Kernsmelting en Spectre, uitgelegd
hoewel ik tegenwoordig vooral bekend sta om netwerken op applicatieniveau en gedistribueerde systemen, heb ik het eerste deel van mijn carrière besteed aan besturingssystemen en hypervisors. Ik blijf gefascineerd door de lage details van hoe moderne processors en systeemsoftware werken. Toen de recente Kernsmelting en Spectre kwetsbaarheden werden aangekondigd, ik gegraven in de beschikbare informatie en stond te popelen om meer te leren.
de kwetsbaarheden zijn verbazingwekkend; Ik zou zeggen dat ze een van de belangrijkste ontdekkingen in de informatica in de laatste 10-20 jaar. De verzachtingenzijn ook moeilijk te begrijpen en nauwkeurige informatie over hen is moeilijk te vinden. Dit is niet verwonderlijk gezien hun kritische aard. Het beperken van de kwetsbaarheden heeft maanden van geheimzinnig werk door alle van de grote CPU, besturingssysteem, en cloud leveranciers vereist. Het feit dat de problemen werden verborgen gehouden voor 6 maanden toen letterlijk honderden mensen waren waarschijnlijk bezig met hen is verbazingwekkend.
hoewel er veel is geschreven over Kernsmelting en Spectre sinds hun aankondiging, heb ik geen goede mid-level introductie gezien van de kwetsbaarheden en mitigaties. In dit bericht ga ik proberen om dat te corrigeren door het verstrekken van een zachte inleiding tot de hardware en software achtergrond die nodig is om de kwetsbaarheden te begrijpen, een bespreking van de kwetsbaarheden zelf, evenals een bespreking van de huidige mitigaties.
belangrijke opmerking: Omdat ik niet direct heb gewerkt aan de mitigaties, en niet werken bij Intel, Microsoft, Google, Amazon, Red Hat, enz. sommige details die ik ga geven zijn misschien niet helemaal accuraat. Ik heb dit bericht samengesteld op basis van mijn kennis van hoe deze systemen werken, openbaar beschikbare documentatie, en patches/discussie geplaatst op LKML en xen-devel. Ik zou graag worden gecorrigeerd als een van deze post is onjuist, hoewel ik betwijfel dat zal binnenkort gebeuren gezien hoeveel van dit onderwerp is nog steeds gedekt door NDA.
In deze sectie zal ik Enige achtergrond geven die nodig is om de kwetsbaarheden te begrijpen. De sectie vergelijkt een groot aantal details en is gericht op lezers met een beperkt begrip van computerhardware en systeemsoftware.
virtueel geheugen
virtueel geheugen is een techniek die wordt gebruikt door alle besturingssystemen sinds de jaren zeventig. het biedt een laag van abstractie tussen de geheugenadresindeling die de meeste software ziet en de fysieke apparaten die dat geheugen ondersteunen (RAM, schijven, enz.). Op een hoog niveau kunnen applicaties meer geheugen gebruiken dan de machine eigenlijk heeft; dit zorgt voor een krachtige abstractie die veel programmeertaken gemakkelijker maakt.

figuur 1 toont een simplistische computer met 400 bytes geheugen in “Pages” van 100 bytes (echte computers gebruiken bevoegdheden van twee, meestal 4096). De computer heeft twee processen, elk met 200 bytes geheugen over 2 pagina ‘ s elk. De processen kunnen dezelfde code draaien met behulp van vaste adressen in het 0-199 byte bereik, maar ze worden ondersteund door Discreet fysiek geheugen, zodat ze elkaar niet beïnvloeden. Hoewel moderne besturingssystemen en computers virtueel geheugen gebruiken op een aanzienlijk ingewikkelder manier dan wat in dit voorbeeld wordt gepresenteerd, geldt het uitgangspunt hierboven in alle gevallen. Besturingssystemen abstraheren de adressen die de toepassing ziet van de fysieke bronnen die ze ondersteunen.
het vertalen van virtuele naar fysieke adressen is zo gebruikelijk in moderne computers dat als het besturingssysteem in alle gevallen betrokken zou zijn, de computer ongelooflijk traag zou zijn. Moderne CPU hardware biedt een apparaat genaamd een Translation Lookaside Buffer (TLB) dat recent gebruikte mappings caches. Dit staat CPU ‘ s toe om adresvertaling direct in hardware het grootste deel van de tijd uit te voeren.
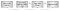
Figuur 2 toont de address translation flow:
- Een programma haalt een virtueel adres op.
- de CPU probeert het te vertalen met behulp van de TLB. Als het adres wordt gevonden, wordt de vertaling gebruikt.
- als het adres niet wordt gevonden, raadpleegt de CPU een reeks “paginatabellen” om de toewijzing te bepalen. Paginatabellen zijn een verzameling fysieke geheugenpagina ‘ s die door het besturingssysteem worden geleverd op een locatie waar de hardware ze kan vinden (bijvoorbeeld het CR3-register op x86-hardware). Paginatabellen wijzen virtuele adressen toe aan fysieke adressen en bevatten ook metagegevens zoals machtigingen.
- als de paginatabel een toewijzing bevat, wordt deze geretourneerd, gecached in de TLB, en gebruikt voor lookup. Als de paginatabel geen toewijzing bevat, wordt een” paginafout ” verhoogd naar het besturingssysteem. Een paginafout is een speciaal soort interrupt dat het besturingssysteem in staat stelt om de controle te nemen en te bepalen wat te doen wanneer er een ontbrekende of ongeldige toewijzing is. Het besturingssysteem kan bijvoorbeeld het programma beëindigen. Het kan ook wat fysiek geheugen toewijzen en in kaart brengen in het proces. Als een pagina fout handler blijft uitvoeren, zal de nieuwe toewijzing worden gebruikt door de TLB.

Figuur 3 geeft een iets meer realistisch beeld van wat het virtuele geheugen lijkt op een moderne computer (pre-Crisis — meer hieronder). In deze setup hebben we de volgende eigenschappen:
- kernelgeheugen wordt in rood weergegeven. Het is opgenomen in fysieke adresbereik 0-99. Kernelgeheugen is speciaal geheugen waar alleen het besturingssysteem toegang toe zou moeten hebben. Gebruikersprogramma ‘ s moeten niet in staat zijn om toegang te krijgen.
- gebruikersgeheugen wordt in het grijs weergegeven.
- niet-toegewezen fysiek geheugen wordt in blauw weergegeven.
In dit voorbeeld beginnen we enkele nuttige functies van virtueel geheugen te zien. Voornamelijk:
- gebruikersgeheugen in elk proces is in het virtuele bereik 0-99, maar ondersteund door een ander fysiek geheugen.
- kernelgeheugen in elk proces is in het virtuele bereik 100-199, maar ondersteund door hetzelfde fysieke geheugen.
zoals ik kort in de vorige paragraaf al zei, heeft elke pagina geassocieerde permissiebits. Hoewel het kernelgeheugen is toegewezen aan elk gebruikersproces, kan het in de gebruikersmodus geen toegang krijgen tot het kernelgeheugen. Als een proces probeert dit te doen, zal het leiden tot een pagina fout op welk punt het besturingssysteem zal beëindigen. Echter, als het proces in de kernelmodus draait (bijvoorbeeld tijdens een systeemaanroep), zal de processor de toegang toestaan.
Op dit punt zal ik opmerken dat dit type van dual mapping (elk proces waarbij de kernel Direct is toegewezen) al meer dan dertig jaar de standaardpraktijk is in het ontwerp van het besturingssysteem om redenen van prestatie (systeemaanroepen zijn heel gebruikelijk en het zou lang duren om de kernel of de gebruikersruimte bij elke overgang opnieuw te mappen).
CPU cache topologie

het volgende stukje achtergrond informatie dat nodig is om de kwetsbaarheden te begrijpen is de CPU en cache topologie van moderne processors. Figuur 4 toont een algemene topologie die gebruikelijk is voor de meeste moderne CPU ‘ s. Het bestaat uit de volgende componenten:
- de basiseenheid van uitvoering is de “CPU thread” of “hardware thread” of “hyper-thread.”Elke CPU thread bevat een set van registers en de mogelijkheid om een stroom van machine code uit te voeren, net als een software thread.
- CPU threads bevinden zich binnen een “CPU core.”De meeste moderne CPU’ s bevatten twee threads per kern.
- moderne CPU ‘ s bevatten over het algemeen meerdere niveaus van cachegeheugen. De cache niveaus dichter bij de CPU thread zijn kleiner, sneller en duurder. Hoe verder weg van de CPU en dichter bij het hoofdgeheugen de cache is hoe groter, langzamer en minder duur het is.
- typisch modern CPU ontwerp gebruikt een L1 / L2 cache per core. Dit betekent dat elke CPU thread op de kern gebruik maakt van dezelfde caches.
- meerdere CPU-kernen zijn opgenomen in een ” CPU-pakket.”Moderne CPU’ s kunnen meer dan 30 cores (60 threads) of meer per verpakking bevatten.
- alle CPU-cores in het pakket delen doorgaans een L3-cache.
- CPU-pakketten passen in ” sockets.”De meeste consumenten computers zijn een enkele socket, terwijl veel datacenter servers hebben meerdere sockets.
Speculatieve uitvoering

het laatste stukje achtergrondinformatie dat nodig is om de kwetsbaarheden te begrijpen is een moderne CPU techniek die bekend staat als ” speculative execution.”Figuur 5 toont een algemeen schema van de uitvoering engine in een moderne CPU.
de belangrijkste afhaalmaaltijd is dat moderne CPU ‘ s ongelooflijk ingewikkeld zijn en niet alleen machine-instructies in volgorde uitvoeren. Elke CPU thread heeft een ingewikkelde pipelining motor die in staat is om het uitvoeren van instructies buiten de orde is. De reden hiervoor heeft te maken met caching. Zoals ik besproken in de vorige sectie, elke CPU maakt gebruik van meerdere niveaus van caching. Elke cache miss voegt een aanzienlijke hoeveelheid vertraging tijd om het programma uitvoering. Om dit te beperken, processors zijn in staat om vooruit en buiten de orde uit te voeren tijdens het wachten op geheugenbelasting. Dit staat bekend als speculatieve uitvoering. Het volgende codefragment toont dit aan.
if (x < array1_size) {
y = array2 * 256];
}
in het vorige fragment, stel je voor dat array1_size niet beschikbaar is in de cache, maar het adres van array1 wel. De CPU zou kunnen raden (speculeren) dat x kleiner is dan array1_size en ga door en voer de berekeningen uit in het if statement. Zodra array1_size uit het geheugen wordt gelezen, kan de CPU bepalen of het goed geraden is. Als dat zo is, kan het een hoop tijd blijven besparen. Als dat niet zo is, kan het de speculatieve berekeningen weggooien en opnieuw beginnen. Dit is niet erger dan als het had gewacht in de eerste plaats.
een ander type speculatieve uitvoering staat bekend als indirecte branch prediction. Dit is zeer gebruikelijk in moderne programma ‘ s als gevolg van virtuele verzending.
class Base {
public:
virtual void Foo() = 0;
};class Derived : public Base {
public:
void Foo() override { … }
};Base* obj = new Derived;
obj->Foo();
(de bron van het vorige fragment is dit bericht)
de manier waarop het vorige fragment is geïmplementeerd in machinecode is door de” V-table “of” virtual dispatch table”Te laden vanaf de geheugenlocatie waar obj naar verwijst en het vervolgens aanroept. Omdat deze operatie zo gebruikelijk is, hebben moderne CPU ‘ s verschillende interne caches en zullen ze vaak raden (speculeren) waar de indirecte branch zal gaan en de uitvoering op dat punt voortzetten. Nogmaals, als de CPU goed raadt, kan het doorgaan met het opslaan van een hoop tijd. Als dat niet zo is, kan het de speculatieve berekeningen weggooien en opnieuw beginnen.
Kernsmelting kwetsbaarheid
nu alle achtergrondinformatie is behandeld, kunnen we in de kwetsbaarheden duiken.
Rogue data cache load
De eerste kwetsbaarheid, bekend als Meltdown, is verrassend eenvoudig uit te leggen en bijna triviaal te exploiteren. De exploit code ziet er ongeveer als het volgende:
1. uint8_t* probe_array = new uint8_t;
2. // ... Make sure probe_array is not cached
3. uint8_t kernel_memory = *(uint8_t*)(kernel_address);
4. uint64_t final_kernel_memory = kernel_memory * 4096;
5. uint8_t dummy = probe_array;
6. // ... catch page fault
7. // ... determine which of 256 slots in probe_array is cached
laten we elke stap hierboven zetten, beschrijven wat het doet, en hoe het leidt tot het kunnen lezen van het geheugen van de hele computer van een gebruikersprogramma.
- op de eerste regel wordt een “probe array” toegewezen. Dit is geheugen in ons proces dat wordt gebruikt als een zijkanaal om gegevens uit de kernel op te halen. Hoe dit gebeurt zal snel duidelijk worden.
- na de allocatie zorgt de aanvaller ervoor dat geen van het geheugen in de probe array in de cache zit. Er zijn verschillende manieren om dit te bereiken, waarvan de eenvoudigste CPU-specifieke instructies bevat om een geheugenlocatie uit de cache te wissen.
- de aanvaller leest vervolgens een byte uit de kerneladresruimte. Onthoud uit onze vorige discussie over virtueel geheugen en paginatabellen dat alle moderne kernels doorgaans de volledige virtuele adresruimte van de kernel toewijzen aan het gebruikersproces. Besturingssystemen vertrouwen op het feit dat elke pagina tabelinvoer machtigingsinstellingen heeft, en dat programma ‘ s in de gebruikersmodus geen toegang hebben tot kernelgeheugen. Een dergelijke toegang zal resulteren in een pagina fout. Dat is inderdaad wat er uiteindelijk zal gebeuren bij stap 3.
- moderne processors voeren echter ook speculatieve uitvoering uit en zullen deze uitvoeren vóór de foutieve instructie. Dus, stappen 3-5 kan uitvoeren in de CPU pijplijn voordat de fout wordt verhoogd. In deze stap wordt de byte van het kernelgeheugen (die varieert van 0-255) vermenigvuldigd met de paginagrootte van het systeem, die doorgaans 4096 is.
- in deze stap wordt de vermenigvuldigde byte van het kernelgeheugen gebruikt om van de probe-array naar een dummy-waarde te lezen. De vermenigvuldiging van de byte door 4096 is om te voorkomen dat een CPU-functie genaamd de “prefetcher” van het lezen van meer gegevens dan we willen in de cache.
- door deze stap heeft de CPU zijn fout gerealiseerd en teruggerold naar stap 3. De resultaten van de gespeculeerde instructies zijn echter nog steeds zichtbaar in de cache. De aanvaller gebruikt de functionaliteit van het besturingssysteem om de foutieve instructie te vangen en de uitvoering voort te zetten (bijvoorbeeld het afhandelen van SIGFAULT).
- in Stap 7 herhaalt de aanvaller zich en ziet hoe lang het duurt om elk van de 256 mogelijke bytes in de probe array te lezen die door het kernelgeheugen geïndexeerd zouden kunnen zijn. De CPU zal een van de locaties in de cache hebben geladen en deze locatie zal aanzienlijk sneller laden dan alle andere locaties (die moeten worden gelezen uit het hoofdgeheugen). Deze locatie is de waarde van de byte in het kernelgeheugen.
door gebruik te maken van de bovenstaande techniek en het feit dat het standaard gebruik is voor moderne besturingssystemen om al het fysieke geheugen in de virtuele adresruimte van de kernel in te delen, kan een aanvaller het volledige fysieke geheugen van de computer lezen.
nu vraagt u zich misschien af :” u zei dat paginatabellen permissie-bits hebben. Hoe kan het zijn dat user mode code in staat was om speculatief toegang te krijgen tot kernelgeheugen?”De reden is dat dit een bug in Intel processors. Naar mijn mening is er geen goede reden, prestatie of anderszins, om dit mogelijk te maken. Bedenk dat alle virtuele geheugentoegang via de TLB moet plaatsvinden. Het is gemakkelijk mogelijk tijdens speculatieve uitvoering om te controleren of een cache-toewijzing machtigingen heeft die compatibel zijn met het huidige draaiende privilege niveau. Intel hardware doet dit gewoon niet. Andere processor leveranciers doen het uitvoeren van een toestemming te controleren en te blokkeren speculatieve uitvoering. Dus, voor zover we weten, Kernsmelting is een Intel enige kwetsbaarheid.
Edit: het lijkt erop dat ten minste één ARM processor ook gevoelig is voor Meltdown zoals hier en hier aangegeven.
Meltdown mitigations
Meltdown is gemakkelijk te begrijpen, triviaal te exploiteren, en heeft gelukkig ook een relatief eenvoudige mitigatie (tenminste conceptueel — kernel ontwikkelaars zullen het niet eens zijn dat het eenvoudig te implementeren is).
kernel page table isolation (Kpti)
bedenk dat in de paragraaf over virtueel geheugen ik beschreef dat alle moderne besturingssystemen een techniek gebruiken waarbij kernelgeheugen wordt toegewezen aan elke user mode proces virtueel geheugen adresruimte. Dit is voor zowel prestaties als eenvoud redenen. Dit betekent dat wanneer een programma een systeemaanroep doet, de kernel klaar is om te worden gebruikt zonder verder werk. De oplossing voor Kernsmelting is om deze dubbele mapping niet langer uit te voeren.

figuur 6 toont een techniek genaamd kernel page table isolation (kpti). Dit komt neer op het niet in kaart brengen van kernelgeheugen in een programma wanneer het wordt uitgevoerd in de gebruikersruimte. Als er geen mapping aanwezig, speculatieve uitvoering is niet meer mogelijk en zal onmiddellijk fout.
naast het ingewikkelder maken van de virtual memory manager (VMM) van het besturingssysteem, zal deze techniek zonder hulp van hardware ook de workloads aanzienlijk vertragen die een groot aantal overgangen van de gebruikersmodus naar de kernelmodus maken, vanwege het feit dat de paginatabellen bij elke overgang moeten worden gewijzigd en de TLB moet worden doorgespoeld (gezien het feit dat de TLB vast kan houden aan verouderde toewijzingen).
nieuwere x86 CPU ‘ s hebben een functie die bekend staat als ASID (address space ID) of PCID (process context ID) die kan worden gebruikt om deze taak aanzienlijk goedkoper te maken (ARM en andere microarchitecturen hebben deze functie al jaren). PCID staat toe dat een ID geassocieerd wordt met een TLB entry en dan alleen TLB entry ‘ s met dat ID spoelt. Het gebruik van PCID maakt KPTI goedkoper, maar nog steeds niet gratis.
samengevat, Kernsmelting is een zeer ernstige en gemakkelijk te benutten kwetsbaarheid. Gelukkig heeft het een relatief eenvoudige mitigatie die al is geïmplementeerd door alle grote OS-leveranciers, het voorbehoud is dat bepaalde workloads langzamer zullen lopen totdat toekomstige hardware expliciet is ontworpen voor de adresruimte scheiding beschreven.
Spectre kwetsbaarheid
Spectre deelt enkele eigenschappen van Meltdown en bestaat uit twee varianten. In tegenstelling tot Meltdown, Spectre is aanzienlijk moeilijker te exploiteren, maar beïnvloedt bijna alle moderne processors geproduceerd in de afgelopen twintig jaar. In wezen, Spectre is een aanval tegen moderne CPU en besturingssysteem ontwerp versus een specifieke beveiligingsprobleem.
Bounds check bypass (Spectre variant 1)
de eerste Spectre variant staat bekend als “bounds check bypass.”Dit wordt aangetoond in het volgende codefragment (dat is hetzelfde codefragment dat ik hierboven gebruikte om speculatieve uitvoering te introduceren).
if (x < array1_size) {
y = array2 * 256];
}
in het vorige voorbeeld wordt de volgende reeks gebeurtenissen aangenomen:
- de aanvaller controleert
x. -
array1_sizewordt niet in de cache opgeslagen. -
array1wordt in de cache opgeslagen. - de CPU raadt aan dat
xkleiner is danarray1_size. (CPU ‘ s maken gebruik van verschillende eigen algoritmen en heuristiek om te bepalen of te speculeren, dat is de reden waarom aanval details Voor Spectre variëren tussen processor leveranciers en modellen.) - de CPU voert de body van het if statement uit terwijl het wacht op
array1_sizeom te laden, en beïnvloedt de cache op een soortgelijke manier als Meltdown. - de aanvaller kan dan de werkelijke waarde van
array1bepalen via een van de verschillende methoden. (Zie de research paper voor meer details van cache inference aanvallen.)
Spectre is aanzienlijk moeilijker te exploiteren dan Kernsmelting omdat deze kwetsbaarheid niet afhankelijk is van escalatie van privileges. De aanvaller moet de kernel overtuigen om code uit te voeren en verkeerd speculeren. Meestal moet de aanvaller de speculatiemotor vergiftigen en hem misleiden om verkeerd te gissen. Dat gezegd hebbende, onderzoekers hebben een aantal proof-of-concept exploits getoond.
Ik wil herhalen wat een echt ongelooflijk vinden van deze exploit is. Ik beschouw dit niet persoonlijk als een CPU-ontwerpfout zoals Kernsmelting per se. Ik beschouw dit als een fundamentele openbaring over hoe moderne hardware en software samenwerken. Het feit dat CPU-caches indirect kunnen worden gebruikt om te leren over toegangspatronen is al enige tijd bekend. Het feit dat CPU-caches kunnen worden gebruikt als een side-channel om computergeheugen te dumpen is verbazingwekkend, zowel conceptueel als in zijn implicaties.
Branch target injection (Spectre variant 2)
bedenk dat indirecte vertakking zeer gebruikelijk is in moderne programma ‘ s. Variant 2 van Spectre gebruikt indirecte branch voorspelling om de CPU te vergiftigen in speculatief uitvoeren naar een geheugen locatie die het anders nooit zou hebben uitgevoerd. Als het uitvoeren van deze instructies staat achter kan laten in de cache die kan worden gedetecteerd met behulp van cache-inferentieaanvallen, kan de aanvaller dan al het kernelgeheugen dumpen. Net als Spectre variant 1, Spectre variant 2 is veel moeilijker te exploiteren dan Kernsmelting, maar onderzoekers hebben aangetoond werken proof-of-concept exploits van variant 2.
Spectre mitigations
De Spectre mitigations zijn aanzienlijk interessanter dan de Meltdown mitigation. In feite schrijft het academic Spectre paper dat er op dit moment geen verzachtende omstandigheden bekend zijn. Het lijkt erop dat achter de schermen en parallel aan het academische werk, Intel (en waarschijnlijk andere CPU-leveranciers) en de grote OS en cloud-leveranciers hebben gewerkt woedend voor maanden om mitigaties te ontwikkelen. In deze paragraaf zal ik de verschillende mitigaties behandelen die zijn ontwikkeld en ingezet. Dit is de sectie waar ik het meest wazig op ben omdat het ongelooflijk moeilijk is om accurate informatie te krijgen, dus ik piecing dingen samen uit verschillende bronnen.
statische analyse en schermen (Variant 1 mitigatie)
de enige bekende variant 1 (bounds check bypass) mitigatie is statische analyse van code om codesequenties te bepalen die mogelijk worden gecontroleerd door de aanvaller om speculatie te verstoren. Kwetsbare codesequenties kunnen een serialiserende instructie hebben zoals lfence die speculatieve uitvoering stopt totdat alle instructies tot aan het hek zijn uitgevoerd. Voorzichtigheid moet worden betracht bij het inbrengen van omheiningsinstructies, omdat te veel ernstige gevolgen kunnen hebben voor de prestaties.
Retpoline (variant 2 mitigatie)
De eerste Spectre variant 2 (branch target injection) mitigatie werd ontwikkeld door Google en staat bekend als “retpoline.”Het is mij niet duidelijk of het is ontwikkeld in isolatie door Google of door Google in samenwerking met Intel. Ik zou speculeren dat het experimenteel werd ontwikkeld door Google en vervolgens geverifieerd door Intel hardware ingenieurs, maar ik ben niet zeker. Details over de” retpoline “- aanpak zijn te vinden in Google ‘ s paper over het onderwerp. Ik zal ze hier samenvatten (ik ben glossing over een aantal details met inbegrip van underflow die worden behandeld in het papier).
Retpoline vertrouwt op het feit dat het aanroepen en terugkeren van functies en de bijbehorende stack manipulaties zo gebruikelijk zijn in computerprogramma ’s dat CPU’ s sterk geoptimaliseerd zijn voor het uitvoeren ervan. (Als je niet bekend bent met hoe de stack werkt met betrekking tot het aanroepen en terugkeren van functies is dit bericht een goede primer.) In een notendop, wanneer een “call” wordt uitgevoerd, wordt het retouradres op de stack gepusht. “ret” knalt het retouradres uit en gaat door met de uitvoering. Speculatieve uitvoering hardware zal het geduwd retouradres onthouden en speculatief doorgaan met de uitvoering op dat punt.
De retpoline-constructie vervangt een indirecte sprong naar de geheugenlocatie opgeslagen in register r11:
jmp *%r11
door:
call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov %r11, (%rsp); (2)
ret; (3)
laten we eens kijken wat de vorige assembly code stap voor stap doet en hoe het branch doel injectie vermindert.
- in deze stap roept de code een geheugenlocatie aan die bekend is tijdens het compileren, dus is het een harde gecodeerde offset en niet indirect. Dit plaatst het retouradres van
capture_specop de stack. - het retouradres van de oproep wordt overschreven met het eigenlijke jump-doel.
- een return wordt uitgevoerd op het echte doel.
- wanneer de CPU speculatief wordt uitgevoerd, zal het terugkeren in een oneindige lus! Vergeet niet dat de CPU vooruit zal speculeren totdat het geheugen belastingen zijn voltooid. In dit geval is de speculatie gemanipuleerd om gevangen te worden in een oneindige lus die geen bijwerkingen heeft die waarneembaar zijn voor een aanvaller. Wanneer de CPU uiteindelijk de echte return uitvoert, zal het de speculatieve uitvoering afbreken die geen effect had.
naar mijn mening is dit een werkelijk ingenieuze mitigatie. Kudos aan de ingenieurs die het hebben ontwikkeld. Het nadeel van deze mitigatie is dat alle software opnieuw gecompileerd moet worden zodat indirecte branches geconverteerd worden naar retpoline branches. Voor cloudservices zoals Google die de hele stack bezitten, is hercompilatie geen probleem. Voor anderen, het kan een zeer big deal of onmogelijk zijn.
IBRS, STIBP, en IBPB (Variant 2 mitigation)
Het lijkt erop dat Intel (en AMD tot op zekere hoogte) gelijktijdig met de ontwikkeling van retpoline furieus hebben gewerkt aan hardwarewijzigingen om branch target injectie aanvallen te beperken. De drie nieuwe hardware functies worden verzonden als CPU microcode updates zijn:
- Indirect Branch Restricted Speculation (IBRS)
- single Thread Indirect Branch Predictors (MIBP)
- indirecte Branch Predictor Barrier (IBPB)
beperkte informatie over de nieuwe microcode functies zijn hier beschikbaar bij Intel. Ik heb ruwweg kunnen uitzoeken wat deze nieuwe functies doen door het lezen van de bovenstaande documentatie en kijken naar Linux kernel en Xen hypervisor patches. Uit mijn analyse, wordt elke functie mogelijk als volgt gebruikt:
- IBRS zowel spoelt de Branch voorspelling cache tussen privilege niveaus (gebruiker naar kernel) en schakelt Branch voorspelling op de broer of zus CPU thread. Bedenk dat elke CPU-kern meestal twee CPU-threads heeft. Het lijkt erop dat op moderne CPU ‘ s de Branch voorspelling hardware wordt gedeeld tussen de threads. Dit betekent dat de code van de gebruikersmodus niet alleen de Branch predictor kan vergiftigen voordat de kernelcode wordt ingevoerd, maar ook de code die op de verwante CPU-thread draait, kan deze ook vergiftigen. Het inschakelen van IBRS in de kernelmodus voorkomt in wezen elke eerdere uitvoering in de gebruikersmodus en elke uitvoering op de broer of zus CPU thread van invloed branch voorspelling.
- STIBP lijkt een subset van IBRS te zijn die branch voorspelling op de sibling CPU thread uitschakelt. Voor zover ik kan vertellen, de belangrijkste use case voor deze functie is om te voorkomen dat een broer of zus CPU thread van vergiftiging van de tak predictor bij het uitvoeren van twee verschillende gebruiker modus processen (of virtuele machines) op dezelfde CPU-kern op hetzelfde moment. Het is eerlijk gezegd niet helemaal duidelijk voor mij op dit moment wanneer de MIVP moet worden gebruikt.
- IBPB lijkt de Branch voorspelling cache te spoelen voor code die draait op hetzelfde privilege niveau. Dit kan worden gebruikt bij het schakelen tussen twee gebruikersmodus programma ‘ s of twee virtuele machines om ervoor te zorgen dat de vorige code niet interfereert met de code die op het punt staat te draaien (hoewel ik zonder de MIVP geloof dat code die op de verwante CPU thread draait nog steeds de branch predictor kan vergiftigen).
vanaf dit schrijven lijken de belangrijkste mitigaties die ik zie worden geïmplementeerd voor de branch target injectie kwetsbaarheid zowel retpoline als IBRS te zijn. Vermoedelijk is dit de snelste manier om de kernel te beschermen tegen gebruikersmodus programma ‘ s of de hypervisor tegen virtuele machine gasten. In de toekomst verwacht ik dat zowel de MIVP als IBPB worden ingezet afhankelijk van het paranoia-niveau van verschillende gebruikersmodus-programma ‘ s die elkaar storen.
de kosten van IBRS lijken ook zeer sterk te variëren tussen CPU-architecturen, waarbij nieuwere Intel Skylake-processoren relatief goedkoop zijn in vergelijking met oudere processoren. Bij Lyft, zagen we een ongeveer 20% vertraging op bepaalde system call zware workloads op AWS C4 gevallen wanneer de mitigations werden uitgerold. Ik zou speculeren dat Amazon uitgerold IBRS en potentieel ook retpoline, maar ik ben niet zeker. Het lijkt erop dat Google kan alleen uitgerold retpoline in hun cloud.
na verloop van tijd zou ik verwachten dat processors uiteindelijk naar een IBRS “always on” model zullen gaan waar de hardware standaard de scheiding tussen CPU threads van de Branch voorspeller opschonen en de status van de privilege niveau wijzigingen correct opvult. De enige reden dat dit niet zou worden gedaan vandaag is de schijnbare kosten van de aanpassing van deze functionaliteit op reeds vrijgegeven microarchitecturen via microcode updates.
conclusie
Het is zeer zeldzaam dat een onderzoeksresultaat de manier waarop computers worden gebouwd en uitgevoerd fundamenteel verandert. Meltdown en Spectre hebben precies dat gedaan. Deze bevindingen zullen hardware-en softwareontwerp aanzienlijk veranderen in de komende 7-10 jaar (de volgende CPU-hardwarecyclus), aangezien ontwerpers rekening houden met de nieuwe realiteit van de mogelijkheden van data-lekkage via cache-zijkanalen.
in de tussentijd zullen de kernsmelting en Spectre Bevindingen en de bijbehorende mitigaties aanzienlijke gevolgen hebben voor computergebruikers voor de komende jaren. Op korte termijn zullen de verzachtende omstandigheden een impact hebben op de prestaties die aanzienlijk kan zijn, afhankelijk van de werkbelasting en de specifieke hardware. Dit kan operationele wijzigingen vereisen voor sommige infrastructuren (bijvoorbeeld, bij Lyft zijn we agressief verplaatsen van sommige workloads naar AWS C5 instanties te wijten aan het feit dat IBRS lijkt aanzienlijk sneller te draaien op Skylake processors en de nieuwe Nitro hypervisor levert interrupts rechtstreeks aan gasten met behulp van SR-IOV en APICv, het verwijderen van vele virtuele machine uitgangen voor Io zware workloads). Desktop computer gebruikers zijn ook niet immuun, als gevolg van proof-of-concept browser aanvallen met behulp van JavaScript dat OS en browser leveranciers werken om te beperken. Bovendien, als gevolg van de complexiteit van de kwetsbaarheden, het is bijna zeker dat de beveiliging onderzoekers nieuwe exploits niet gedekt door de huidige mitigaties die moeten worden gepatcht zal vinden.
hoewel ik graag bij Lyft werk en het gevoel heb dat het werk dat we doen in de infrastructuurruimte van microservice systems een van de meest impactvolle werkzaamheden is die momenteel in de industrie worden gedaan, doen gebeurtenissen als deze me het werken aan besturingssystemen en hypervisors missen. Ik ben extreem jaloers op het heldhaftige werk dat de afgelopen zes maanden werd gedaan door een groot aantal mensen in het onderzoeken en verzachten van de kwetsbaarheden. Ik had er graag bij willen zijn!
Verder lezen
- Kernsmelting en Spectre academische papers: https://spectreattack.com/
- Google Project Zero blog post: https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
- Intel Spectre hardware oplossingen voor: https://software.intel.com/sites/default/files/managed/c5/63/336996-Speculative-Execution-Side-Channel-Mitigations.pdf
- Retpoline blog post: https://support.google.com/faqs/answer/7625886
- Goed overzicht van bekende informatie: https://github.com/marcan/speculation-bugs/blob/master/README.md