toate modelele de învățare automată explicate în 6 minute
explicații Intuitive ale celor mai populare modele de învățare automată.

în articolul meu anterior, am explicat ce a fost regresia și am arătat cum ar putea fi utilizată în aplicație. În această săptămână, voi trece în revistă majoritatea modelelor obișnuite de învățare automată utilizate în practică, astfel încât să pot petrece mai mult timp construind și îmbunătățind modele, mai degrabă decât explicând teoria din spatele lor. Să ne scufundăm în ea.

segmentarea fundamentală a Modele de învățare automată
toate modelele de învățare automată sunt clasificate fie ca supravegheate, fie nesupravegheate. Dacă modelul este un model supravegheat, acesta este apoi subcategorizat fie ca model de regresie, fie ca model de clasificare. Vom trece în revistă ce înseamnă acești Termeni și modelele corespunzătoare care se încadrează în fiecare categorie de mai jos.
învățarea supravegheată implică învățarea unei funcții care mapează o intrare la o ieșire bazată pe Exemple de perechi intrare-ieșire .
de exemplu, dacă aș avea un set de date cu două variabile, vârsta (intrare) și înălțimea (ieșire), aș putea implementa un model de învățare supravegheat pentru a prezice înălțimea unei persoane în funcție de vârsta sa.
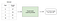
exemplu de învățare supravegheată
pentru a repeta, în cadrul învățării supravegheate, există două subcategorii: regresie și clasificare.
regresie
în modelele de regresie, ieșirea este continuă. Mai jos sunt câteva dintre cele mai frecvente tipuri de modele de regresie.
regresie liniară

ideea de regresie liniară este pur și simplu găsirea unei linii care se potrivește cel mai bine datelor. Extensiile regresiei liniare includ regresia liniară multiplă (de ex. găsirea unui plan de cea mai bună potrivire) și regresie polinomială (de ex. găsirea unei curbe de cea mai bună potrivire). Puteți afla mai multe despre regresia liniară în articolul meu anterior.
Arborele decizional
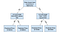
>
arborii de decizie sunt un model popular, utilizat în cercetarea operațională, planificarea strategică și învățarea automată. Fiecare pătrat de mai sus se numește nod și cu cât aveți mai multe noduri, cu atât arborele dvs. de decizie va fi (în general) mai precis. Ultimele noduri ale arborelui de decizie, unde se ia o decizie, se numesc frunzele copacului. Arborii de decizie sunt intuitivi și ușor de construit, dar se încadrează scurt atunci când vine vorba de precizie.
pădure aleatoare
pădurile aleatoare sunt o tehnică de învățare ansamblu care se bazează pe arbori de decizie. Pădurile aleatorii implică crearea mai multor arbori de decizie folosind seturi de date bootstrapate ale datelor originale și selectarea aleatorie a unui subset de variabile la fiecare pas al arborelui de decizie. Modelul selectează apoi modul tuturor predicțiilor fiecărui arbore de decizie. Ce rost are asta? Bazându-se pe un model” majoritatea câștigă”, reduce riscul de eroare de la un arbore individual.

de exemplu, dacă am crea un arbore de decizie, al treilea, ar prezice 0. Dar dacă ne-am baza pe modul tuturor celor 4 arbori de decizie, valoarea prezisă ar fi 1. Aceasta este puterea pădurilor aleatorii.
StatQuest face o treabă uimitoare de mers pe jos prin acest detaliu mai mare. Vezi AICI.
rețea neuronală

vizual reprezentarea unei rețele neuronale
o rețea neuronală este în esență o rețea de ecuații matematice. Este nevoie de una sau mai multe variabile de intrare și, trecând printr-o rețea de ecuații, rezultă una sau mai multe variabile de ieșire. De asemenea, puteți spune că o rețea neuronală preia un vector de intrări și returnează un vector de ieșiri, dar nu voi intra în matrice în acest articol.
cercurile albastre reprezintă stratul de intrare, cercurile negre reprezintă straturile ascunse, iar cercurile verzi reprezintă stratul de ieșire. Fiecare nod din straturile ascunse reprezintă atât o funcție liniară, cât și o funcție de activare prin care trec nodurile din stratul anterior, ducând în cele din urmă la o ieșire în cercurile verzi.
- dacă doriți să aflați mai multe despre aceasta, consultați explicația mea prietenoasă pentru începători pe rețelele neuronale.
clasificare
în modelele de clasificare, ieșirea este discretă. Mai jos sunt câteva dintre cele mai comune tipuri de modele de clasificare.
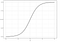
regresia logistică
regresia logistică este similară cu regresia liniară, dar este utilizată pentru a modela probabilitatea unui număr finit de rezultate, de obicei două. Există o serie de motive pentru care regresia logistică este utilizată peste regresia liniară la modelarea probabilităților rezultatelor (vezi AICI). În esență, o ecuație logistică este creată în așa fel încât valorile de ieșire să poată fi doar între 0 și 1 (vezi mai jos).
mașină vector suport
o mașină vector suport este o tehnică de clasificare supravegheată, care poate obține de fapt destul de complicat, dar este destul de intuitiv la nivelul cel mai fundamental.
Să presupunem că există două clase de date. O mașină vectorială de sprijin va găsi un hiperplan sau o limită între cele două clase de date care maximizează marja dintre cele două clase (vezi mai jos). Există multe planuri care pot separa cele două clase, dar un singur plan poate maximiza marja sau distanța dintre clase.

dacă doriți să intrați în detalii mai mari, Savan a scris aici un articol minunat despre mașinile vectoriale de sprijin.
Bayes naiv
Bayes naiv este un alt clasificator popular folosit în știința datelor. Ideea din spatele ei este condusă de teorema lui Bayes:
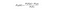
în engleză simplă, Această ecuație este utilizată pentru a răspunde la următoarea întrebare. „Care este probabilitatea ca y (variabila mea de ieșire) să fie dată de X? Și din cauza presupunerii naive că variabilele sunt independente având în vedere clasa, puteți spune că:

de asemenea, prin eliminarea numitorului, putem spune că p(y / x) este proporțional cu partea dreaptă.

prin urmare, scopul este de a găsi clasa Y cu probabilitatea proporțională maximă.
Check out articolul meu” o explicație matematică a Bayes naiv”, dacă doriți o explicație mai în profunzime!
arborele de decizie, Pădurea aleatorie, rețeaua neuronală
aceste modele urmează aceeași logică ca cea explicată anterior. Singura diferență este că această ieșire este mai degrabă discretă decât continuă.
învățare nesupravegheată

spre deosebire de învățarea supravegheată, învățarea nesupravegheată este utilizată pentru a trage inferențe și a găsi modele din datele de intrare fără referințe la rezultatele etichetate. Două metode principale utilizate în învățarea nesupravegheată includ clustering și reducerea dimensionalității.
Clustering

preluat din GeeksforGeeks
clustering este o tehnică nesupravegheată care implică gruparea sau gruparea punctelor de date. Este frecvent utilizat pentru segmentarea clienților, detectarea fraudelor și clasificarea documentelor.
tehnicile comune de grupare includ K-înseamnă clustering, clustering ierarhic, clustering cu deplasare medie și clustering bazat pe densitate. În timp ce fiecare tehnică are o metodă diferită în găsirea clusterelor, toate își propun să realizeze același lucru.
reducerea dimensionalității
reducerea dimensionalității este procesul de reducere a numărului de variabile aleatorii luate în considerare prin obținerea unui set de variabile principale . În termeni simpli, este procesul de reducere a dimensiunii setului de caracteristici (în termeni și mai simpli, reducerea numărului de caracteristici). Majoritatea tehnicilor de reducere a dimensionalității pot fi clasificate fie ca eliminarea caracteristicilor, fie ca extragerea caracteristicilor.
o metodă populară de reducere a dimensionalității se numește analiza componentelor principale.
analiza componentelor principale (PCA)
în cel mai simplu sens, PCA implică date de dimensiuni superioare ale proiectului (de ex. 3 dimensiuni) într-un spațiu mai mic (de ex. 2 dimensiuni). Aceasta are ca rezultat o dimensiune mai mică a datelor, (2 dimensiuni în loc de 3 dimensiuni) păstrând în același timp toate variabilele originale din model.
există destul de un pic de matematica implicat în acest sens. Dacă doriți să aflați mai multe despre el…
Check out acest articol minunat pe PCA aici.
dacă preferați să vizionați un videoclip, StatQuest explică PCA în 5 minute aici.
concluzie
evident, există o mulțime de complexitate dacă vă scufundați într-un anumit model, dar acest lucru ar trebui să vă ofere o înțelegere fundamentală a modului în care funcționează fiecare algoritm de învățare automată!
pentru mai multe articole ca acesta, consultați https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (2010), Prentice Hall
roweis, S. T., Saul, L. K., Reducerea dimensionalității neliniare prin încorporarea liniară locală (2000), știință