Alle Machine Learning modellen uitgelegd in 6 minuten
intuïtieve uitleg van de meest populaire machine learning modellen.

in mijn vorige artikel legde ik uit wat regressie was en liet ik zien hoe het in toepassing gebruikt kon worden. Deze week ga ik de meeste gangbare machine learning-modellen in de praktijk doornemen, zodat ik meer tijd kan besteden aan het bouwen en verbeteren van modellen in plaats van de theorie erachter uit te leggen. Laten we erin duiken.

Alle machine learning modellen worden gecategoriseerd als van toezicht of toezicht. Als het model een gecontroleerd model is, wordt het vervolgens gesubcategoriseerd als een regressie-of Classificatiemodel. We zullen gaan over wat deze termen betekenen en de bijbehorende modellen die vallen in elke categorie hieronder.
begeleid leren omvat het leren van een functie die een input aan een output koppelt op basis van bijvoorbeeld input-output paren .
bijvoorbeeld, als ik een dataset had met twee variabelen, leeftijd (input) en hoogte (output), kon ik een begeleid leermodel implementeren om de hoogte van een persoon te voorspellen op basis van hun leeftijd.
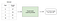
om Te herhalen, binnen begeleid leren, er zijn twee sub-categorieën: regressie en classificatie.
regressie
In regressiemodellen is de uitvoer continu. Hieronder staan enkele van de meest voorkomende soorten regressiemodellen.
Lineaire Regressie

Het idee van een lineaire regressie is gewoon het vinden van een lijn die het best past bij de gegevens. Uitbreidingen van lineaire regressie omvatten meerdere lineaire regressie (bijv. het vinden van een vlak van de beste pasvorm) en veelterm regressie (bijv. het vinden van een curve van best fit). U kunt meer te weten komen over lineaire regressie in mijn vorige artikel.
beslisboom
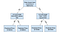
Besluit bomen zijn een populair model, gebruikt in operations research, de strategische planning en machine learning. Elk vierkant hierboven wordt een knooppunt genoemd, en hoe meer knooppunten je hebt, hoe nauwkeuriger je beslissingsboom zal zijn (over het algemeen). De laatste knooppunten van de beslissingsboom, waar een beslissing wordt genomen, worden de bladeren van de boom genoemd. Beslissingsbomen zijn intuïtief en eenvoudig te bouwen, maar schieten tekort als het gaat om nauwkeurigheid.
Random Forest
Random forests zijn een ensemble-leertechniek die voortbouwt op beslissingsbomen. Willekeurige forests omvatten het maken van meerdere beslissingsbomen met behulp van Bootstrap-datasets van de oorspronkelijke gegevens en het willekeurig selecteren van een subset van variabelen bij elke stap van de beslissingsboom. Het model selecteert vervolgens de modus van alle voorspellingen van elke beslissingsboom. Wat is het nut hiervan? Door te vertrouwen op een” majority wins ” – model, vermindert het het risico op fouten van een individuele boom.

bijvoorbeeld, als we een beslissing boom, de derde, het voorspellen van 0. Maar als we vertrouwden op de modus van alle 4 beslissingsbomen, zou de voorspelde waarde 1 zijn. Dit is de kracht van willekeurige bossen.
StatQuest doet geweldig werk door dit in meer detail te doorlopen. Kijk hier.
Neurale netwerken

Een Neuraal Netwerk is in feite een netwerk van wiskundige vergelijkingen. Het duurt een of meer input variabelen, en door te gaan door een netwerk van vergelijkingen, resulteert in een of meer output variabelen. Je kunt ook zeggen dat een neuraal netwerk een vector van inputs opneemt en een vector van outputs retourneert, maar Ik zal niet in matrices komen in dit artikel.
De blauwe cirkels staan voor de invoerlaag, de zwarte cirkels voor de verborgen lagen en de groene cirkels voor de uitvoerlaag. Elk knooppunt in de verborgen lagen vertegenwoordigt zowel een lineaire functie als een activeringsfunctie waar de knooppunten in de vorige laag doorheen gaan, wat uiteindelijk leidt tot een output in de groene cirkels.
- als je er meer over wilt weten, bekijk dan mijn beginnersvriendelijke uitleg op neurale netwerken.
classificatie
In classificatiemodellen is de output discreet. Hieronder vindt u enkele van de meest voorkomende soorten classificatiemodellen.
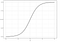
logistieke regressie
logistieke regressie is vergelijkbaar met lineaire regressie, maar wordt gebruikt om de waarschijnlijkheid van een eindig aantal uitkomsten te modelleren, meestal twee. Er zijn een aantal redenen waarom logistische regressie wordt gebruikt over lineaire regressie bij het modelleren van waarschijnlijkheden van uitkomsten (zie hier). In essentie wordt een logistische vergelijking zo gemaakt dat de uitgangswaarden alleen tussen 0 en 1 kunnen liggen (zie hieronder).
Support Vector Machine
Een Support Vector Machine is een supervised classificatie techniek die kan eigenlijk behoorlijk ingewikkeld, maar is vrij intuïtief op het meest fundamentele niveau.
laten we aannemen dat er twee klassen van gegevens zijn. Een support vector machine zal een hypervlak of een grens tussen de twee klassen van gegevens vinden die de marge tussen de twee klassen maximaliseert (zie hieronder). Er zijn veel vlakken die de twee klassen kunnen scheiden, maar slechts één vlak kan de marge of afstand tussen de klassen maximaliseren.

Als u meer in detail wilt treden, heeft Savan hier een geweldig artikel over support vector machines geschreven.
Naive Bayes
Naive Bayes is een andere populaire classifier die gebruikt wordt in Data Science. Het idee erachter wordt gedreven door de Stelling van Bayes:
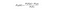
In deze vergelijking wordt gebruikt om de volgende vraag te beantwoorden. “Wat is de waarschijnlijkheid van y (mijn output variabele) gegeven X? En vanwege de naïeve aanname dat variabelen onafhankelijk zijn gezien de klasse, kun je zeggen dat:

ook, door de noemer te verwijderen, kunnen we dan zeggen dat p(y/x) evenredig is aan de rechterkant.

daarom is het doel om de klasse y te vinden met de maximale proportionele waarschijnlijkheid.
bekijk mijn artikel “A Mathematical Explanation of Naive Bayes” als je een meer diepgaande uitleg wilt!
beslissingsboom, Random Forest, neuraal netwerk
deze modellen volgen dezelfde logica als eerder uitgelegd. Het enige verschil is dat die output discreet is in plaats van continu.
Onbegeleid Leren

In tegenstelling tot begeleid leren, onbegeleid leren is gebruikt voor het trekken van conclusies en het vinden van patronen in de invoer van gegevens zonder verwijzingen naar gelabeld resultaten. Twee belangrijke methodes die in unsupervised leren worden gebruikt omvatten clustering en dimensionaliteitsreductie.
Clustering

clustering is een techniek zonder toezicht waarbij gegevens worden gegroepeerd of geclusteerd. Het wordt vaak gebruikt voor klantsegmentatie, fraudedetectie en documentclassificatie.
gemeenschappelijke clustering technieken omvatten k-middelen clustering, hiërarchische clustering, gemiddelde verschuiving clustering, en dichtheid-gebaseerde clustering. Terwijl elke techniek heeft een andere methode in het vinden van clusters, ze allemaal streven naar hetzelfde te bereiken.
Dimensionaliteitsreductie
Dimensionaliteitsreductie is het proces waarbij het aantal willekeurige variabelen wordt verminderd door een reeks van hoofdvariabelen te verkrijgen . In eenvoudiger termen, Het is het proces van het verminderen van de dimensie van uw functie set (in nog eenvoudiger termen, het verminderen van het aantal functies). De meeste dimensionaliteitsreductietechnieken kunnen worden gecategoriseerd als feature-eliminatie of feature-extractie.
een populaire methode voor dimensionaliteitsreductie wordt principal component analysis genoemd.
Principal Component Analysis (PCA)
in de eenvoudigste zin, PCA omvat project hoger dimensionale gegevens (bijv. 3 afmetingen) naar een kleinere ruimte (bijv. 2 Afmetingen). Dit resulteert in een lagere dimensie van gegevens (2 dimensies in plaats van 3 dimensies) terwijl alle originele variabelen in het model behouden blijven.
Er is nogal wat wiskunde bij betrokken. Als je er meer over wilt weten…
bekijk dan dit geweldige artikel over PCA hier.
Als u liever een video bekijkt, legt StatQuest hier PCA in 5 minuten uit.
conclusie
uiteraard is er een ton van complexiteit als je in een bepaald model duikt, maar dit zou je een fundamenteel begrip moeten geven van hoe elk machine learning algoritme werkt!
voor meer artikelen zoals deze, check out https://blog.datatron.com/
Stuart J. Russell, Peter Norvig, Artificial Intelligence: a Modern Approach (2010), Prentice Hall
Roweis, S. T., Saul, L. K., Niet-lineaire Dimensionaliteitsreductie door lokaal lineair inbedden (2000), Science