Deep Learning for Detecting Pneumonia from X-ray Images
an end to end pipeline for pneumonia detection from X-ray images
Stuck behind the paywall? Klik hier om het volledige verhaal te lezen met mijn vriend Link!het risico op longontsteking is enorm voor velen, vooral in ontwikkelingslanden waar miljarden met energiearmoede te maken hebben en afhankelijk zijn van vervuilende vormen van energie. De WHO schat dat jaarlijks meer dan 4 miljoen vroegtijdige sterfgevallen optreden als gevolg van met luchtvervuiling samenhangende ziekten in huishoudens, waaronder longontsteking. Jaarlijks raken meer dan 150 miljoen mensen besmet met longontsteking, vooral kinderen jonger dan 5 jaar. In dergelijke regio ‘ s kan het probleem verder worden verergerd door het gebrek aan medische middelen en personeel. In de 57 Afrikaanse landen is er bijvoorbeeld een kloof van 2,3 miljoen artsen en verpleegkundigen. Voor deze populaties betekent nauwkeurige en snelle diagnose alles. Het kan tijdige toegang tot behandeling garanderen en de broodnodige tijd en geld besparen voor degenen die al in armoede leven.
dit project is een deel van de thoraxfoto ‘ s (longontsteking) die op Kaggle worden gehouden.
Maak een algoritme om automatisch te identificeren of een patiënt al dan niet aan longontsteking lijdt door te kijken naar röntgenfoto ‘ s van de borst. Het algoritme moest uiterst nauwkeurig zijn omdat er levens van mensen op het spel staan.
Omgeving en tools
- scikit-leer
- keras
- numpy
- panda ‘ s
- matplotlib
Gegevens
De dataset kan worden gedownload van de kaggle website die u hier kunt vinden.
Waar is de code?
zonder veel ophef, laten we beginnen met de code. Het volledige project over github is hier te vinden.
laten we beginnen met het laden van alle bibliotheken en afhankelijkheden.
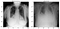
vervolgens liet ik wat normale en longontsteking beelden zien om te zien hoeveel ze er anders uitzien dan het blote oog. Nou niet veel!
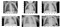
Toen ik splitsing van de data-set in drie sets — trein, validatie en test sets.
vervolgens schreef ik een functie waarin ik wat gegevensvergroting deed, de trainings-en testsets aan het netwerk voedde. Ook heb ik labels gemaakt voor de afbeeldingen.
de praktijk van gegevensvergroting is een effectieve manier om de omvang van de trainingsset te vergroten. Door de opleidingsvoorbeelden aan te vullen, kan het netwerk tijdens de opleiding meer gediversifieerde, maar nog steeds representatieve datapunten “zien”.
vervolgens heb ik een aantal gegevensgeneratoren gedefinieerd: één voor trainingsgegevens en de andere voor validatiegegevens. Een data generator is in staat om de vereiste hoeveelheid gegevens (een mini batch van beelden) rechtstreeks uit de bronmap te laden, om te zetten in trainingsgegevens (gevoed aan het model) en trainingsdoelen (een vector van attributen — het toezichtsignaal).
voor mijn experimenten stel ik meestal de
batch_size = 64in. Over het algemeen zou een waarde tussen 32 en 128 goed moeten werken. Meestal moet u verhogen / verlagen van de batchgrootte op basis van computationele middelen en prestaties model.
daarna heb ik enkele constanten gedefinieerd voor later gebruik.
de volgende stap was het bouwen van het model. Dit kan in de volgende 5 stappen worden beschreven.
- ik gebruikte vijf convolutionele blokken bestaande uit convolutielaag, max-pooling en batch-normalisatie.
- bovenop gebruikte ik een vlakke laag en volgde deze door vier volledig verbonden lagen.
- ook tussendoor heb ik dropouts gebruikt om over-fitting te verminderen.de activeringsfunctie van
- was Relu, behalve voor de laatste laag waar het Sigmoid was, omdat dit een binair classificatieprobleem is.
- Ik heb Adam gebruikt als optimizer en cross-entropy als verlies.
vóór de training is het model nuttig om een of meer callbacks te definiëren. Handige zijn: ModelCheckpoint en EarlyStopping.
- ModelCheckpoint: wanneer training veel tijd nodig heeft om een goed resultaat te bereiken, zijn vaak veel herhalingen nodig. In dit geval is het beter om een kopie van het best presterende model alleen op te slaan wanneer een tijdvak dat de statistieken verbetert eindigt.
- EarlyStopping: soms kunnen we tijdens de training merken dat de generalisatiekloof (d.w.z. het verschil tussen training en validatiefout) begint toe te nemen in plaats van af te nemen. Dit is een symptoom van overbevissing dat op vele manieren kan worden opgelost (het verminderen van de modelcapaciteit, het verhogen van trainingsgegevens, gegevensvergroting, regularisatie, uitval, enz.). Vaak is het een praktische en efficiënte oplossing om te stoppen met trainen wanneer de generalisatiekloof erger wordt.

Vervolgens heb ik de opleiding van de model 10 tijdvakken met een batch-grootte van 32. Houd er rekening mee dat meestal een hogere batchgrootte betere resultaten geeft, maar ten koste van een hogere computationele belasting. Sommige onderzoek beweren ook dat er een optimale batchgrootte voor de beste resultaten die kunnen worden gevonden door te investeren wat tijd op hyper-parameter tuning.
laten we de verlies-en nauwkeurigheidsgrafieken visualiseren.

So far So good. Het model convergeert wat kan worden waargenomen uit de afname van verlies en validatieverlies met tijdperken. Ook is het in staat om 90% validatienauwkeurigheid te bereiken in slechts 10 tijdperken.
laten we de verwarmingsmatrix plotten en een aantal van de andere resultaten krijgen, zoals precisie, recall, F1 score en nauwkeurigheid.
CONFUSION MATRIX ------------------
]
TEST METRICS ----------------------
Accuracy: 91.02564102564102%
Precision: 89.76190476190476%
Recall: 96.66666666666667%
F1-score: 93.08641975308642
TRAIN METRIC ----------------------
Train acc: 94.23
het model kan een nauwkeurigheid van 91,02% bereiken, wat vrij goed is gezien de grootte van de gebruikte gegevens.
conclusies
hoewel dit project verre van voltooid is, is het opmerkelijk om het succes van deep learning in zulke uiteenlopende problemen in de reële wereld te zien. Ik heb aangetoond hoe positieve en negatieve longontsteking gegevens te classificeren van een verzameling van röntgenfoto ‘ s. Het model werd gemaakt van nul, die het scheidt van andere methoden die sterk afhankelijk zijn van overdracht leren aanpak. In de toekomst zou dit werk kunnen worden uitgebreid om röntgenfoto ‘ s bestaande uit longkanker en longontsteking op te sporen en te classificeren. Het onderscheiden van röntgenfoto ‘ s die longkanker en longontsteking bevatten is de laatste tijd een groot probleem geweest, en onze volgende aanpak zou moeten zijn om dit probleem aan te pakken.