wszystkie modele uczenia maszynowego wyjaśnione w 6 minut
intuicyjne wyjaśnienia najpopularniejszych modeli uczenia maszynowego.

w poprzednim artykule wyjaśniłem, czym jest regresja i pokazałem, jak można ją wykorzystać w aplikacji. W tym tygodniu omówię większość popularnych modeli uczenia maszynowego używanych w praktyce, aby móc poświęcić więcej czasu na budowanie i ulepszanie modeli, zamiast wyjaśniać teorię, która się za tym kryje. Zagłębimy się w to.

wszystkie modele uczenia maszynowego są klasyfikowane jako nadzorowane lub nienadzorowane. Jeśli model jest modelem nadzorowanym, jest on następnie podkategoryzowany jako model regresji lub klasyfikacji. Omówimy, co oznaczają te terminy i odpowiadające im modele, które należą do każdej z poniższych kategorii.
nadzorowane uczenie się polega na uczeniu się funkcji, która mapuje dane wejściowe na dane wyjściowe na podstawie przykładowych par wejście-wyjście .
na przykład, gdybym miał zestaw danych z dwiema zmiennymi, wiekiem (wejście) i wysokością (wyjście), mógłbym zaimplementować nadzorowany model uczenia się, aby przewidzieć wzrost osoby na podstawie jej wieku.
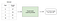
aby ponownie iterować, w ramach uczenia nadzorowanego istnieją dwie podkategorie: regresja i klasyfikacja.
regresja
w modelach regresji wyjście jest ciągłe. Poniżej znajdują się niektóre z najczęstszych typów modeli regresji.
regresja liniowa

ideą regresji liniowej jest po prostu znalezienie linii, która najlepiej pasuje do danych. Rozszerzenia regresji liniowej obejmują wielokrotną regresję liniową (np. znalezienie płaszczyzny najlepiej dopasowanej) i regresji wielomianowej (np. znalezienie krzywej najlepszego dopasowania). Możesz dowiedzieć się więcej o regresji liniowej w moim poprzednim artykule.
drzewo decyzyjne
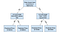
drzewa decyzyjne są popularnym modelem, używanym w badaniach operacyjnych, planowaniu strategicznym i uczeniu maszynowym. Każdy kwadrat powyżej nazywany jest węzłem, a im więcej węzłów masz, tym dokładniejsze będzie twoje drzewo decyzyjne (ogólnie). Ostatnie węzły drzewa decyzyjnego, w którym podejmowana jest decyzja, nazywane są liśćmi drzewa. Drzewa decyzyjne są intuicyjne i łatwe do zbudowania, ale pod względem dokładności są mało precyzyjne.
losowy Las
losowe lasy to technika uczenia się, która opiera się na drzewach decyzyjnych. Losowe lasy obejmują tworzenie wielu drzew decyzyjnych za pomocą bootstrapped zbiorów danych oryginalnych i losowo wybierając podzbiór zmiennych na każdym etapie drzewa decyzyjnego. Następnie model wybiera tryb wszystkich prognoz każdego drzewa decyzyjnego. Jaki to ma sens? Opierając się na modelu „większość wygrywa”, zmniejsza ryzyko błędu z pojedynczego drzewa.

na przykład, gdybyśmy utworzyli jedno drzewo decyzyjne, trzecie, przewidywałoby 0. Ale gdybyśmy polegali na trybie wszystkich 4 drzew decyzyjnych, przewidywana wartość wynosiłaby 1. To jest siła losowych lasów.
StatQuest wykonuje niesamowitą pracę, przechodząc przez to bardziej szczegółowo. Zobacz też
sieć neuronowa

sieć neuronowa jest zasadniczo siecią równań matematycznych. Pobiera jedną lub więcej zmiennych wejściowych, a przechodząc przez sieć równań, daje jedną lub więcej zmiennych wyjściowych. Można też powiedzieć, że sieć neuronowa przyjmuje wektor wejść i zwraca wektor wyjść, ale nie będę się w tym artykule rozwodził o macierzach.
niebieskie kółka reprezentują warstwę wejściową, czarne kółka reprezentują ukryte warstwy, a zielone kółka reprezentują warstwę wyjściową. Każdy węzeł w ukrytych warstwach reprezentuje zarówno funkcję liniową, jak i funkcję aktywacji, przez którą przechodzą węzły w poprzedniej warstwie, ostatecznie prowadząc do wyjścia w zielonych kółkach.
- Jeśli chcesz dowiedzieć się więcej na ten temat, sprawdź moje przyjazne dla początkujących Wyjaśnienie na temat sieci neuronowych.
Klasyfikacja
w modelach klasyfikacyjnych wyjście jest dyskretne. Poniżej znajdują się niektóre z najczęstszych typów modeli klasyfikacji.
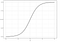
regresja logistyczna
regresja logistyczna jest podobna do regresji liniowej, ale jest używana do modelowania prawdopodobieństwa skończonej liczby wyników, zazwyczaj dwóch. Istnieje wiele powodów, dla których regresja logistyczna jest używana nad regresją liniową podczas modelowania prawdopodobieństwa wyników (patrz tutaj). W istocie, równanie logistyczne jest tworzone w taki sposób, że wartości wyjściowe mogą wynosić tylko od 0 do 1 (patrz poniżej).
maszyna wektorów wsparcia
maszyna wektorów wsparcia jest techniką nadzorowanej klasyfikacji, która może być dość skomplikowana, ale jest dość intuicyjna na najbardziej podstawowym poziomie.
Załóżmy, że istnieją dwie klasy danych. Maszyna wektorowa pomocnicza znajdzie hiperplanę lub granicę między dwiema klasami danych, która maksymalizuje margines między tymi dwiema klasami (patrz poniżej). Istnieje wiele płaszczyzn, które mogą oddzielić dwie klasy, ale tylko jedna płaszczyzna może zmaksymalizować margines lub odległość między klasami.

Jeśli chcesz uzyskać więcej szczegółów, Savan napisał świetny artykuł na temat maszyn wektorowych wsparcia tutaj.
Naive Bayes
Naive Bayes to kolejny popularny klasyfikator używany w naukach o danych. Jego ideą jest twierdzenie Bayesa:
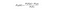
w prostym angielskim, równanie to jest używane do odpowiedzi na następujące pytanie. „Jakie jest prawdopodobieństwo y (moja zmienna wyjściowa) dla X? I z powodu naiwnego założenia, że zmienne są niezależne od danej klasy, można powiedzieć, że:

usuwając mianownik, możemy wtedy powiedzieć, że p(y/X) jest proporcjonalne do prawej strony.

dlatego celem jest znalezienie klasy y z maksymalnym proporcjonalnym prawdopodobieństwem.
Sprawdź mój artykuł „Matematyczne Wyjaśnienie naiwnych Bayesa”, jeśli chcesz bardziej dogłębnego wyjaśnienia!
drzewo decyzyjne, Las losowy, sieć neuronowa
te modele kierują się tą samą logiką, co wcześniej wyjaśniono. Jedyną różnicą jest to, że wyjście jest dyskretne, a nie ciągłe.
Nauka bez nadzoru

w przeciwieństwie do uczenia nadzorowanego, uczenie bez nadzoru jest używane do wyciągania wniosków i znajdowania wzorców z danych wejściowych bez odniesień do oznaczonych wyników. Dwie główne metody stosowane w nauczaniu bez nadzoru obejmują klastrowanie i redukcję wymiarowości.
grupowanie

klastrowanie jest techniką nienadzorowaną, która obejmuje grupowanie lub grupowanie punktów danych. Jest często używany do segmentacji klientów, wykrywania oszustw i klasyfikacji dokumentów.
typowe techniki klastrowania obejmują klastrowanie k-oznacza, klastrowanie hierarchiczne, klastrowanie średnich przesunięć i klastrowanie oparte na gęstości. Podczas gdy każda technika ma inną metodę znajdowania klastrów, wszystkie mają na celu osiągnięcie tego samego.
redukcja wymiarowości
redukcja wymiarowości jest procesem zmniejszania liczby zmiennych losowych pod uwagę poprzez uzyskanie zbioru zmiennych głównych . Mówiąc prościej, jest to proces zmniejszania wymiarów zestawu funkcji (jeszcze prościej, zmniejszanie liczby funkcji). Większość technik redukcji wymiarowości można sklasyfikować jako eliminację cech lub ekstrakcję cech.
popularna metoda redukcji wymiarowości nazywa się analizą głównych elementów.
analiza głównych składowych (PCA)
w najprostszym znaczeniu PCA obejmuje dane o wyższych wymiarach (np. 3 wymiary) do mniejszej przestrzeni (np. 2 wymiary). Skutkuje to niższym wymiarem danych (2 wymiary zamiast 3 wymiary) przy zachowaniu wszystkich oryginalnych zmiennych w modelu.
jest w tym sporo matematyki. Jeśli chcesz dowiedzieć się więcej na ten temat…
sprawdź ten niesamowity artykuł na temat PCA tutaj.
Jeśli wolisz obejrzeć film, StatQuest wyjaśnia PCA w 5 minut tutaj.
podsumowanie
oczywiście, jeśli zanurzysz się w konkretnym modelu, jest mnóstwo złożoności, ale powinno to dać ci fundamentalne zrozumienie, jak działa każdy algorytm uczenia maszynowego!
aby uzyskać więcej artykułów takich jak ten, sprawdź https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: a Modern Approach (2010), Prentice Hall
roweis, S. T., Saul, L. K., Nieliniowa redukcja wymiarowości poprzez lokalnie liniowe osadzanie (2000), Nauka