kaikki Koneoppimismallit selitetty 6 minuutissa
suosituimpien koneoppimismallien intuitiiviset selitykset.

edellisessä kirjoituksessani selitin, mitä regressio on ja Näytin, miten sitä voidaan käyttää soveltamisessa. Tällä viikolla aion käydä läpi suurimman osan käytännössä käytetyistä koneoppimismalleista, jotta voin käyttää enemmän aikaa mallien rakentamiseen ja parantamiseen sen takana olevan teorian selittämisen sijaan. Sukelletaan siihen.

kaikki koneoppimismallit luokitellaan joko valvotuiksi tai valvomattomiksi. Jos malli on valvottu malli, se aliluokitellaan joko regressio-tai luokittelumalliksi. Käymme läpi, mitä nämä termit tarkoittavat ja vastaavat mallit, jotka kuuluvat kuhunkin luokkaan alla.
valvotussa oppimisessa on kyse sellaisen funktion oppimisesta, joka kartoittaa esimerkiksi tulo-ulostulo-parien perusteella tuotoksen .
esimerkiksi, jos minulla olisi tietojoukko, jossa olisi kaksi muuttujaa, Ikä (Tulo) ja korkeus (lähtö), voisin toteuttaa ohjatun oppimismallin ennustamaan henkilön pituuden heidän ikänsä perusteella.
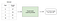
uudelleen iteroimiseksi valvotussa oppimisessa on kaksi alaluokkaa: regressio ja luokittelu.
regressio
regressiomalleissa lähtö on jatkuva. Alla on joitakin yleisimpiä regressiomalleja.
lineaarinen regressio

div>
lineaarisen regression idea on yksinkertaisesti löytää viiva, joka sopii parhaiten aineistoon. Lineaarisen regression laajennuksia ovat moninkertaiset lineaariset regressiot (esim. löytää taso parhaiten sovi) ja polynomi regressio (esim. parhaan istuvuuden käyrän löytäminen). Voit oppia lisää lineaarinen regressio minun edellinen artikkeli.
Ratkaisupuu
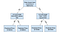
päätöksentekopuut ovat suosittu malli, jota käytetään operaatiotutkimuksessa, strategisessa suunnittelussa ja koneoppimisessa. Jokaista yllä olevaa neliötä kutsutaan solmuksi, ja mitä enemmän solmuja sinulla on, sitä tarkempi päätöksentekopuusi on (yleensä). Ratkaisupuun viimeisiä solmuja, joissa päätös tehdään, kutsutaan puun lehdiksi. Päätöksentekopuut ovat intuitiivisia ja helppoja rakentaa, mutta ne eivät ole tarkkoja.
Satunnaismetsät
Satunnaismetsät ovat ratkaisupuista rakentuva oppimistekniikka. Satunnaismetsissä luodaan useita päätöspuita käyttäen bootstrapattuja tietokokonaisuuksia alkuperäisestä datasta ja valitaan satunnaisesti muuttujien osajoukko päätöksentekopuun jokaisessa vaiheessa. Tämän jälkeen malli valitsee kunkin ratkaisupuun kaikkien ennusteiden moodin. Mitä järkeä tässä on? Luottamalla ”enemmistö voittaa” – malliin se vähentää yksittäisen puun virheriskiä.

esimerkiksi jos loisimme yhden ratkaisupuun, kolmannen, se ennustaisi 0. Mutta jos luotamme tilassa kaikkien 4 päätöksen puita, ennustettu arvo olisi 1. Tämä on satunnaismetsien voima.
StatQuest tekee hämmästyttävää työtä kävellessään tämän tarkemmin läpi. Katso.
neuroverkko

neuroverkko on olennaisesti matemaattisten yhtälöiden verkosto. Siihen tarvitaan yksi tai useampi tulomuuttuja, ja käymällä läpi yhtälöiden verkoston, tuloksena on yksi tai useampi lähtömuuttuja. Voidaan myös sanoa, että neuroverkko ottaa sisään tulovektorin ja palauttaa ulostulovektorin, mutta en mene matriiseihin tässä artikkelissa.
siniset ympyrät edustavat tulokerrosta, mustat ympyrät piilokerroksia ja vihreät ympyrät ulostulokerrosta. Jokainen piilokerrosten solmu edustaa sekä lineaarista funktiota että aktivointifunktiota, jonka edellisen kerroksen solmut käyvät läpi johtaen lopulta lähtöön vihreissä ympyröissä.
- Jos haluat oppia siitä lisää, tutustu aloittelijaystävälliseen selitykseeni neuroverkoista.
luokitus
luokitusmalleissa lähtö on diskreetti. Alla on joitakin yleisimpiä luokittelumalleja.
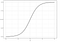
logistinen regressio
logistinen regressio on samankaltainen kuin lineaarinen regressio, mutta sitä käytetään mallintamaan äärellisen määrän, tyypillisesti kahden lopputuloksen todennäköisyyttä. On useita syitä, miksi logistista regressiota käytetään lineaarisen regression sijaan mallintettaessa tulosten todennäköisyyksiä (Katso tästä). Pohjimmiltaan logistinen yhtälö luodaan siten, että lähtöarvot voivat olla vain välillä 0 ja 1 (katso alla).
tukivektorikone
tukivektorikone on valvottu luokittelutekniikka, joka voi itse asiassa muuttua melko monimutkaiseksi, mutta on perustasolla melko intuitiivinen.
oletetaan, että aineistoja on kaksi luokkaa. Tukivektorikone löytää hypertason tai rajan kahden dataluokan välille, joka maksimoi näiden kahden luokan välisen marginaalin (katso alla). On olemassa monia lentokoneita, jotka voivat erottaa kaksi luokkaa, mutta vain yksi taso voi maksimoida marginaali tai etäisyys luokkien välillä.

Jos haluat syventyä tarkemmin, Savan kirjoitti hienon artikkelin tukivektorikoneista tähän.
naiivi Bayes
naiivi Bayes on toinen Datatieteessä käytetty suosittu luokittelija. Idean takana on Bayesin lause:
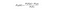
selkokielellä tätä yhtälöä käytetään vastaamaan seuraavaan kysymykseen. ”Mikä on todennäköisyys y (minun lähtömuuttuja) annetaan X? Ja koska naiivi oletus, että muuttujat ovat riippumattomia, kun otetaan huomioon luokka, voidaan sanoa, että:

myös poistamalla nimittäjä voidaan sanoa, että P(Y/X) on verrannollinen oikeanpuoleiseen.

näin ollen tavoitteena on löytää luokka y suurimmalla suhteellisella todennäköisyydellä.
Tsekkaa artikkelini ”A Mathematical Explanation of naiivi Bayes”, jos haluat syvällisemmän selityksen!
päätöspuu, Satunnaismetsä, neuroverkko
nämä mallit noudattavat samaa logiikkaa kuin aiemmin on selitetty. Ainoa ero on, että tuotos on diskreetti eikä jatkuva.
valvomaton oppiminen

toisin kuin valvotussa oppimisessa, valvomattomassa oppimisessa käytetään päätelmien tekemistä ja mallien löytämistä syöttötiedoista ilman viittauksia merkittyihin tuloksiin. Valvomattoman oppimisen kaksi pääasiallista menetelmää ovat klusterointi ja dimensionalismin vähentäminen.
ryhmittely

clustering on valvomaton tekniikka, jossa ryhmitellään eli ryhmitellään datapisteitä. Sitä käytetään usein asiakkaiden segmentointiin, petosten havaitsemiseen ja asiakirjojen luokitteluun.
yleisiä ryhmittelytekniikoita ovat k-means-ryhmittely, hierarkkinen ryhmittely, mean shift-ryhmittely ja tiheyteen perustuva ryhmittely. Vaikka jokaisella tekniikalla on erilainen tapa löytää klustereita, ne kaikki pyrkivät samaan.
Dimensionaalisuuden pieneneminen
Dimensionaalisuuden pieneneminen on prosessi, jossa tarkasteltavana olevien satunnaismuuttujien määrää vähennetään hankkimalla joukko päämuuttujia . Yksinkertaisemmin, sen prosessi vähentää ulottuvuuden ominaisuuskokonaisuuden (vielä yksinkertaisemmin, vähentää ominaisuuksien määrää). Useimmat dimensionaalisuuden vähentämistekniikat voidaan luokitella joko ominaisuuksien poistoon tai ominaisuuksien poistoon.
suosittua dimensionaalisuuden vähentämismenetelmää kutsutaan pääkomponenttianalyysiksi.
pääkomponenttianalyysi (PCA)
yksinkertaisimmassa merkityksessä PCA sisältää projektin korkeamman dimensionaalisen datan (esim. 3 mitat) pienempään tilaan (esim. 2 mitat). Tämä johtaa datan pienempään ulottuvuuteen (2 ulottuvuutta 3 ulottuvuuden sijaan) pitäen kaikki alkuperäiset muuttujat mallissa.
tähän liittyy aika paljon matematiikkaa. Jos haluat lisätietoja siitä…
Katso tämä mahtava artikkeli PCA: sta täältä.
Jos haluat mieluummin katsoa videon, StatQuest selittää PCA: ta 5 minuutissa täällä.
johtopäätös
on selvää, että monimutkaisuutta on tonni, jos sukeltaa johonkin tiettyyn malliin, mutta tämän pitäisi antaa sinulle perustavaa laatua oleva käsitys siitä, miten kukin koneoppimisen algoritmi toimii!
Lisää tämänkaltaisia artikkeleita, Katso https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (2010), Prentice Hall
roweis, S. T., Saul, L. K., Epälineaarinen Dimensionality Reduction by Locally Linear Embedding (2000), Science