KDnuggets
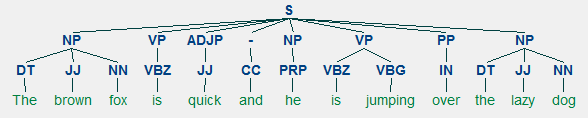
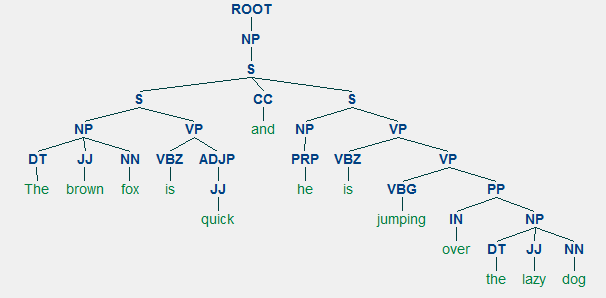
voor elke taal gaan syntaxis en structuur meestal hand in hand, waar een set van specifieke regels, conventies en principes bepalen hoe woorden worden gecombineerd in zinnen; zinnen worden gecombineerd in zinnen; en clausules worden gecombineerd in zinnen. We zullen specifiek praten over de Engelse taal syntaxis en structuur in deze sectie. In het Engels combineren woorden elkaar meestal om andere samenstellende eenheden te vormen. Deze bestanddelen bevatten woorden, zinnen, zinnen en zinnen. Gezien een zin, “de bruine vos is snel en hij springt over de luie hond”, het is gemaakt van een bos van woorden en gewoon kijken naar de woorden zelf niet veel vertellen.

een aantal ongeordende woorden geven niet veel informatie
kennis over de structuur en syntaxis van taal is nuttig in veel gebieden zoals tekstverwerking, annotatie en parsing voor verdere bewerkingen zoals tekstclassificatie of samenvattingen. Typische parseertechnieken voor het begrijpen van tekstsyntaxis worden hieronder vermeld.
- Parts of Speech (POS) Tagging
- ondiepe Parsing of Chunking
- kiesdistrict Parsing
- afhankelijkheid Parsing
We zullen al deze technieken in de volgende secties bekijken. Gezien onze vorige voorbeeldzin “de bruine vos is snel en hij springt over de luie hond”, als we het met behulp van eenvoudige POS-tags zouden annoteren, zou het eruit zien als de volgende figuur.

POS-tagging voor een zin
Dus, een zin meestal volgt een hiërarchische structuur bestaat uit de volgende onderdelen,
zin → clausules → zinnen → woorden
Tagging Delen van Meningsuiting
Onderdelen van de speech (POS) zijn specifieke lexicale categorieën, die woorden zijn toegewezen, op basis van de syntactische context en rol. Meestal kunnen woorden in een van de volgende hoofdcategorieën vallen.
- N (oun): Dit duidt meestal woorden aan die een object of entiteit afbeelden, die al dan niet levend kunnen zijn. Enkele voorbeelden zijn vos, hond, boek, enzovoort. Het POS-tagsymbool voor zelfstandige naamwoorden is N.
- V (erb): werkwoorden zijn woorden die worden gebruikt om bepaalde acties, toestanden of gebeurtenissen te beschrijven. Er zijn een grote verscheidenheid aan andere subcategorieën, zoals hulp -, reflexieve en transitieve werkwoorden (en nog veel meer). Enkele typische voorbeelden van werkwoorden zouden lopen , springen , lezen en schrijven zijn . Het POS-tagsymbool voor werkwoorden is V.
- Adj(ective): Bijvoeglijke naamwoorden zijn woorden die worden gebruikt om andere woorden te beschrijven of te kwalificeren, meestal zelfstandige naamwoorden en zelfstandige zinnen. De zin mooie bloem heeft het zelfstandig naamwoord (N) bloem die wordt beschreven of gekwalificeerd met behulp van het bijvoeglijk naamwoord (ADJ) mooi . Het POS tag symbool voor bijvoeglijke naamwoorden is ADJ .
- Adv(erb): bijwoorden fungeren meestal als modifiers voor andere woorden, waaronder zelfstandige naamwoorden, bijvoeglijke naamwoorden, werkwoorden of andere bijwoorden. De zin zeer mooie bloem heeft het bijwoord (ADV) zeer, Die wijzigt het bijvoeglijk naamwoord (ADJ) mooi, wat aangeeft in welke mate de bloem mooi is. Het POS tag symbool voor bijwoorden is ADV.
naast deze vier hoofdcategorieën van spraak, zijn er andere categorieën die vaak voorkomen in de Engelse taal. Deze omvatten voornaamwoorden, voorzetsels, interjecties, voegwoorden, determiners, en vele anderen. Verder kan elke POS tag zoals het zelfstandig naamwoord (N) verder worden onderverdeeld in categorieën zoals zelfstandige naamwoorden in het enkelvoud (NN), eigennaamwoorden in het enkelvoud(NNP) en zelfstandige naamwoorden in het meervoud (NNS).
het proces van het classificeren en labelen van POS-tags voor woorden die parts of speech tagging of POS tagging worden genoemd . POS-tags worden gebruikt om woorden te annoteren en hun POS weer te geven, wat echt nuttig is om specifieke analyse uit te voeren, zoals het versmallen van zelfstandige naamwoorden en zien welke het meest prominent zijn, woordzin disambiguation, en grammatica analyse. We zullen gebruik maken van zowel nltk en spacy die meestal gebruik maken van de Penn Treebank notatie voor POS tagging.
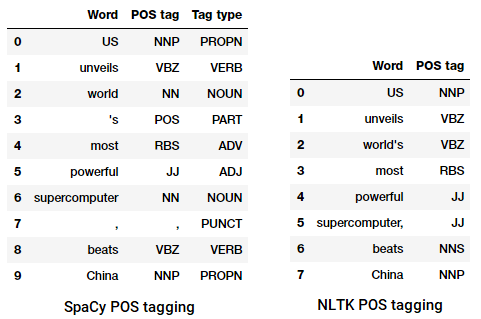
POS tagging a news headline
We kunnen zien dat elk van deze bibliotheken tokens op hun eigen manier behandelen en er specifieke tags voor toewijzen. Gebaseerd op wat we zien, lijkt spacy het iets beter te doen dan nltk.
ondiepe Parsing of Chunking
gebaseerd op de hiërarchie die we eerder hebben afgebeeld, vormen woordgroepen zinnen. Er zijn vijf hoofdcategorieën zinnen:
- Zelfstandig naamwoord zin (NP): Dit zijn zinnen waar een zelfstandig naamwoord fungeert als het hoofdwoord. Zelfstandig naamwoord zinnen fungeren als een onderwerp of object van een werkwoord.
- Werkwoordzin (VP): deze zinnen zijn lexicale eenheden die een werkwoord hebben dat als hoofdwoord fungeert. Meestal zijn er twee vormen van werkwoord zinnen. Een vorm heeft de werkwoordcomponenten evenals andere entiteiten zoals zelfstandige naamwoorden, bijvoeglijke naamwoorden of bijwoorden als Delen van het object.
- adjectieve zin (ADJP): dit zijn zinnen met een bijvoeglijk naamwoord als hoofdwoord. Hun belangrijkste rol is om zelfstandig naamwoorden en voornaamwoorden in een zin te beschrijven of te kwalificeren, en ze zullen voor of na het zelfstandig naamwoord of voornaamwoord worden geplaatst.
- Bijwoordzin (ADVP): deze zinnen werken als bijwoorden omdat het bijwoord fungeert als het hoofdwoord in de zin. Bijwoord zinnen worden gebruikt als modifiers voor zelfstandige naamwoorden, werkwoorden, of bijwoorden zelf door het verstrekken van verdere details die hen beschrijven of kwalificeren.
- Voorzetselzin (PP): deze zinnen bevatten meestal een voorzetsel als het hoofdwoord en andere lexicale componenten zoals zelfstandige naamwoorden, voornaamwoorden, enzovoort. Deze fungeren als een bijvoeglijk naamwoord of bijwoord dat andere woorden of zinnen beschrijft.
ondiepe parsing, ook bekend als lichte parsing of chunking, is een populaire natuurlijke taalverwerkingstechniek om de structuur van een zin te analyseren om deze op te splitsen in de kleinste bestanddelen (tokens zoals woorden) en ze samen te groeperen in zinnen op een hoger niveau. Dit omvat POS tags evenals zinnen uit een zin.
een voorbeeld van ondiepe parsing die uitdrukkingsannotaties van hoger niveau weergeeft
We zullen het conll2000 corpus gebruiken voor het trainen van ons ondiepe parsermodel. Dit corpus is beschikbaar in nltk met chunk annotaties en we zullen ongeveer 10K records gebruiken voor het trainen van ons model. Een voorbeeld geannoteerde zin is als volgt afgebeeld.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
uit de vorige uitvoer kunt u zien dat onze gegevenspunten zinnen zijn die al zijn geannoteerd met zinnen en POS tags metadata die nuttig zullen zijn bij het trainen van ons ondiepe parser model. We zullen gebruik maken van twee chunking utility functies, tree2conlltags, te krijgen triples van word, tag, en chunk tags voor elk token, en conlltags2tree om een ontleden boom van deze token triples te genereren. We zullen deze functies gebruiken om onze parser te trainen. Een voorbeeld is hieronder afgebeeld.
de chunk-tags gebruiken het IOB-formaat. Deze notatie vertegenwoordigt binnen, buiten en het begin. Het B-voorvoegsel voor een tag geeft aan dat het het begin is van een stuk, en het I – voorvoegsel geeft aan dat het in een stuk zit. De O tag geeft aan dat het token niet tot een stuk behoort. De B-tag wordt altijd gebruikt wanneer er volgende tags van hetzelfde type volgen zonder de aanwezigheid van o-tags tussen hen.
We zullen nu een functie definiëren conll_tag_ chunks() uitpakken POS en brok tags van de zinnen met gedeelde annotaties en een functie met de naam combined_taggers() om te trainen meerdere tagger met backoff tagger (bijv. unigram en bigram tagger)
We zullen nu een klasse definiëren NGramTagChunker dat zal in getagde zinnen als training ingang, krijgen hun (word, POS-tag, Deel tag) WTC triples, en de trein een BigramTagger met een UnigramTagger als de backoff tagger. We definiëren ook een parse() functie uit te voeren shallow parsing op nieuwe zinnen
De
UnigramTaggerBigramTagger, enTrigramTaggerzijn klassen die overerven van de klasse baseNGramTagger, die zelf erft van deContextTaggerclass die erft van deSequentialBackoffTaggerklasse.
We zullen deze klasse gebruiken om te trainen op de conll2000 chunked train_data en de modelprestaties te evalueren op de test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
ons chunking model krijgt een nauwkeurigheid van ongeveer 90%, wat heel goed is! Laten we nu gebruik maken van dit model om ondiep ontleden en brokken onze steekproef nieuwsartikel kop die we eerder gebruikt, “ons onthult’ s werelds meest krachtige supercomputer, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
zelfstandig naamwoord zinnen (NP) en een werkwoord zin (VP) in het nieuws artikel. De POS-tags van elk woord zijn ook zichtbaar. We kunnen dit ook visualiseren in de vorm van een boom als volgt. Het kan nodig zijn om ghostscript te installeren als nltk Een fout geeft.

Shallow parsed news headline
de voorgaande output geeft een goed gevoel van structuur na het ondiep ontleden van de nieuws headline.
Kieskringparsing
Op constituenten gebaseerde grammatica ‘ s worden gebruikt om de bestanddelen van een zin te analyseren en te bepalen. Deze grammatica ‘ s kunnen worden gebruikt om de interne structuur van zinnen te modelleren of te vertegenwoordigen in termen van een hiërarchisch geordende structuur van hun bestanddelen. Elk woord behoort gewoonlijk tot een specifieke lexicale categorie in het geval en vormt het hoofdwoord van verschillende zinnen. Deze zinnen worden gevormd op basis van regels genoemd frase structuur regels.
frase structuur regels vormen de kern van kiesdistrict grammatica ‘ s, omdat ze spreken over syntaxis en regels die de hiërarchie en de volgorde van de verschillende bestanddelen in de zinnen. Deze regels hebben voornamelijk betrekking op twee dingen.
- zij bepalen welke woorden worden gebruikt om de zinnen of bestanddelen te construeren.
- zij bepalen hoe we deze bestanddelen samen moeten ordenen.
de Algemene representatie van een zinstructuurregel is S → AB, die aangeeft dat de structuur S bestaat uit bestanddelen A en B , en de volgorde is a gevolgd door B . Hoewel er verschillende regels zijn (zie Hoofdstuk 1, Pagina 19: Text Analytics met Python, als je dieper wilt duiken), beschrijft de belangrijkste regel hoe je een zin of een clausule moet verdelen. De frase Structuur regel geeft een binaire deling aan voor een zin of een zin als S → NP VP waar S de zin of zin is, en het is verdeeld in het onderwerp, aangeduid door het zelfstandig naamwoord zin (NP) en het predicaat, aangeduid door het werkwoord zin (VP).
een kiesdistrict parser kan worden gebouwd op basis van dergelijke grammatica ‘ s/regels, die meestal collectief beschikbaar zijn als context-vrije grammatica (CFG) of frase-gestructureerde grammatica. De parser zal input zinnen verwerken volgens deze regels, en helpen bij het bouwen van een parse boom.
een voorbeeld van kiesdistrict parsing die een geneste hiërarchische structuur toont
we gebruiken nltk en de StanfordParser hier om parse trees te genereren.
vereisten: Download hier de officiële Stanford-Parser, die goed lijkt te werken. U kunt een latere versie uitproberen door naar deze website te gaan en de sectie Release History te controleren. Na het downloaden, unzip het naar een bekende locatie in uw bestandssysteem. Eenmaal klaar, bent u nu klaar om de parser van
nltkte gebruiken , die we binnenkort zullen onderzoeken.
de Stanford-parser gebruikt over het algemeen een pcfg-parser (probabilistic context-free grammar). Een pcfg is een contextvrije grammatica die een waarschijnlijkheid associeert met elk van zijn productie regels. De waarschijnlijkheid van een parse boom gegenereerd uit een PCFG is gewoon de productie van de individuele waarschijnlijkheden van de producties gebruikt om het te genereren.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
We kunnen de kiesdistrict parse tree zien voor onze nieuws headline. Laten we het visualiseren om de structuur beter te begrijpen.
from IPython.display import displaydisplay(result)
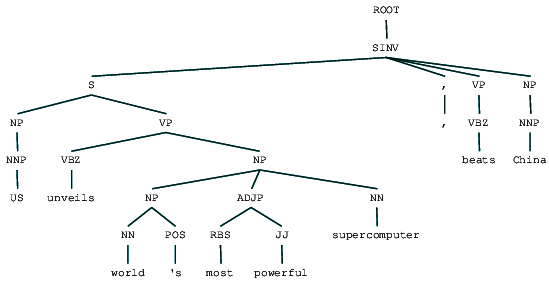
kiesdistrict parsed news headline
we kunnen de geneste hiërarchische structuur van de bestanddelen in de voorgaande uitvoer zien in vergelijking met de platte structuur in ondiepe parsing. In het geval u zich afvraagt wat SINV betekent, het vertegenwoordigt een omgekeerde declaratieve zin, dat wil zeggen een waarin het onderwerp volgt het gespannen werkwoord of modaal. Refereer naar de Penn Treebank referentie zoals nodig is om andere tags op te zoeken.
Dependency Parsing
Bij dependency parsing proberen we op afhankelijkheid gebaseerde grammatica ‘ s te gebruiken om zowel structuur als semantische afhankelijkheden en relaties tussen tokens in een zin te analyseren en af te leiden. Het basisprincipe achter een afhankelijkheids grammatica is dat in elke zin in de taal, alle woorden behalve één, een relatie of afhankelijkheid hebben van andere woorden in de zin. Het woord dat geen afhankelijkheid heeft wordt de wortel van de zin genoemd. Het werkwoord wordt in de meeste gevallen als de wortel van de zin genomen. Alle andere woorden zijn direct of indirect gekoppeld aan het root werkwoord met behulp van links, die de afhankelijkheden zijn.
Gezien onze zin “Het brown fox is snel en hij springt over the lazy dog”, als we wilde trekken om de afhankelijkheid syntax-boom voor deze, zouden we de structuur
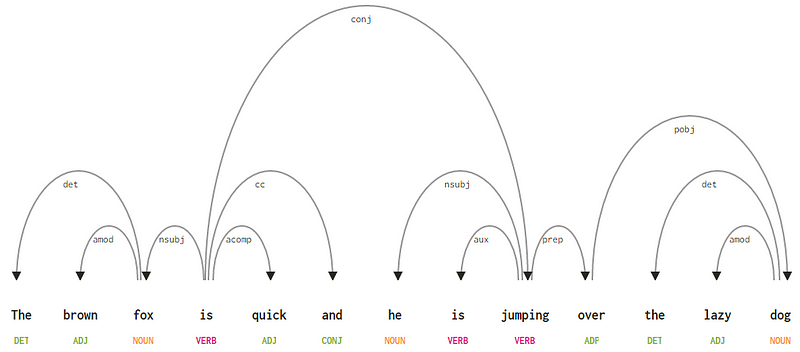
Een afhankelijkheid parse tree voor een zin
Deze afhankelijkheidsrelatie hebben elk hun eigen betekenis en zijn een onderdeel van een lijst van universele afhankelijkheid soorten. Dit wordt besproken in een origineel artikel, Universal Stanford Dependencies: A Cross-Linguistic Typology door de Marneffe et al, 2014). U kunt de uitputtende lijst van afhankelijkheidstypen en hun betekenissen hier bekijken.
als we enkele van deze afhankelijkheden waarnemen, is het niet al te moeilijk om ze te begrijpen.
- De dependency tag det is vrij intuïtief — het geeft de determiner relatie aan tussen een nominale head en de determiner. Meestal zal het woord met POS tag DET ook de det dependency tag relatie hebben. Voorbeelden hiervan zijn
fox → theendog → the. - de dependency tag amod staat voor adjectival modifier en staat voor elk bijvoeglijk naamwoord dat de Betekenis van een zelfstandig naamwoord wijzigt. Voorbeelden hiervan zijn
fox → brownendog → lazy. - de dependency tag nsubj staat voor een entiteit die optreedt als een subject of agent in een clausule. Voorbeelden hiervan zijn
is → foxenjumping → he. - de afhankelijkheden cc en conj hebben meer te maken met koppelingen gerelateerd aan woorden verbonden door coördinerende voegwoorden . Voorbeelden hiervan zijn
is → andenis → jumping. - de dependency tag aux geeft het hulp-of secundaire werkwoord in de zin aan. Voorbeeld:
jumping → is. - de dependency tag acomp staat voor adjectief complement en fungeert als het complement of object van een werkwoord in de zin. Voorbeeld:
is → quick - De dependency tag prep geeft een voorzetsel modifier aan, die meestal de Betekenis van een zelfstandig naamwoord, werkwoord, bijvoeglijk naamwoord of voorzetsel wijzigt. Meestal wordt deze representatie gebruikt voor voorzetsels met een zelfstandig naamwoord of een zelfstandig naamwoord zin complement. Voorbeeld:
jumping → over. - de dependency tag pobj wordt gebruikt om het object van een voorzetsel aan te duiden . Dit is meestal het hoofd van een zelfstandig naamwoord na een voorzetsel in de zin. Voorbeeld:
over → dog.
Spacy had twee soorten Engelse dependency parsers gebaseerd op welke taalmodellen je gebruikt, je kunt hier meer details vinden. Op basis van taalmodellen kunt u het Universal Dependencies Scheme of het clear Style Dependencies Scheme nu ook beschikbaar in NLP4J gebruiken. We zullen nu gebruik maken van spacy en de afhankelijkheden voor elk token afdrukken in onze nieuws headline.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
Het is duidelijk dat het werkwoord beats de ROOT is omdat het geen andere afhankelijkheden heeft in vergelijking met de andere tokens. Voor meer informatie over elke annotatie kunt u altijd verwijzen naar het duidelijke afhankelijkheidsschema. We kunnen ook de bovenstaande afhankelijkheden op een betere manier visualiseren.
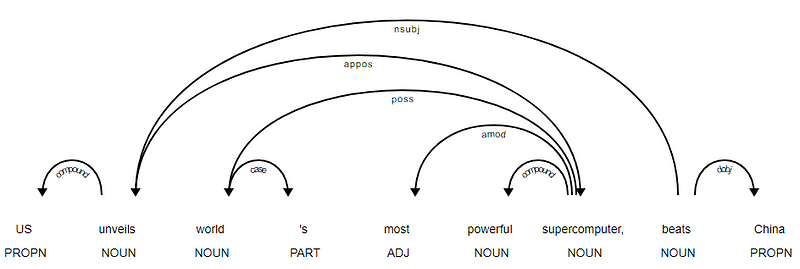
News Headline dependency tree from SpaCy
u kunt ook gebruik maken van nltk en de StanfordDependencyParser naar visualiseer en bouw de afhankelijkheidsboom op. We laten de dependency tree zowel in zijn ruwe als geannoteerde vorm als volgt zien.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
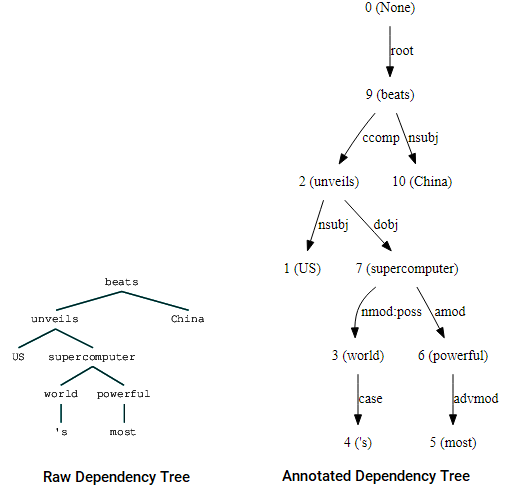
Dependency Tree visualisations using nltk ‘ s Stanford dependency parser
u kunt de overeenkomsten met de boom die we eerder hadden verkregen opmerken. De annotaties helpen bij het begrijpen van het type afhankelijkheid tussen de verschillende tokens.Bio: Dipanjan Sarkar is een Data Scientist @Intel, een auteur, een mentor @Springboard, een schrijver, en een sport-en sitcomverslaafde.
origineel. Opnieuw geplaatst met toestemming.
gerelateerd:
- robuuste Word2Vec-modellen met Gensim & Word2Vec-functies toepassen voor Machine Learning-taken
- Human Interpretable Machine Learning (Part 1) – de noodzaak en het belang van Modelinterpretatie
- implementatie van Deep Learning-methoden en Feature Engineering voor tekstgegevens: het skip-gram-Model