Meltdown og Spectre, forklart
Selv om jeg i disse dager er mest kjent for nettverk på applikasjonsnivå og distribuerte systemer, brukte jeg den første delen av karrieren min på operativsystemer og hypervisorer. Jeg opprettholder en dyp fascinasjon med lavt nivå detaljer om hvordan moderne prosessorer og systemer programvare arbeid. Når Den siste Meltdown og Spectre sårbarheter ble annonsert, jeg gravde inn i tilgjengelig informasjon og var ivrig etter å lære mer.
sårbarhetene er forbløffende; Jeg vil hevde at de er en av de viktigste funnene i datavitenskap de siste 10-20 årene. Tiltakene er også vanskelig å forstå og nøyaktig informasjon om dem er vanskelig å finne. Dette er ikke overraskende gitt deres kritiske natur. Å redusere sårbarhetene har krevd måneder med hemmelig arbeid av alle DE store CPU -, operativsystemet og skyleverandørene. Det faktum at problemene ble holdt under wraps for 6 måneder når bokstavelig talt hundrevis av mennesker var sannsynlig å jobbe med dem er fantastisk.Selv om Mye har blitt skrevet om Meltdown og Spectre siden kunngjøringen, har jeg ikke sett en god mid – level introduksjon til sårbarheter og begrensninger. I dette innlegget skal jeg forsøke å rette opp det ved å gi en mild introduksjon til maskinvare-og programvarebakgrunnen som kreves for å forstå sårbarhetene, en diskusjon av sårbarhetene selv, samt en diskusjon av dagens begrensninger.Viktig merknad: fordi Jeg ikke har jobbet direkte med begrensningene, og ikke jobber Hos Intel, Microsoft, Google, Amazon, Red Hat, etc. noen av detaljene som jeg kommer til å gi kan ikke være helt nøyaktig. Jeg har satt sammen dette innlegget basert på min kunnskap om hvordan disse systemene fungerer, offentlig tilgjengelig dokumentasjon,og patcher / diskusjon lagt TIL LKML og xen-devel. Jeg vil gjerne bli korrigert hvis noe av dette innlegget er unøyaktig, selv om jeg tviler på at det vil skje helst snart gitt hvor mye av dette emnet er fortsatt dekket AV NDA.
i denne delen vil jeg gi litt bakgrunn som kreves for å forstå sårbarhetene. Seksjonen glatter over en stor mengde detaljer og er rettet mot lesere med begrenset forståelse av maskinvare og systemprogramvare.
Virtuelt minne
Virtuelt minne er en teknikk som brukes av alle operativsystemer siden 1970-tallet. Det gir et lag av abstraksjon mellom minneadresseoppsettet som de fleste programvare ser og de fysiske enhetene som støtter det minnet (RAM, disker, etc.). På et høyt nivå tillater det at applikasjoner bruker mer minne enn maskinen faktisk har; dette gir en kraftig abstraksjon som gjør mange programmeringsoppgaver enklere.

Figur 1: Virtuelt minne/figcaption>
figur 1 viser en forenklet datamaskin med 400 byte minne lagt ut i»sider»på 100 byte (ekte datamaskiner bruker krefter på to, typisk 4096). Datamaskinen har to prosesser, hver med 200 byte minne over 2 sider hver. Prosessene kan kjøre samme kode ved hjelp av faste adresser i 0-199 byte-området, men de støttes av diskret fysisk minne slik at de ikke påvirker hverandre. Selv om moderne operativsystemer og datamaskiner bruker virtuelt minne på en vesentlig mer komplisert måte enn det som presenteres i dette eksemplet, holder den grunnleggende premissen som presenteres ovenfor i alle tilfeller. Operativsystemer abstraherer adressene som programmet ser fra de fysiske ressursene som støtter dem.Å Oversette virtuelle til fysiske adresser Er en så vanlig operasjon i moderne datamaskiner at HVIS OPERATIVSYSTEMET måtte være involvert i alle tilfeller, ville datamaskinen være utrolig treg. Moderne CPU-maskinvare gir en enhet kalt En Translation Lookaside Buffer (TLB) som cacher nylig brukte mappings. Dette gjør At Cpuer kan utføre adresseoversettelse direkte i maskinvare mesteparten av tiden.
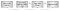
figur 2: Virtual memory translation
Figur 2 viser adresseoversettelsesflyten:
- et program henter en virtuell adresse.
- CPUEN forsøker å oversette DEN ved HJELP AV TLB. Hvis adressen er funnet, brukes oversettelsen.
- HVIS adressen ikke blir funnet, KONSULTERER CPU et sett med «sidetabeller» for å bestemme tilordningen. Sidetabeller er et sett med fysiske minnesider levert av operativsystemet på et sted maskinvaren kan finne dem (FOR EKSEMPEL CR3-registeret på x86-maskinvaren). Sidetabeller tilordner virtuelle adresser til fysiske adresser, og inneholder også metadata som tillatelser.
- hvis sidetabellen inneholder en tilordning, returneres den, bufres i TLB og brukes til oppslag. Hvis sidetabellen ikke inneholder en tilordning, heves EN» sidefeil » TIL OPERATIVSYSTEMET. En sidefeil er en spesiell type avbrudd som gjør AT OPERATIVSYSTEMET kan ta kontroll og bestemme hva som skal gjøres når det mangler eller er ugyldig kartlegging. FOR EKSEMPEL KAN OPERATIVSYSTEMET avslutte programmet. Det kan også tildele noe fysisk minne og kartlegge det i prosessen. Hvis en sidefeilbehandler fortsetter å utføre, vil DEN nye tilordningen bli brukt av TLB.

figur 3: bruker/kernel virtual memory mappings
figur 3 viser en litt mer realistisk visning av hva virtuelt minne ser ut i en moderne datamaskin (pre-meltdown — mer om dette nedenfor). I dette oppsettet har vi følgende funksjoner:
- Kernel minne vises i rødt. Den finnes i fysisk adresseområde 0-99. Kjerneminne er spesielt minne som bare operativsystemet skal kunne få tilgang til. Brukerprogrammer skal ikke kunne få tilgang til det.
- brukerminne vises i grått.
- Ikke-Allokert fysisk minne vises i blått.
i dette eksemplet begynner vi å se noen av de nyttige funksjonene i virtuelt minne. Primært:
- brukerminne i hver prosess er i det virtuelle området 0-99, men støttet av forskjellig fysisk minne.Kjerneminnet i hver prosess er i det virtuelle området 100-199, men støttet av det samme fysiske minnet.
som jeg kort nevnte i forrige avsnitt, har hver side tilhørende tillatelsesbiter. Selv om kjerneminnet er kartlagt i hver brukerprosess, når prosessen kjører i brukermodus, kan den ikke få tilgang til kjerneminnet. Hvis en prosess forsøker å gjøre det, vil det utløse en sidefeil på hvilket tidspunkt operativsystemet vil avslutte det. Men når prosessen kjører i kjernemodus (for eksempel under et systemanrop), vil prosessoren tillate tilgangen.På dette punktet vil jeg merke at denne typen dual mapping (hver prosess som har kjernen kartlagt direkte) har vært standard praksis i operativsystemdesign i over tretti år av ytelsesårsaker (systemkall er svært vanlige, og det vil ta lang tid å omforme kjernen eller brukerplassen ved hver overgang).
CPU cache topologi

figur 4: cpu tråd, kjerne, pakke og cache topologi.
DEN neste bit av bakgrunnsinformasjon som kreves for å forstå sårbarheter ER CPU og cache topologi av moderne prosessorer. Figur 4 viser en generisk topologi som er felles for de fleste moderne Cpuer. Den består av følgende komponenter:
- den grunnleggende enheten for utførelse er «CPU thread» eller «hardware thread» eller » hyper-thread.»Hver CPU-tråd inneholder et sett med registre og muligheten til å utføre en strøm av maskinkode, omtrent som en programvaretråd.
- CPU-tråder finnes i EN » CPU-kjerne.»De fleste moderne Cpuer inneholder to tråder per kjerne.Moderne Cpuer inneholder generelt flere nivåer av cache-minne. Cachenivåene nærmere CPU-tråden er mindre, raskere og dyrere. Jo lenger UNNA CPU og nærmere hovedminnet cachen er, jo større, langsommere og billigere er det.Typisk MODERNE CPU-design bruker En L1 / L2-cache per kjerne. Dette betyr at hver CPU-tråd på kjernen bruker de samme cachene.
- Flere CPU-kjerner finnes i EN » CPU-pakke.»Moderne Cpuer kan inneholde opptil 30 kjerner (60 tråder) eller mer per pakke.
- ALLE CPU-kjernene i pakken deler vanligvis En l3-cache.
- CPU-pakker passer inn i » stikkontakter.»De fleste forbruker datamaskiner er single socket mens mange datasenter servere har flere stikkontakter.
Spekulativ utførelse

figur 5: moderne cpu-utførelsesmotor (kilde: Google images)
den siste delen av bakgrunnsinformasjonen som kreves for å forstå sårbarhetene, er en moderne CPU-teknikk kjent som » spekulativ utførelse.»Figur 5 viser et generisk diagram over utførelsesmotoren inne i en moderne CPU . den primære takeaway er at moderne Cpuer er utrolig kompliserte og ikke bare utfører maskininstruksjoner i rekkefølge. HVER CPU-tråd har en komplisert rørledningsmotor som er i stand til å utføre instruksjoner ute av drift. Årsaken til dette har å gjøre med caching. Som jeg diskuterte i forrige avsnitt, bruker HVER CPU flere nivåer av caching. Hver cache miss legger en betydelig mengde forsinkelse tid til programutførelse. For å redusere dette, er prosessorer i stand til å utføre fremover og ute av drift mens de venter på minnebelastninger. Dette kalles spekulativ utførelse. Følgende kodebit demonstrerer dette.
if (x < array1_size) {
y = array2 * 256];
}
i forrige tekstutdrag, tenk deg at array1_size ikke er tilgjengelig i cache, men adressen til array1 er. CPUEN kan gjette (spekulere) at x er mindre enn array1_size og fortsett og utfør beregningene i if-setningen. Når array1_size leses fra minnet, KAN CPUEN avgjøre om den gjettet riktig. Hvis det gjorde det, kan det fortsette å ha spart en haug med tid. Hvis det ikke gjorde det, kan det kaste bort spekulative beregninger og starte på nytt. Dette er ikke verre enn om det hadde ventet i utgangspunktet.
en annen type spekulativ utførelse er kjent som indirekte grenprediksjon. Dette er ekstremt vanlig i moderne programmer på grunn av virtuell forsendelse.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(kilden til den forrige kodebiten er dette innlegget)
måten den forrige kodebiten er implementert i maskinkode, er å laste «v-table» eller «virtual dispatch table» fra minneplasseringen som obj peker på og deretter kaller det. Fordi denne operasjonen er så vanlig, har moderne Cpuer ulike interne cacher og vil ofte gjette (spekulere) hvor den indirekte grenen vil gå og fortsette utførelsen på det tidspunktet. Igjen, hvis CPU gjetter riktig, kan den fortsette å ha lagret en masse tid. Hvis det ikke gjorde det, kan det kaste bort spekulative beregninger og starte på nytt.
Meltdown sårbarhet
Etter å ha dekket all bakgrunnsinformasjon, kan vi dykke inn i sårbarhetene.
Rogue data cache load
det første sikkerhetsproblemet, Kjent som Meltdown, er overraskende enkelt å forklare og nesten trivielt å utnytte. Utnyttelseskoden ser omtrent ut som følgende:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
la oss ta hvert trinn over, beskrive hva det gjør, og hvordan det fører til å kunne lese minnet til hele datamaskinen fra et brukerprogram.
- i første linje tildeles en «probe array». Dette er minne i vår prosess som brukes som en sidekanal for å hente data fra kjernen. Hvordan dette gjøres vil bli tydelig snart.
- etter tildelingen sørger angriperen for at ingen av minnet i sondearrayen er bufret. Det finnes ulike måter å oppnå dette på, den enkleste som inkluderer CPU-spesifikke instruksjoner for å fjerne en minneplassering fra cache.
- angriperen fortsetter deretter å lese en byte fra kjernens adresseområde. Husk fra vår tidligere diskusjon om virtuelt minne og sidetabeller at alle moderne kjerner vanligvis kartlegger hele kjernens virtuelle adresserom i brukerprosessen. Operativsystemer er avhengige av at hver sidetabelloppføring har tillatelsesinnstillinger, og at brukermodusprogrammer ikke har tilgang til kjerneminnet. Enhver slik tilgang vil resultere i en sidefeil. Det er faktisk det som til slutt vil skje i trinn 3.
- men moderne prosessorer utfører også spekulativ utførelse og vil utføre før feilinstruksjonen. Dermed kan trinn 3-5 utføre I CPU-rørledningen før feilen heves. I dette trinnet multipliseres byten til kjerneminnet (som varierer fra 0-255) med sidestørrelsen til systemet, som vanligvis er 4096.
- i dette trinnet brukes den multipliserte byten av kjerneminnet til å lese fra sondearrayen til en dummy-verdi. Multiplikasjonen av byten med 4096 er å unngå EN CPU-funksjon kalt «prefetcher» fra å lese mer data enn vi vil ha inn i cachen.
- VED dette trinnet har CPUEN innsett sin feil og rullet tilbake til trinn 3. Resultatene av de spekulerte instruksjonene er imidlertid fortsatt synlige i cache. Angriperen bruker operativsystemfunksjonalitet til å fange feilinstruksjonen og fortsette kjøring (f.eks. håndtering AV SIGFAULT).
- i trinn 7 går angriperen gjennom og ser hvor lang tid det tar å lese hver av de 256 mulige byte i sondearrayen som kunne ha blitt indeksert av kjerneminnet. CPUEN vil ha lastet en av stedene i cache, og denne plasseringen vil lastes vesentlig raskere enn alle de andre stedene (som må leses fra hovedminnet). Denne plasseringen er verdien av byten i kjerneminnet.Ved hjelp av teknikken ovenfor, og det faktum at det er vanlig praksis for moderne operativsystemer å kartlegge alt fysisk minne i kjernens virtuelle adresserom, kan en angriper lese hele datamaskinens fysiske minne.
Nå lurer du kanskje på: «du sa at sidetabeller har tillatelsesbiter. Hvordan kan det være at brukermoduskoden kunne spekulativt få tilgang til kjerneminnet?»Årsaken er at dette er En feil I Intel-prosessorer . Etter min mening er det ingen god grunn, ytelse eller på annen måte, for at dette skal være mulig. Husk at all tilgang til virtuelt minne må skje VIA TLB. Det er lett mulig under spekulativ kjøring å kontrollere at en bufret tilordning har tillatelser som er kompatible med gjeldende kjørerettighetsnivå. Intel-maskinvare gjør det ganske enkelt ikke. Andre prosessorleverandører utfører en tillatelseskontroll og blokkerer spekulativ utførelse. Således, så vidt Vi vet, Er Meltdown Et Intel – eneste sårbarhet.
Edit: det ser ut til at minst EN ARM-prosessor også er utsatt for Nedsmelting som angitt her og her.
Meltdown mitigations
Meltdown Er lett å forstå, trivielt å utnytte, og heldigvis har også en relativt grei begrensning (i hvert fall konseptuelt — kjerneutviklere er kanskje ikke enige om at det er greit å implementere).
Kernel page table isolation (KPTI)
Husk at i delen om virtuelt minne beskrev jeg at alle moderne operativsystemer bruker en teknikk der kjerneminnet er kartlagt i hver brukermodus prosess virtuelt minneadresseplass. Dette er for både ytelse og enkelhet grunner. Det betyr at når et program gjør et systemanrop, er kjernen klar til å brukes uten videre arbeid. Løsningen for Meltdown er å ikke lenger utføre denne doble kartleggingen.

Figur 6: Kjerneside tabell isolasjon
figur 6 viser en teknikk kalt kernel page table isolation (kpti). Dette koker i utgangspunktet ned til ikke å kartlegge kjerneminnet i et program når det kjører i brukerrom. Hvis det ikke er noen kartlegging til stede, er spekulativ utførelse ikke lenger mulig og vil umiddelbart feil.I tillegg til å gjøre operativsystemets virtual memory manager (VMM) mer komplisert, vil denne teknikken også betydelig redusere arbeidsbelastninger som gjør et stort antall brukermodus til kjernemodusoverganger, på grunn av at sidetabellene må endres på hver overgang og TLB må spyles (gitt AT TLB kan holde fast på foreldede tilordninger).Nyere X86-Prosessorer har en funksjon kjent som ASID (address space ID) eller PCID (process context ID) som kan brukes til å gjøre denne oppgaven vesentlig billigere (ARM og andre mikroarkitekturer har hatt denne funksjonen i årevis). PCID tillater EN ID for å bli assosiert MED EN TLB oppføring og deretter å bare flush TLB oppføringer med AT ID. BRUKEN AV PCID gjør KPTI billigere, men fortsatt ikke gratis.
I sammendraget Er Meltdown en ekstremt alvorlig og lett å utnytte sårbarhet. Heldigvis har den en relativt enkel begrensning som allerede er distribuert av alle store os-leverandører, og advarselen er at visse arbeidsbelastninger vil kjøre tregere til fremtidig maskinvare er eksplisitt designet for adresseromseparasjonen som er beskrevet.
spectre sårbarhet
Spectre deler noen Egenskaper Av Meltdown og består av to varianter. I motsetning Til Meltdown Er Spectre vesentlig vanskeligere å utnytte, men påvirker nesten alle moderne prosessorer produsert de siste tjue årene. I hovedsak Er Spectre et angrep mot moderne CPU og operativsystemdesign versus et bestemt sikkerhetsproblem.
Bounds check bypass (Spectre variant 1)
Den første Spectre varianten er kjent som » bounds check bypass.»Dette er demonstrert i følgende kodebit (som er den samme kodebiten jeg pleide å introdusere spekulativ utførelse ovenfor).
if (x < array1_size) {
y = array2 * 256];
}i det forrige eksemplet antar du følgende hendelsesrekkefølge:
- angriperen kontrollerer
x. -
array1_sizebufres ikke. -
array1bufres. - CPU gjetter at
xer mindre ennarray1_size. (Cpuer bruker ulike proprietære algoritmer og heuristikk for å avgjøre om de skal spekulere, og derfor varierer angrepsdetaljer for Spectre mellom prosessorleverandører og modeller.) - CPUEN utfører kroppen til if-setningen mens den venter på
array1_sizeå laste, og påvirker hurtigbufferen på samme måte Som Meltdown. - angriperen kan da bestemme den faktiske verdien av
array1via en av ulike metoder. (Se forskning papir for mer informasjon om cache slutning angrep.)
Spectre er betydelig vanskeligere å utnytte enn Meltdown fordi dette sikkerhetsproblemet ikke er avhengig av opptrapping av privilegier. Angriperen må overbevise kjernen om å kjøre kode og spekulere feil. Vanligvis må angriperen forgifte spekulasjonsmotoren og lure den til å gjette feil. Når det er sagt, har forskere vist flere bevis på konseptutnyttelser.
jeg vil gjenta hva en virkelig utrolig å finne denne utnyttelsen er. Jeg anser ikke personlig dette SOM EN CPU-designfeil som Meltdown per se. Jeg anser dette som en grunnleggende åpenbaring om hvordan moderne maskinvare og programvare fungerer sammen. Det faktum AT CPU-cacher kan brukes indirekte for å lære om tilgangsmønstre, har vært kjent i noen tid. DET faktum AT CPU-cacher kan brukes som en sidekanal for å dumpe datamaskinens minne er forbløffende, både konseptuelt og i dens implikasjoner.
Branch target injection (Spectre variant 2)
Husk at indirekte forgrening er svært vanlig i moderne programmer. Variant 2 Av Spectre benytter indirekte grenprediksjon for å forgifte CPUEN til spekulativt å utføre til et minnested som det aldri ellers ville ha utført. Hvis utføring av disse instruksjonene kan etterlate tilstand i hurtigbufferen som kan oppdages ved hjelp av cache-inferanseangrep, kan angriperen dumpe alt kjerneminnet. Som Spectre variant 1, Spectre variant 2 er mye vanskeligere å utnytte enn Meltdown, men forskere har vist arbeider proof-of-concept utnyttelser av variant 2.
Spectre mitigations
Spectre mitigations er vesentlig mer interessant enn Meltdown mitigation. Faktisk skriver academic Spectre-papiret at det for øyeblikket ikke er noen kjente begrensninger. Det ser ut til at Bak kulissene og parallelt med det akademiske arbeidet Har Intel (og sannsynligvis andre CPU-leverandører) og de store OS-og skyleverandørene jobbet rasende i flere måneder for å utvikle tiltak. I denne delen vil jeg dekke de ulike tiltakene som er utviklet og distribuert. Dette er den delen jeg er mest disig på som det er utrolig vanskelig å få nøyaktig informasjon, så jeg piecing ting sammen fra ulike kilder.
Statisk analyse og inngjerding (variant 1 mitigation)
den eneste kjente varianten 1 (bounds check bypass) mitigation er statisk analyse av kode for å bestemme kodesekvenser som kan være angriper kontrollert for å forstyrre spekulasjon. Sårbare kodesekvenser kan ha en serialiseringsinstruksjon som
lfencesatt inn som stopper spekulativ kjøring til alle instruksjoner opp til gjerdet er utført. Vær forsiktig når du setter inn gjerdeinstruksjoner, da for mange kan ha alvorlige ytelseseffekter.Retpoline (variant 2 mitigation)
Den første Spectre variant 2 (branch target injection) mitigation ble utviklet Av Google og er kjent som » retpoline.»Det er uklart for meg om Det ble utviklet isolert Av Google eller Av Google i samarbeid med Intel. Jeg vil spekulere på At Det ble eksperimentelt utviklet Av Google og deretter verifisert Av Intel hardware ingeniører, men jeg er ikke sikker. Detaljer om» retpoline » – tilnærmingen finnes i Googles papir om emnet. Jeg vil oppsummere dem her (jeg glatter over noen detaljer, inkludert understrøm som er dekket i papiret).Retpoline er avhengig av det faktum at kall og retur fra funksjoner og tilhørende stakkmanipulasjoner er så vanlige i dataprogrammer at Cpuer er tungt optimalisert for å utføre dem. (Hvis du ikke er kjent med hvordan stakken fungerer i forhold til å ringe og returnere fra funksjoner, er dette innlegget en god primer.) I et nøtteskall, når en «samtale» utføres, blir returadressen presset på stakken. «ret» dukker returadressen av og fortsetter utførelsen. Spekulativ utførelsesmaskinvare vil huske den pressede returadressen og spekulativt fortsette utførelsen på det tidspunktet.
retpoline-konstruksjonen erstatter et indirekte hopp til minneplasseringen lagret i register
r11:jmp *%r11
med:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)La oss se hva den forrige monteringskoden gjør ett trinn om gangen og hvordan det reduserer grenmålinjeksjon.
- i dette trinnet kaller koden en minneplassering som er kjent ved kompileringstid, så det er en hardkodet forskyvning og ikke indirekte. Dette plasserer returadressen til
capture_specpå stakken. - returadressen fra samtalen blir overskrevet med selve hopp målet.
- en retur utføres på det virkelige målet.
- Når CPUEN spekulativt utfører, kommer den tilbake til en uendelig sløyfe! Husk at CPUEN vil spekulere fremover til minnebelastningen er fullført. I dette tilfellet har spekulasjonen blitt manipulert for å bli fanget inn i en uendelig sløyfe som ikke har noen bivirkninger som kan observeres for en angriper. NÅR CPUEN til slutt utfører den virkelige avkastningen, vil den avbryte den spekulative utførelsen som ikke hadde noen effekt.
etter min mening er dette en virkelig genial begrensning. Kudos til ingeniørene som utviklet den. Ulempen med denne løsningen er at det krever at all programvare blir rekompilert slik at indirekte grener konverteres til retpoline-grener. For skytjenester Som Google som eier hele stakken, er rekompilering ikke en stor avtale. For andre kan det være en veldig stor avtale eller umulig.
IBRS, STIBP, OG IBPB (variant 2 mitigation)
Det ser ut til at Samtidig med retpoline utvikling, Intel (OG AMD til en viss grad) har jobbet rasende på maskinvareendringer for å redusere gren mål injeksjon angrep. De tre nye maskinvarefunksjonene som sendes SOM CPU-mikrokodeoppdateringer er:Indirekte Grenspekulasjoner (IBRS)
- ENKELT Tråd Indirekte Grenspekulatorer (STIBP)
- Indirekte Grenspekulatorbarriere (IBPB)
Begrenset informasjon om de nye mikrokodefunksjonene er tilgjengelig fra Intel her. Jeg har grovt sett sammen hva disse nye funksjonene gjør ved å lese dokumentasjonen ovenfor og se På Linux kernel og Xen hypervisor patcher. Fra min analyse er hver funksjon potensielt brukt som følger:
- IBRS spyler både grenforutsigelsesbufferen mellom rettighetsnivåer (bruker til kjerne) og deaktiverer grenforutsigelse på søsken CPU-tråden. Husk at hver CPU-kjerne vanligvis har to CPU-tråder. Det ser ut til at på moderne Cpuer deles grenen prediksjon maskinvare mellom trådene. Dette betyr at ikke bare kan brukermoduskode forgifte grenen prediktor før du skriver inn kjernekoden, kode som kjører på søsken CPU tråden kan også forgifte det. Aktivering AV IBRS mens du er i kjernemodus, forhindrer i hovedsak tidligere kjøring i brukermodus og eventuell kjøring på søsken CPU-tråden fra å påvirke grenforutsigelse.
- STIBP ser ut til å være en delmengde AV IBRS som bare deaktiverer grenforutsigelse på søsken CPU-tråden. Så vidt jeg kan fortelle, er hovedbrukstilfellet for denne funksjonen å forhindre at en SØSKEN CPU-tråd forgifter grensprediktor når du kjører to forskjellige brukermodusprosesser (eller virtuelle maskiner) på samme CPU-kjerne samtidig. Det er ærlig ikke helt klart for meg akkurat nå når STIBP skal brukes.
- IBPB ser ut til å skylle grenforutsigelsesbufferen for kode som kjører på samme rettighetsnivå. Dette kan brukes når du bytter mellom to brukermodusprogrammer eller to virtuelle maskiner for å sikre at den forrige koden ikke forstyrrer koden som skal kjøre (men uten STIBP tror jeg at kode som kjører på søsken CPU-tråden, fortsatt kan forgifte grenspredikatoren).
som i skrivende stund, de viktigste tiltak som jeg ser blir implementert for grenen mål injeksjon sårbarhet synes å være både retpoline og IBRS. Formentlig er dette den raskeste måten å beskytte kjernen mot brukermodusprogrammer eller hypervisoren fra virtuelle maskingjester. I fremtiden forventer jeg at BÅDE STIBP og IBPB skal distribueres avhengig av paranoia-nivået på ulike brukermodusprogrammer som forstyrrer hverandre.kostnaden for IBRS ser også ut til å variere ekstremt mye MELLOM CPU-arkitekturer, med nyere Intel Skylake-prosessorer som er relativt billige sammenlignet med eldre prosessorer. På Lyft så vi en nedgang på omtrent 20% på visse systemkall tunge arbeidsbelastninger på AWS C4-forekomster når begrensningene ble rullet ut. Jeg vil spekulere på At Amazon rullet UT IBRS og potensielt også retpoline, men jeg er ikke sikker. Det ser ut Til At Google kanskje bare har rullet ut retpoline i skyen.Over tid vil jeg forvente at prosessorer til slutt vil flytte til EN IBRS» alltid på » – modell der maskinvaren bare standardiserer å rengjøre grensprediktorseparasjon mellom CPU-tråder og riktig spyler tilstand på rettighetsnivåendringer. Den eneste grunnen til at dette ikke ville bli gjort i dag, er den tilsynelatende ytelseskostnaden for ettermontering av denne funksjonaliteten på allerede utgitte mikroarkitekturer via mikrokodeoppdateringer.
Konklusjon
det er svært sjelden at et forskningsresultat fundamentalt endrer hvordan datamaskiner bygges og kjøres. Meltdown Og Spectre har gjort nettopp det. Disse funnene vil endre maskinvare-og programvaredesign betydelig i løpet av de neste 7-10 årene (neste CPU-maskinvaresyklus), da designere tar hensyn til den nye virkeligheten av mulighetene for datalekkasje via cache-sidekanaler.
I mellomtiden Vil Meltdown og Spectre funn og tilhørende begrensninger ha betydelige implikasjoner for databrukere i årene som kommer. På kort sikt vil begrensningene ha en ytelsespåvirkning som kan være betydelig avhengig av arbeidsbelastning og spesifikk maskinvare. Dette kan nødvendiggjøre operasjonelle endringer for enkelte infrastrukturer (For Eksempel på Lyft flytter Vi aggressivt noen arbeidsbelastninger TIL AWS C5-forekomster på grunn av AT IBRS ser ut til å kjøre vesentlig raskere på Skylake-prosessorer, og den nye Nitro hypervisor leverer avbrudd direkte til gjester som bruker SR-IOV og APICv, og fjerner mange virtuelle maskinutganger for IO tunge arbeidsbelastninger). Stasjonære pc-brukere er ikke immune heller, på grunn av proof-of-concept nettleser angrep ved Hjelp Av JavaScript SOM OS og nettleser leverandører arbeider for å redusere. I tillegg, på grunn av kompleksiteten til sårbarhetene, er det nesten sikkert at sikkerhetsforskere vil finne nye utnyttelser som ikke dekkes av de nåværende tiltakene som må lappes.Selv om Jeg elsker Å jobbe På Lyft og føler at arbeidet vi gjør i microservice systems infrastruktur plass er noe av det mest virkningsfulle arbeidet som gjøres i bransjen akkurat nå, gjør hendelser som dette meg savner å jobbe med operativsystemer og hypervisorer. Jeg er ekstremt sjalu på det heroiske arbeidet som ble gjort de siste seks månedene av et stort antall mennesker i å undersøke og redusere sårbarhetene. Jeg skulle gjerne ha vært en del av det!
Videre lesing
- Meltdown and Spectre akademiske artikler: https://spectreattack.com/
- retpoline Blogginnlegg: https://support.google.com/faqs/answer/7625886
- godt sammendrag av kjent informasjon: https://github.com/marcan/speculation-bugs/blob/master/README.md
google Project Zero blogginnlegg: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- angriperen kontrollerer