KDnuggets
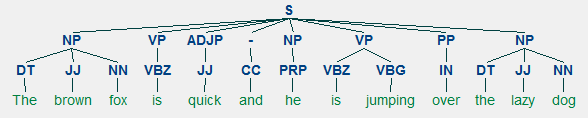
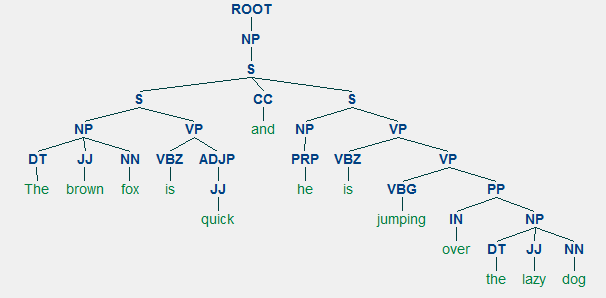
för alla språk, syntax och struktur går vanligtvis hand i hand, där en uppsättning specifika regler, konventioner och principer styr hur ord kombineras till fraser; fraser får kombinationer i klausuler; och klausuler kombineras i meningar. Vi kommer att prata specifikt om den engelska språksyntaxen och strukturen i det här avsnittet. På engelska kombineras ord vanligtvis för att bilda andra beståndsdelar. Dessa beståndsdelar inkluderar ord, fraser, klausuler och meningar. Med tanke på en mening, ”den bruna räven är snabb och han hoppar över den lata hunden”, den är gjord av en massa ord och bara titta på orden i sig säger inte mycket.

ett gäng oordnade ord förmedlar inte mycket information
kunskap om språkets struktur och syntax är till hjälp på många områden som textbehandling, annotering och parsning för ytterligare operationer som textklassificering eller sammanfattande. Typiska parsningstekniker för att förstå textsyntax nämns nedan.
- delar av tal (POS) taggning
- Grunt Parsing eller Chunking
- valkrets Parsing
- beroende Parsing
Vi kommer att titta på alla dessa tekniker i efterföljande avsnitt. Med tanke på vår tidigare exempelmening” den bruna räven är snabb och han hoppar över den lata hunden”, om vi skulle kommentera den med hjälp av grundläggande POS-taggar, skulle det se ut som följande figur.

POS-märkning för en mening
således följer en mening vanligtvis en hierarkisk struktur som består av följande komponenter,
satsnings-klausuler för satsnings-klausuler för satsnings-ord för satsnings-fraser för ord för ord
taggning av delar av tal
delar av tal (POS) är specifika lexikala kategorier som ord tilldelas, baserat på deras syntaktiska sammanhang och roll. Vanligtvis kan ord falla i en av följande huvudkategorier.
- N (oun): Detta betecknar vanligtvis ord som visar något objekt eller entitet, som kan vara levande eller icke-levande. Några exempel skulle vara räv , hund , bok och så vidare. POS – taggsymbolen för substantiv är N.
- V(erb): verb är ord som används för att beskriva vissa handlingar, tillstånd eller händelser. Det finns ett brett utbud av ytterligare underkategorier, såsom hjälp -, reflexiva och transitiva verb (och många fler). Några typiska exempel på verb skulle springa , hoppa , läsa och skriva . POS – taggsymbolen för verb är V.
- Adj (ective): Adjektiv är ord som används för att beskriva eller kvalificera andra ord, vanligtvis substantiv och substantivfraser. Frasen vacker blomma har substantivet (N) blomma som beskrivs eller kvalificeras med adjektivet (ADJ) vacker . POS – taggsymbolen för adjektiv är ADJ .
- Adv (erb): adverb fungerar vanligtvis som modifierare för andra ord inklusive substantiv, adjektiv, verb eller andra adverb. Frasen mycket vacker blomma har adverbet (ADV) mycket, vilket modifierar adjektivet (ADJ) vackert , vilket indikerar i vilken grad blomman är vacker. POS – taggsymbolen för adverb är ADV.
förutom dessa fyra huvudkategorier av delar av tal finns det andra kategorier som ofta förekommer på engelska. Dessa inkluderar pronomen, prepositioner, interjektioner, konjunktioner, determiners och många andra. Dessutom kan varje POS-tagg som substantivet (N) ytterligare delas in i kategorier som singular substantiv (NN), singular egennamn(NNP) och plural substantiv (NNS).
processen att klassificera och märka POS-taggar för ord som kallas delar av talmärkning eller POS-märkning . POS-taggar används för att kommentera ord och skildra deras POS, vilket verkligen är till hjälp för att utföra specifik analys, som att minska ner på substantiv och se vilka som är de mest framträdande, ordkänsla disambiguation och grammatikanalys. Vi kommer att utnyttja både nltk och spacy som vanligtvis använder Penn Treebank notation för POS-taggning.
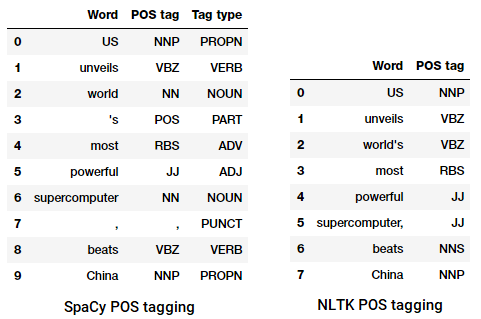
POS tagga en nyhetsrubrik
Vi kan se att var och en av dessa bibliotek behandlar tokens på egen väg och tilldelar specifika taggar för dem. Baserat på vad vi ser verkar spacy göra något bättre än nltk.
Grunt Parsing eller Chunking
baserat på hierarkin som vi avbildade tidigare utgör grupper av ord fraser. Det finns fem huvudkategorier av fraser:
- substantivfras (NP): Det här är fraser där ett substantiv fungerar som huvudordet. Substantivfraser fungerar som ett ämne eller objekt till ett verb.
- verbfras (VP): dessa fraser är lexikala enheter som har ett verb som fungerar som huvudordet. Vanligtvis finns det två former av verbfraser. En form har verbkomponenterna såväl som andra enheter som substantiv, adjektiv eller adverb som delar av objektet.
- Adjektivfras (ADJP): dessa är fraser med ett adjektiv som huvudord. Deras huvudroll är att beskriva eller kvalificera substantiv och pronomen i en mening, och de kommer antingen att placeras före eller efter substantivet eller pronomen.
- Adverb phrase (ADVP): dessa fraser fungerar som adverb eftersom adverbet fungerar som huvudordet i frasen. Adverbfraser används som modifierare för substantiv, verb eller adverb själva genom att tillhandahålla ytterligare detaljer som beskriver eller kvalificerar dem.
- Prepositional phrase (PP): dessa fraser innehåller vanligtvis en preposition som huvudord och andra lexikala komponenter som substantiv, pronomen och så vidare. Dessa fungerar som ett adjektiv eller adverb som beskriver andra ord eller fraser.
Grunt parsing, även känd som lätt parsing eller chunking, är en populär naturlig språkbehandlingsteknik för att analysera strukturen i en mening för att bryta ner den i sina minsta beståndsdelar (som är tokens som ord) och gruppera dem i högre nivå fraser. Detta inkluderar POS-taggar samt fraser från en mening.
ett exempel på Grunt parsing som visar högre nivåfrasanteckningar
Vi kommer att utnyttja conll2000 corpus för att träna vår grunda parsermodell. Denna corpus finns i nltk med chunk-anteckningar och vi kommer att använda cirka 10k-poster för att träna vår modell. En exempelkommenterad mening är avbildad enligt följande.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
från föregående utgång kan du se att våra datapunkter är meningar som redan är kommenterade med fraser och POS-taggar metadata som kommer att vara användbara vid träning av vår grunda tolkningsmodell. Vi kommer att utnyttja två chunking utility-funktioner, tree2conlltags, för att få tripplar av word, tagg och chunk-taggar för varje token, och conlltags2tree för att generera ett parsträd från dessa token tripplar. Vi kommer att använda dessa funktioner för att träna vår parser. Ett prov visas nedan.
chunk-taggarna använder IOB-formatet. Denna notation representerar Inuti, utanför och början. B-prefixet före en tagg indikerar att det är början på en bit, och I – prefixet indikerar att det är inuti en bit. O-taggen indikerar att token inte tillhör någon bit. B-taggen används alltid när det finns efterföljande taggar av samma typ som följer den utan att det finns O-taggar mellan dem.
Vi kommer nu att definiera en funktion conll_tag_ chunks() för att extrahera POS-och chunk-taggar från meningar med chunked-anteckningar och en funktion som heter combined_taggers() för att träna flera taggers med backoff-taggers (t.ex. unigram-och bigram-taggers)
Vi kommer nu att definiera en klass NGramTagChunker som kommer att ta in taggade meningar som träningsinmatning, få deras (word, POS tag, chunk tag) WTC tripplar och träna en BigramTagger med en UnigramTagger som backoff Tagger. Vi kommer också att definiera en parse() funktion för att utföra Grunt tolkning av nya meningar
UnigramTaggerBigramTaggerochTrigramTaggerär klasser som ärver från basklassenNGramTagger, som själv ärver från klassenContextTagger, som ärver från klassenSequentialBackoffTagger.
Vi kommer att använda den här klassen för att träna på conll2000 chunked train_data och utvärdera modellens prestanda på test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
vår chunking-modell får en noggrannhet på cirka 90% vilket är ganska bra! Låt oss nu utnyttja denna modell för att grunda analysera och chunk vår nyhetsartikelrubrik som vi använde tidigare, ”USA avslöjar världens mest kraftfulla superdator, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
således kan du se att den har identifierat två substantivfraser (NP) och en verbfras (VP) i nyhetsartikeln. Varje ords POS-taggar är också synliga. Vi kan också visualisera detta i form av ett träd enligt följande. Du kan behöva installera ghostscript om nltk kastar ett fel.

Grunt analyserad nyhetsrubrik
föregående utgång ger en bra känsla av struktur efter Grunt tolkning av nyhetsrubriken.
valkrets Parsing
konstituerande baserade grammatik används för att analysera och bestämma beståndsdelarna i en mening. Dessa grammatik kan användas för att modellera eller representera meningarnas interna struktur i termer av en hierarkiskt ordnad struktur för deras beståndsdelar. Varje ord hör vanligtvis till en specifik lexikal kategori i fallet och bildar huvudordet för olika fraser. Dessa fraser bildas baserat på regler som kallas frasstrukturregler.
Frasstrukturregler utgör kärnan i valkretsgrammatiken, eftersom de talar om syntax och regler som styr hierarkin och ordningen för de olika beståndsdelarna i meningarna. Dessa regler tillgodoser främst två saker.
- de bestämmer vilka ord som används för att konstruera fraser eller beståndsdelar.
- de bestämmer hur vi behöver beställa dessa beståndsdelar tillsammans.
den generiska representationen av en frasstrukturregel är S Bisexuell AB, som visar att strukturen S består av beståndsdelarna A och B , och beställningen är A följt av B . Även om det finns flera regler (se Kapitel 1, Sidan 19: textanalys med Python, om du vill dyka djupare), beskriver den viktigaste regeln hur man delar upp en mening eller en klausul. Frasstrukturregeln betecknar en binär uppdelning för en mening eller en klausul som s Bisexuell NP VP där S är meningen eller klausulen, och den är uppdelad i ämnet, betecknad med substantivfrasen (NP) och predikatet, betecknad med verbfrasen (VP).
en valkretsparser kan byggas baserat på sådana grammatik/regler, som vanligtvis är kollektivt tillgängliga som kontextfri grammatik (CFG) eller frasstrukturerad grammatik. Tolkaren behandlar inmatningsmeningar enligt dessa Regler och hjälper till att bygga ett parsträd.
ett exempel på valkretsanalys som visar en kapslad hierarkisk struktur
Vi kommer att använda nltk och StanfordParser här för att generera tolka träd.
förutsättningar: ladda ner den officiella Stanford-parsern härifrån, vilket verkar fungera ganska bra. Du kan prova en senare version genom att gå till den här webbplatsen och kontrollera avsnittet Release History. Efter nedladdning, packa upp den till en känd plats i ditt filsystem. När du är klar är du nu redo att använda parsern från
nltk, som vi snart kommer att utforska.
Stanford-parsern använder vanligtvis en PCFG (probabilistisk kontextfri grammatik) parser. En PCFG är en kontextfri grammatik som associerar en sannolikhet med var och en av dess produktionsregler. Sannolikheten för ett parsträd som genereras från en PCFG är helt enkelt produktionen av de enskilda sannolikheterna för de produktioner som används för att generera den.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Vi kan se valkretsens parsträd för vår nyhetsrubrik. Låt oss visualisera det för att förstå strukturen bättre.
from IPython.display import displaydisplay(result)
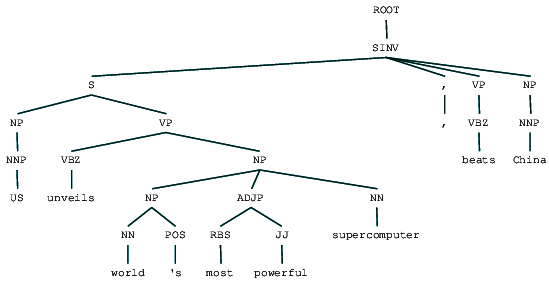
valkrets tolkad nyhetsrubrik
vi kan se den kapslade hierarkiska strukturen hos beståndsdelarna i föregående utgång jämfört med den platta strukturen i grunt parsning. Om du undrar vad SINV betyder representerar den en inverterad deklarativ mening, dvs. en där ämnet följer det spända verbet eller Modalen. Se Penn Treebank-referensen efter behov för att slå upp andra taggar.
Dependency Parsing
i dependency parsing försöker vi använda beroendebaserade grammatik för att analysera och härleda både struktur och semantiska beroenden och relationer mellan tokens i en mening. Grundprincipen bakom en beroende grammatik är att i alla meningar på språket, alla ord utom en, har någon relation eller beroende av andra ord i meningen. Ordet som inte har något beroende kallas roten till meningen. Verbetet tas i de flesta fall som roten till meningen. Alla andra ord är direkt eller indirekt kopplade till rotverbet med hjälp av länkar, vilka är beroenden.
Med tanke på vår mening ”den bruna räven är snabb och han hoppar över den lata hunden”, om vi ville rita beroendesyntaxträdet för detta, skulle vi ha strukturen
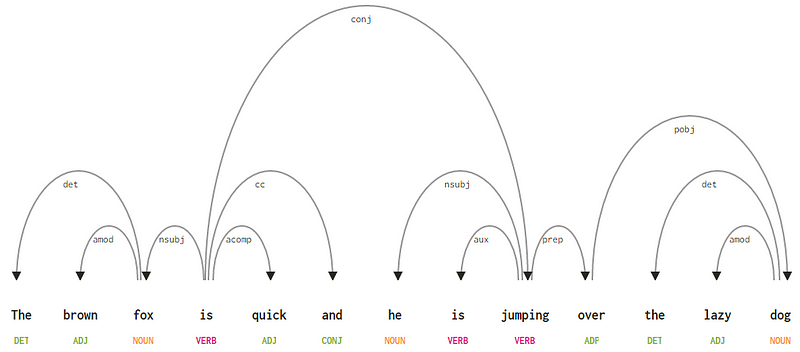
ett beroendeparse träd för en mening
dessa beroendeförhållanden har var och en sin egen betydelse och ingår i en lista över universella beroendetyper. Detta diskuteras i ett originalpapper, Universal Stanford Dependencies: A Cross-Linguistic Typology av de Marneffe et al, 2014). Du kan kolla in den uttömmande listan över beroendetyper och deras betydelser här.
om vi observerar några av dessa beroenden är det inte så svårt att förstå dem.
- dependency tagg det är ganska intuitivt-det betecknar bestämningsförhållandet mellan ett nominellt huvud och bestämaren. Vanligtvis kommer ordet med POS-tagg det också att ha det-beroende-taggrelationen. Exempel är
fox → theochdog → the. - dependency tag Amod står för adjektivmodifierare och står för alla adjektiv som ändrar betydelsen av ett substantiv. Exempel är
fox → brownochdog → lazy. - beroendetaggen nsubj står för en enhet som fungerar som ett ämne eller en agent i en klausul. Exempel är
is → foxochjumping → he. - beroenden cc och conj har mer att göra med kopplingar relaterade till ord kopplade genom att samordna konjunktioner . Exempel är
is → andochis → jumping. - beroendetaggen aux anger hjälp-eller sekundärverbet i klausulen. Exempel:
jumping → is. - dependency tag acomp står för adjektiv komplement och fungerar som komplement eller objekt till ett verb i meningen. Exempel:
is → quick - dependency tag prep betecknar en prepositional modifierare, som vanligtvis ändrar betydelsen av ett substantiv, verb, adjektiv eller preposition. Vanligtvis används denna representation för prepositioner som har ett substantiv eller substantivfras komplement. Exempel:
jumping → over. - beroende-taggen pobj används för att beteckna föremålet för en preposition . Detta är vanligtvis huvudet på en substantivfras efter en preposition i meningen. Exempel:
over → dog.
Spacy hade två typer av engelska beroendeparser baserat på vilka språkmodeller du använder, du kan hitta mer information här. Baserat på språkmodeller kan du använda Universal Dependencies Scheme eller CLEAR Style Dependency Scheme som också finns i NLP4J nu. Vi kommer nu att utnyttja spacy och skriva ut beroenden för varje token i vår nyhetsrubrik.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
det är uppenbart att verbet slår är roten eftersom det inte har några andra beroenden jämfört med de andra tokens. För att veta mer om varje anteckning kan du alltid hänvisa till CLEAR dependency scheme. Vi kan också visualisera ovanstående beroenden på ett bättre sätt.
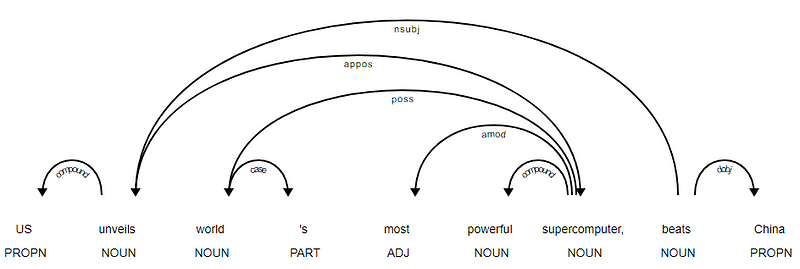
nyheter rubrik beroende träd från SpaCy
Du kan också utnyttja nltk och StanfordDependencyParser för att visualisera och bygga ut beroendeträdet. Vi visar beroendeträdet både i sin råa och annoterade form enligt följande.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
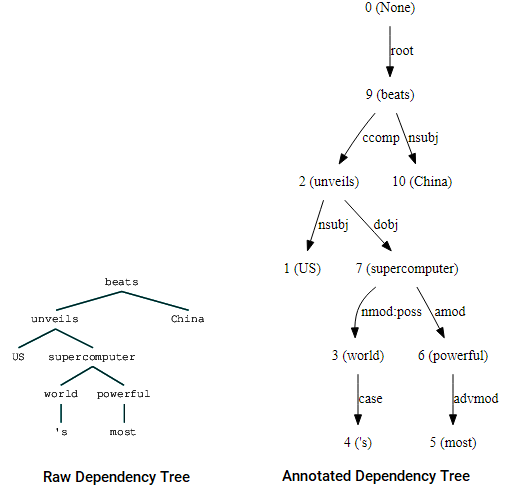
beroende träd visualiseringar använder Nltk: s Stanford dependency parser
Du kan märka likheterna med trädet vi hade fått tidigare. Anteckningarna hjälper till att förstå typen av beroende bland de olika tokens.
Bio: Dipanjan Sarkar är en datavetenskapare @ Intel, en författare, en mentor @Springboard, en författare och en sport-och sitcommissbrukare.
Original. Reposted med tillstånd.
relaterade:
- robusta Word2Vec-modeller med Gensim& tillämpa Word2Vec — funktioner för Maskininlärningsuppgifter
- Human Interpretable Machine Learning (Del 1) – behovet och vikten av Modelltolkning
- implementera djupa inlärningsmetoder och Funktionsteknik för textdata: Skip-gram-modellen