învățare profundă pentru detectarea pneumoniei din imaginile cu raze X
o conductă de capăt la capăt pentru detectarea pneumoniei din imaginile cu raze X
blocat în spatele paywall? Click aici pentru a citi povestea completă cu prietenul meu Link!
riscul de pneumonie este imens pentru mulți, în special în țările în curs de dezvoltare, unde miliarde se confruntă cu sărăcia energetică și se bazează pe forme poluante de energie. OMS estimează că peste 4 milioane de decese premature apar anual din cauza bolilor legate de poluarea aerului din gospodărie, inclusiv pneumonia. Peste 150 de milioane de persoane se infectează anual cu pneumonie, în special copiii sub 5 ani. În astfel de regiuni, problema poate fi agravată și mai mult din cauza lipsei resurselor medicale și a personalului. De exemplu, în cele 57 de națiuni din Africa, există un decalaj de 2,3 milioane de medici și asistente medicale. Pentru aceste populații, diagnosticul precis și rapid înseamnă totul. Acesta poate garanta accesul în timp util la tratament și poate economisi timp și bani atât de necesari pentru cei care se confruntă deja cu sărăcia.
Acest proiect face parte din imaginile cu raze X toracice (pneumonie) ținute pe Kaggle.
construiți un algoritm pentru a identifica automat dacă un pacient suferă de pneumonie sau nu, uitându-se la imaginile cu raze X toracice. Algoritmul trebuia să fie extrem de precis, deoarece viața oamenilor este în joc.
mediu și instrumente
- scikit-learn
- keras
- NumPy
- panda
- matplotlib
date
setul de date poate fi descărcat de pe site-ul web Kaggle, care poate fi găsit aici.
unde este codul?
fără prea mult zgomot, să începem cu codul. Proiectul complet pe github poate fi găsit aici.
să începem cu încărcarea tuturor bibliotecilor și dependențelor.
apoi am afișat câteva imagini normale și pneumonie pentru a avea doar o privire la cât de diferite arată de la ochiul liber. Ei bine, nu de mult!
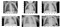
exemple de imagini
apoi am împărțit setul de date în trei seturi-seturi de tren, validare și testare.
apoi am scris o funcție în care am făcut unele augmentare de date, alimentat de formare și de testare Set imagini în rețea. De asemenea, am creat etichete pentru imagini.
practica augmentării datelor este o modalitate eficientă de a crește dimensiunea setului de instruire. Augmentarea exemplelor de instruire permite rețelei să „vadă” puncte de date mai diversificate, dar totuși reprezentative, în timpul antrenamentului.
apoi am definit câteva generatoare de date: unul pentru datele de instruire și celălalt pentru datele de validare. Un generator de date este capabil să încarce cantitatea necesară de date (un mini lot de imagini) direct din folderul sursă, să le transforme în date de antrenament (alimentate la model) și ținte de antrenament (un vector de atribute — semnalul de supraveghere).
pentru experimentele mele, setez de obicei
batch_size = 64. În general, o valoare cuprinsă între 32 și 128 ar trebui să funcționeze bine. De obicei, ar trebui să crească/micșora dimensiunea lotului în funcție de resursele de calcul și performanțele modelului.
după aceea am definit câteva constante pentru utilizare ulterioară.
următorul pas a fost construirea modelului. Acest lucru poate fi descris în următorii 5 pași.
- am folosit cinci blocuri convolutionale compuse din strat convolutional, max-pooling si batch-normalizare.
- deasupra am folosit un strat aplatizat și l-am urmat de patru straturi complet conectate.
- De asemenea, între Am folosit abandonul pentru a reduce supra-montarea.
- funcția de activare a fost Relu pe tot parcursul, cu excepția ultimului strat în care a fost Sigmoid, deoarece aceasta este o problemă de clasificare binară.
- am folosit Adam ca optimizator și entropia încrucișată ca pierdere.
înainte de antrenament modelul este util pentru a defini unul sau mai multe callback-uri. Destul de la îndemână, sunt: ModelCheckpoint și EarlyStopping.
- ModelCheckpoint: când antrenamentul necesită mult timp pentru a obține un rezultat bun, adesea sunt necesare multe iterații. În acest caz, este mai bine să salvați o copie a modelului cel mai performant numai atunci când se termină o epocă care îmbunătățește valorile.
- EarlyStopping: uneori, în timpul antrenamentului putem observa că decalajul de generalizare (adică diferența dintre eroare de antrenament și validare) începe să crească, în loc să scadă. Acesta este un simptom al suprasolicitării care poate fi rezolvat în mai multe moduri (reducerea capacității modelului, creșterea datelor de antrenament, Augumentarea datelor, regularizarea, abandonul etc.). Adesea, o soluție practică și eficientă este oprirea antrenamentului atunci când decalajul de generalizare se înrăutățește.

oprire timpurie
în continuare am pregătit modelul pentru 10 epoci cu o dimensiune a lotului de 32. Vă rugăm să rețineți că, de obicei, o dimensiune mai mare a lotului oferă rezultate mai bune, dar în detrimentul unei sarcini de calcul mai mari. Unele cercetări susțin, de asemenea, că există o dimensiune optimă a lotului pentru cele mai bune rezultate, care ar putea fi găsite investind ceva timp în reglarea hiper-parametrilor.
să vizualizăm parcelele de pierdere și precizie.

până acum atât de bine. Modelul este convergent, care poate fi observat din scăderea pierderii și a pierderii de validare cu epoci. De asemenea, este capabil să atingă o precizie de validare de 90% în doar 10 epoci.
să complot matricea confuzie și a obține unele dintre celelalte rezultate, de asemenea, cum ar fi de precizie, rechemare, scor F1 și precizie.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
modelul este capabil să obțină o precizie de 91,02%, ceea ce este destul de bun având în vedere dimensiunea datelor utilizate.
concluzii
deși acest proiect este departe de a fi complet, dar este remarcabil să vedem succesul învățării profunde în astfel de probleme variate din lumea reală. Am demonstrat cum să clasific datele pozitive și negative despre pneumonie dintr-o colecție de imagini cu raze X. Modelul a fost realizat de la zero, ceea ce îl separă de alte metode care se bazează foarte mult pe abordarea învățării prin transfer. În viitor, această lucrare ar putea fi extinsă pentru a detecta și clasifica imaginile cu raze X constând în cancer pulmonar și pneumonie. Distingerea imaginilor cu raze X care conțin cancer pulmonar și pneumonie a fost o problemă importantă în ultima vreme, iar următoarea noastră abordare ar trebui să fie abordarea acestei probleme.