uma Aprendizagem mais Profunda para a Detecção de Pneumonia a partir de Imagens de raio-X
Um fim para fim de pipeline para pneumonia detecção de imagens de raio-X
Preso atrás do paywall? Clique aqui para ler a história completa com o Link do meu amigo!o risco de pneumonia é imenso para muitos, especialmente em países em desenvolvimento onde milhares de milhões enfrentam a pobreza energética e dependem de formas poluentes de energia. A OMS estima que mais de 4 milhões de mortes prematuras ocorrem anualmente devido a doenças relacionadas com a poluição atmosférica doméstica, incluindo pneumonia. Mais de 150 milhões de pessoas são infectadas com pneumonia numa base anual, especialmente crianças com menos de 5 anos de idade. Nestas regiões, o problema pode ser ainda agravado devido à escassez de recursos médicos e de pessoal. Por exemplo, nas 57 Nações Africanas, existe uma lacuna de 2,3 milhões de médicos e enfermeiros. Para estas populações, um diagnóstico rápido e preciso significa tudo. Pode garantir o acesso atempado ao tratamento e poupar tempo e dinheiro tão necessários para aqueles que já estão em situação de pobreza.
Este projecto faz parte das imagens de Raio-X ao tórax (Pneumonia) mantidas em Kaggle.Construa um algoritmo para identificar automaticamente se um doente sofre ou não de pneumonia através de imagens de raio-X ao tórax. O algoritmo tinha de ser extremamente preciso porque a vida das pessoas está em jogo.
Ambiente e ferramentas
- scikit-saiba mais
- keras
- numpy
- pandas
- matplotlib
Dados
O conjunto de dados pode ser transferido a partir do kaggle site, que pode ser encontrado aqui.
Onde está o código?
sem muito ado, vamos começar com o código. O projeto completo do github pode ser encontrado aqui.
vamos começar por carregar todas as bibliotecas e dependências.
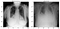
em seguida apresentadas algumas normal e pneumonia imagens basta dar uma olhada em quão diferente eles olhar para o olho nu. Bem, não muito!
em Seguida, dividir o conjunto de dados em três conjuntos — de trem, validação e conjuntos de teste.
Next I wrote a function in which I did some data augmentation, fed the training and test set images to the network. Também criei etiquetas para as imagens.
A prática de aumento de dados é uma maneira eficaz de aumentar o tamanho do conjunto de treinamento. O aumento dos exemplos de treinamento permite que a rede “veja” pontos de dados mais diversificados, mas ainda representativos durante o treinamento.
então eu defini um par de geradores de dados: um para dados de treinamento, e o outro para dados de validação. Um gerador de dados é capaz de carregar a quantidade necessária de dados (um mini lote de imagens) diretamente da pasta de origem, convertê — los em dados de treinamento (alimentado ao modelo) e alvos de treinamento (um vetor de atributos-o sinal de supervisão).
Para os meus experimentos, eu costumo definir o
batch_size = 64. Em geral, um valor entre 32 e 128 deve funcionar bem. Normalmente você deve aumentar / diminuir o tamanho do lote de acordo com os recursos computacionais e performances do modelo.
Depois que eu definidas algumas constantes para uso posterior.
O próximo passo foi construir o modelo. Isto pode ser descrito nos 5 passos seguintes.
- I used five convolucional blocks comprised of convolucional layer, max-pooling and batch-normalization.
- em cima dele eu usei uma camada achatada e seguido por quatro camadas totalmente conectadas.
- Também no meio eu usei desistências para reduzir o excesso de ajuste.
- A função de ativação foi Relu toda, exceto para a última camada onde era Sigmoid como este é um problema de classificação binária.eu tenho usado Adam como o otimizador e cross-entropia como a perda.
antes da formação, o modelo é útil para definir um ou mais callbacks. Muito útil, são: ModelCheckpoint e EarlyStopping.
- ModelCheckpoint: quando o treinamento requer muito tempo para alcançar um bom resultado, muitas vezes, muitas iterações são necessárias. Neste caso, é melhor salvar uma cópia do modelo de melhor desempenho apenas quando uma época que melhora as métricas termina.
- EarlyStopping: às vezes, durante o treinamento, podemos notar que a diferença de generalização (ou seja, a diferença entre o erro de treinamento e validação) começa a aumentar, em vez de diminuir. Este é um sintoma de excesso de ajuste que pode ser resolvido de muitas maneiras (redução da capacidade do modelo, aumento dos dados de treinamento, aumento de dados, regularização, desistência, etc). Muitas vezes, uma solução prática e eficiente é parar de treinar quando a lacuna de generalização está piorando.

em seguida, treinou o modelo para 10 épocas, com um tamanho de lote de 32. Por favor, note que normalmente um maior tamanho de lote dá melhores resultados, mas à custa de maiores encargos computacionais. Algumas pesquisas também afirmam que há um tamanho de lote ideal para melhores resultados que poderiam ser encontrados investindo algum tempo em ajuste de hiper-parâmetro.
Vamos visualizar a perda e a precisão parcelas.

até aí tudo bem. O modelo está convergindo que pode ser observado a partir da diminuição na perda e perda de validação com epochs. Também é capaz de alcançar 90% de precisão de validação em apenas 10 epochs.
vamos traçar a matriz de confusão e obter alguns dos outros resultados também como precisão, recall, pontuação F1 e precisão.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
O modelo é capaz de alcançar uma precisão de 91.02%, o que é muito bom considerando-se o tamanho dos dados que é usado.
conclusões
embora este projecto esteja longe de estar completo, é notável ver o sucesso da aprendizagem profunda em problemas tão variados do mundo real. Eu demonstrei como classificar dados positivos e negativos de pneumonia a partir de uma coleção de imagens de raio-X. O modelo foi feito a partir do zero, o que o separa de outros métodos que dependem fortemente da abordagem de transferência de aprendizagem. No futuro, este trabalho poderia ser estendido para detectar e classificar imagens de raios-X consistindo de câncer de pulmão e pneumonia. A identificação de imagens de raios-X que contêm cancro do pulmão e pneumonia tem sido um grande problema nos últimos tempos, e a nossa próxima abordagem deve ser a de resolver este problema.