen på PCA her.
Hvis Du heller vil se en video, Forklarer StatQuest PCA om 5 minutter her.
Konklusjon
Det Er åpenbart at det er massevis av kompleksitet hvis du dykker inn i en bestemt modell, men dette bør gi deg en grunnleggende forståelse av hvordan hver maskinlæringsalgoritme fungerer!
For flere artikler som denne, sjekk ut https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Kunstig Intelligens: En Moderne Tilnærming (2010), Prentice Hall
roweis, s. t., saul, l. k., Ikke-lineær Dimensjonsreduksjon Ved Lokalt Lineær Embedding (2000), Vitenskap