Alle Modelle des maschinellen Lernens in 6 Minuten erklärt
Intuitive Erklärungen der beliebtesten Modelle des maschinellen Lernens.

In meinem vorherigen Artikel habe ich erklärt, was Regression ist, und gezeigt, wie sie in der Anwendung verwendet werden kann. Diese Woche werde ich die meisten gängigen Modelle für maschinelles Lernen durchgehen, die in der Praxis verwendet werden, damit ich mehr Zeit damit verbringen kann, Modelle zu erstellen und zu verbessern, anstatt die Theorie dahinter zu erklären. Lass uns eintauchen.

Alle Modelle des maschinellen Lernens werden entweder als überwacht oder unbeaufsichtigt kategorisiert. Wenn es sich bei dem Modell um ein überwachtes Modell handelt, wird es entweder als Regressions- oder Klassifizierungsmodell unterkategorisiert. Wir gehen darauf ein, was diese Begriffe bedeuten und die entsprechenden Modelle, die in jede Kategorie fallen.
Überwachtes Lernen beinhaltet das Erlernen einer Funktion, die eine Eingabe basierend auf beispielhaften Eingabe-Ausgabe-Paaren einer Ausgabe zuordnet .Wenn ich beispielsweise einen Datensatz mit zwei Variablen hätte, Alter (Eingabe) und Größe (Ausgabe), könnte ich ein überwachtes Lernmodell implementieren, um die Größe einer Person basierend auf ihrem Alter vorherzusagen.
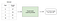
Um das überwachte Lernen zu wiederholen, gibt es zwei Unterkategorien: Regression und Klassifikation.
Regression
In Regressionsmodellen ist die Ausgabe kontinuierlich. Im Folgenden finden Sie einige der häufigsten Arten von Regressionsmodellen.
Lineare Regression

Die Idee der linearen Regression besteht einfach darin, eine Linie zu finden, die am besten zu den Daten passt. Erweiterungen der linearen Regression umfassen multiple lineare Regression (zB. finden einer Ebene der besten Passform) und Polynomregression (zB. finden einer Kurve der besten Passform). Sie können mehr über die lineare Regression in meinem vorherigen Artikel erfahren.
Entscheidungsbaum
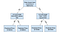
Entscheidungsbäume sind ein beliebtes Modell, das in Operations Research, strategischer Planung und maschinellem Lernen verwendet wird. Jedes Quadrat oben wird als Knoten bezeichnet, und je mehr Knoten Sie haben, desto genauer ist Ihr Entscheidungsbaum (im Allgemeinen). Die letzten Knoten des Entscheidungsbaums, an denen eine Entscheidung getroffen wird, werden als Blätter des Baumes bezeichnet. Entscheidungsbäume sind intuitiv und einfach zu bauen, aber zu kurz, wenn es um Genauigkeit geht.
Random Forest
Random Forests sind eine Ensemble-Lerntechnik, die auf Entscheidungsbäumen aufbaut. Zufällige Gesamtstrukturen umfassen das Erstellen mehrerer Entscheidungsbäume unter Verwendung von Bootstrap-Datasets der Originaldaten und das zufällige Auswählen einer Teilmenge von Variablen in jedem Schritt des Entscheidungsbaums. Das Modell wählt dann den Modus aller Vorhersagen jedes Entscheidungsbaums aus. Was ist der Sinn davon? Indem es sich auf ein „Majority Wins“ -Modell verlässt, reduziert es das Fehlerrisiko eines einzelnen Baumes.

Für wenn wir beispielsweise einen Entscheidungsbaum erstellen, den dritten, würde er 0 vorhersagen. Wenn wir uns jedoch auf den Modus aller 4 Entscheidungsbäume verlassen würden, wäre der vorhergesagte Wert 1. Das ist die Kraft von Random Forests.
StatQuest macht einen erstaunlichen Job, indem es dies detaillierter durchläuft. Siehe hier.
Neuronales Netzwerk

Ein Neuronales Netzwerk ist im Wesentlichen ein Netzwerk mathematischer Gleichungen. Es benötigt eine oder mehrere Eingangsvariablen und führt durch ein Netzwerk von Gleichungen zu einer oder mehreren Ausgangsvariablen. Sie können auch sagen, dass ein neuronales Netzwerk einen Vektor von Eingaben aufnimmt und einen Vektor von Ausgaben zurückgibt, aber ich werde in diesem Artikel nicht auf Matrizen eingehen.
Die blauen Kreise repräsentieren die Eingabeebene, die schwarzen Kreise die ausgeblendeten Ebenen und die grünen Kreise die Ausgabeebene. Jeder Knoten in den ausgeblendeten Ebenen stellt sowohl eine lineare Funktion als auch eine Aktivierungsfunktion dar, die die Knoten in der vorherigen Ebene durchlaufen, was letztendlich zu einer Ausgabe in den grünen Kreisen führt.
- Wenn Sie mehr darüber erfahren möchten, lesen Sie meine anfängerfreundliche Erklärung zu neuronalen Netzen.
Klassifikation
In Klassifikationsmodellen ist die Ausgabe diskret. Im Folgenden sind einige der häufigsten Arten von Klassifikationsmodellen aufgeführt.
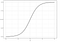
Logistische Regression
Die logistische Regression ähnelt der linearen Regression, wird jedoch verwendet, um die Wahrscheinlichkeit einer endlichen Anzahl von Ergebnissen, typischerweise zwei, zu modellieren. Es gibt eine Reihe von Gründen, warum die logistische Regression bei der Modellierung von Wahrscheinlichkeiten von Ergebnissen gegenüber der linearen Regression verwendet wird (siehe hier ). Im Wesentlichen wird eine logistische Gleichung so erstellt, dass die Ausgabewerte nur zwischen 0 und 1 liegen können (siehe unten).
Support Vector Machine
Eine Support Vector Machine ist eine überwachte Klassifizierungstechnik, die eigentlich ziemlich kompliziert werden kann, aber auf der grundlegendsten Ebene ziemlich intuitiv ist.
Nehmen wir an, es gibt zwei Klassen von Daten. Eine Support-Vektor-Maschine findet eine Hyperebene oder eine Grenze zwischen den beiden Datenklassen, die den Abstand zwischen den beiden Klassen maximiert (siehe unten). Es gibt viele Ebenen, die die beiden Klassen trennen können, aber nur eine Ebene kann den Rand oder Abstand zwischen den Klassen maximieren.

Savan hat hier einen großartigen Artikel über Support Vector Machines geschrieben.
Naive Bayes
Naive Bayes ist ein weiterer beliebter Klassifikator, der in der Datenwissenschaft verwendet wird. Die Idee dahinter wird vom Bayes-Theorem angetrieben:
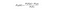
Im Klartext wird diese Gleichung verwendet, um beantworten Sie die folgende Frage. „Wie hoch ist die Wahrscheinlichkeit von y (meiner Ausgabevariablen) bei X? Und wegen der naiven Annahme, dass Variablen unabhängig von der Klasse sind, können Sie das sagen:

Durch Entfernen des Nenners, wir können dann sagen, dass P (y | X) proportional zur rechten Seite ist.

lasse y mit der maximalen proportionalen Wahrscheinlichkeit.
Schauen Sie sich meinen Artikel „A Mathematical Explanation of Naive Bayes“ an, wenn Sie eine ausführlichere Erklärung wünschen!
Entscheidungsbaum, Random Forest, Neuronales Netzwerk
Diese Modelle folgen der gleichen Logik wie zuvor erläutert. Der einzige Unterschied besteht darin, dass diese Ausgabe eher diskret als kontinuierlich ist.
Unbeaufsichtigtes Lernen

Im Gegensatz zum überwachten Lernen wird das unüberwachte Lernen verwendet, um Rückschlüsse zu ziehen und Muster aus Eingabedaten zu finden, ohne auf markierte Ergebnisse zu verweisen. Zwei Hauptmethoden, die beim unbeaufsichtigten Lernen verwendet werden, umfassen Clustering und Dimensionsreduktion.
Clustering

Clustering ist eine unbeaufsichtigte Technik, bei der Datenpunkte gruppiert oder gruppiert werden. Es wird häufig zur Kundensegmentierung, Betrugserkennung und Dokumentenklassifizierung verwendet.Zu den gängigen Clustertechniken gehören k-Means-Clustering, hierarchisches Clustering, Mean Shift-Clustering und dichtebasiertes Clustering. Während jede Technik eine andere Methode zum Finden von Clustern hat, zielen alle darauf ab, dasselbe zu erreichen.
Dimensionalitätsreduktion
Dimensionalitätsreduktion ist der Prozess der Verringerung der Anzahl der betrachteten Zufallsvariablen durch Erhalten eines Satzes von Hauptvariablen . In einfacheren Worten, es ist der Prozess der Verringerung der Dimension Ihres Feature-Set (in noch einfacheren Worten, die Verringerung der Anzahl der Features). Die meisten Techniken zur Reduzierung der Dimensionalität können entweder als Merkmaleliminierung oder Merkmalsextraktion kategorisiert werden.
Eine beliebte Methode zur Reduzierung der Dimensionalität wird als Hauptkomponentenanalyse bezeichnet.
Principal Component Analysis (PCA)
Im einfachsten Sinne beinhaltet PCA Projekt höherdimensionale Daten (zB. 3 dimensionen) auf einen kleineren Raum (z.B. 2 abmessungen). Dies führt zu einer geringeren Datendimension (2 Dimensionen anstelle von 3 Dimensionen), während alle ursprünglichen Variablen im Modell beibehalten werden.
Es ist ziemlich viel Mathematik damit verbunden. Wenn Sie mehr darüber erfahren möchten …
Lesen Sie diesen fantastischen Artikel über PCA hier.
Wenn Sie lieber ein Video ansehen möchten, erklärt StatQuest PCA in 5 Minuten hier.
Fazit
Natürlich gibt es eine Menge Komplexität, wenn Sie in ein bestimmtes Modell eintauchen, aber dies sollte Ihnen ein grundlegendes Verständnis dafür vermitteln, wie jeder Algorithmus für maschinelles Lernen funktioniert!
Weitere Artikel wie diesen finden Sie unter https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Künstliche Intelligenz: Ein moderner Ansatz (2010), Prentice Hall
Roweis, S. T. , Saul, L. K., Nichtlineare Dimensionsreduktion durch lokal lineare Einbettung (2000), Wissenschaft