KDnuggets
pentru orice limbă, sintaxa și structura merg de obicei mână în mână, unde un set de reguli, convenții și principii specifice guvernează modul în care cuvintele sunt combinate în fraze; frazele se combină în clauze; iar clauzele se combină în propoziții. Vom vorbi în mod specific despre sintaxa și structura limbii engleze în această secțiune. În engleză, Cuvintele se combină de obicei pentru a forma alte unități constitutive. Acești constituenți includ cuvinte, fraze, clauze și propoziții. Având în vedere o propoziție, „vulpea brună este rapidă și sare peste câinele leneș”, este făcută dintr-o grămadă de cuvinte și doar privirea cuvintelor de la sine nu ne spune prea multe.

O grămadă de cuvinte neordonate nu transmit prea multe informații
cunoștințele despre structura și sintaxa limbajului sunt utile în multe domenii precum procesarea textului, adnotarea și parsarea pentru operații suplimentare, cum ar fi clasificarea textului sau sumarizarea. Tehnicile tipice de analiză pentru înțelegerea sintaxei textului sunt menționate mai jos.
- părți de vorbire (POS) Tagging
- parsare superficială sau Chunking
- parsarea Circumscripției Electorale
- parsarea dependenței
vom analiza toate aceste tehnici în secțiunile ulterioare. Având în vedere propoziția noastră anterioară de exemplu „vulpea brună este rapidă și sare peste câinele leneș”, dacă ar fi să o adnotăm folosind etichete POS de bază, ar arăta ca următoarea figură.

etichetarea POS pentru o propoziție
astfel, o propoziție urmează de obicei o structură ierarhică formată din următoarele componente,
propozitie clauze si expresii si expresii si cuvinte
tagging parts of speech
Parts of speech (POS) sunt categorii lexicale specifice carora li se atribuie cuvinte, pe baza contextului si rolului lor sintactic. De obicei, cuvintele se pot încadra într-una din următoarele categorii majore.
- N(oun): Acest lucru denotă de obicei cuvinte care descriu un obiect sau entitate, care poate fi viu sau nonliving. Câteva exemple ar fi vulpea , câinele , cartea și așa mai departe. Simbolul etichetei POS pentru substantive este N.
- V (erb): verbele sunt cuvinte care sunt folosite pentru a descrie anumite acțiuni, stări sau evenimente. Există o mare varietate de subcategorii suplimentare, cum ar fi verbele auxiliare, reflexive și tranzitive (și multe altele). Unele exemple tipice de verbe ar fi alergarea , săriturile , citirea și scrierea . Simbolul etichetei POS pentru verbe este V.
- Adj (ectiv): Adjectivele sunt cuvinte folosite pentru a descrie sau califica alte cuvinte, de obicei substantive și fraze substantive. Expresia floare frumoasă are substantivul (n) floare care este descris sau calificat folosind adjectivul (ADJ) frumos . Simbolul etichetei POS pentru adjective este ADJ .
- Adv (erb): adverbele acționează de obicei ca modificatori pentru alte cuvinte, inclusiv substantive, adjective, verbe sau alte adverbe. Fraza floare foarte frumoasă are adverb (ADV) foarte, care modifică adjectivul (ADJ) frumos , indicând gradul în care floarea este frumoasă. Simbolul etichetei POS pentru adverbe este ADV.
pe lângă aceste patru categorii majore de părți de vorbire , există și alte categorii care apar frecvent în limba engleză. Acestea includ pronume, prepoziții, interjecții, conjuncții, Determinanți și multe altele. Mai mult, fiecare etichetă POS precum substantivul (N) poate fi împărțită în categorii precum substantive singulare(NN), substantive proprii singulare (NNP) și substantive plural (NNS).
procesul de clasificare și etichetare POS tag-uri pentru cuvinte numite părți de vorbire tagging sau POS tagging . Etichetele POS sunt folosite pentru a adnota cuvinte și a descrie POS-ul lor, ceea ce este foarte util pentru a efectua analize specifice, cum ar fi îngustarea substantivelor și a vedea care sunt cele mai proeminente, dezambiguizarea sensului cuvântului și analiza gramaticală. Vom folosi atât nltk, cât și spacy care folosesc de obicei notația Penn Treebank pentru etichetarea POS.
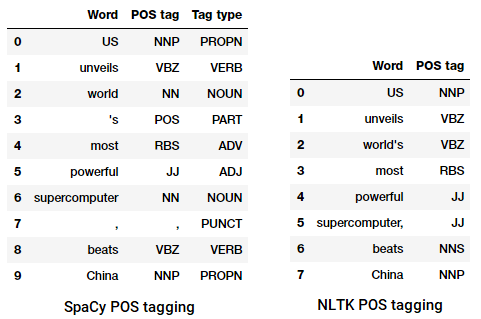
POS etichetând un titlu de știri
putem vedea că fiecare dintre aceste biblioteci tratează jetoanele în felul lor și le atribuie etichete specifice. Pe baza a ceea ce vedem, spacy pare să se descurce puțin mai bine decât nltk.
parsare superficială sau Chunking
pe baza ierarhiei pe care am descris-o mai devreme, grupuri de cuvinte alcătuiesc fraze. Există cinci categorii majore de fraze:
- sintagma substantivală (NP): Acestea sunt fraze în care un substantiv acționează ca cuvânt principal. Expresiile substantive acționează ca subiect sau obiect al unui verb.
- frază verbală (VP): aceste fraze sunt unități lexicale care au un verb care acționează ca cuvânt principal. De obicei, există două forme de fraze verbale. O formă are componentele verbului, precum și alte entități, cum ar fi substantive, adjective sau adverbe ca părți ale obiectului.
- fraza adjectivală (ADJP): acestea sunt fraze cu un adjectiv ca cuvânt principal. Rolul lor principal este de a descrie sau califica substantive și pronume într-o propoziție și vor fi plasate fie înainte, fie după substantiv sau pronume.
- adverb phrase (ADVP): aceste fraze acționează ca adverbe, deoarece adverbul acționează ca cuvântul principal din frază. Frazele Adverb sunt folosite ca modificatori pentru substantive, verbe sau adverbe, oferind detalii suplimentare care le descriu sau le califică.
- frază prepozițională (PP): aceste fraze conțin de obicei o prepoziție ca cuvânt principal și alte componente lexicale precum substantive, pronume și așa mai departe. Acestea acționează ca un adjectiv sau adverb care descrie alte cuvinte sau fraze.
parsarea superficială, cunoscută și sub numele de parsare ușoară sau chunking, este o tehnică populară de procesare a limbajului natural de analiză a structurii unei propoziții pentru a o descompune în cele mai mici constituenți (care sunt jetoane precum cuvinte) și grupați-le împreună în fraze de nivel superior. Aceasta include etichete POS, precum și fraze dintr-o propoziție.
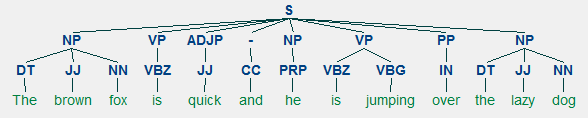
un exemplu de parsare superficială care prezintă adnotări de frază de nivel superior
vom folosi corpusulconll2000 pentru formarea modelului nostru de parser superficial. Acest corpus este disponibil în nltk cu adnotări de bucăți și vom folosi în jur de 10K înregistrări pentru instruirea modelului nostru. O propoziție adnotată de probă este descrisă după cum urmează.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
Din rezultatul precedent, puteți vedea că punctele noastre de date sunt propoziții care sunt deja adnotate cu fraze și etichete POS metadate care vor fi utile în formarea modelului nostru parser superficial. Vom folosi două funcții de utilitate chunking, tree2colltags, pentru a obține triple de etichete word, tag și chunk pentru fiecare jeton și conlltags2tree pentru a genera un arbore de analiză din aceste triple token. Vom folosi aceste funcții pentru a ne antrena parserul. Un eșantion este prezentat mai jos.
etichetele bucată folosesc formatul IOB. Această notație reprezintă interiorul, exteriorul și începutul. Prefixul B înaintea unei etichete indică faptul că este începutul unei bucăți, iar prefixul i indică faptul că se află în interiorul unei bucăți. Eticheta o indică faptul că jetonul nu aparține niciunei bucăți. Eticheta B este întotdeauna utilizată atunci când există etichete ulterioare de același tip care o urmează fără prezența etichetelor O între ele.
vom defini acum o funcție conll_tag_ chunks() pentru a extrage POS și tag-uri bucată de propoziții cu adnotări chunked și o funcție numită combined_taggers() pentru a instrui mai multe taggers cu taggers backoff (de exemplu, unigram și taggers bigram)
vom defini acum o clasă NGramTagChunker care va lua în propoziții etichetate ca intrare de formare, pentru a primi lor (cuvânt, POS tag-ul, tag-ul bucată) WTC triple, și tren un BigramTagger cu un UnigramTagger ca Tagger backoff. De asemenea, vom defini o parse() funcție pentru a efectua parsarea superficială pe propoziții noi
UnigramTaggerBigramTaggerșiTrigramTaggersunt clase care moștenesc din clasa de bazăNGramTagger, care moștenește din clasaContextTagger, care moștenește din clasaSequentialBackoffTagger.
vom folosi această clasă pentru a ne antrena pe conll2000 chunked train_data și pentru a evalua performanța modelului pe test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
modelul nostru chunking obține o precizie de aproximativ 90%, ceea ce este destul de bun! Să pârghie acum acest model pentru a analiza superficial și bucată titlul nostru articol de știri eșantion pe care am folosit mai devreme, „SUA dezvaluie cel mai puternic supercomputer din lume, bate China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
astfel, puteți vedea că a identificat două fraze substantivale (NP) și o frază verbală (VP) în articolul de știri. Etichetele POS ale fiecărui cuvânt sunt, de asemenea, vizibile. De asemenea, putem vizualiza acest lucru sub forma unui copac după cum urmează. Este posibil să fie nevoie să instalați ghostscript în cazul în care nltk aruncă o eroare.

Shallow parsed news headline
ieșirea precedentă oferă un bun simț al structurii după parsarea superficială a titlului știrilor.
analiza circumscripției
gramaticile bazate pe constituenți sunt folosite pentru a analiza și determina constituenții unei propoziții. Aceste gramatici pot fi folosite pentru a modela sau reprezenta structura internă a propozițiilor în termeni de structură ordonată ierarhic a constituenților lor. Fiecare cuvânt aparține de obicei unei categorii lexicale specifice în acest caz și formează cuvântul principal al diferitelor fraze. Aceste fraze sunt formate pe baza regulilor numite reguli de structură a frazelor.
Regulile structurii frazelor formează nucleul gramaticilor de circumscripție, deoarece vorbesc despre sintaxă și reguli care guvernează ierarhia și ordonarea diferiților constituenți din propoziții. Aceste reguli se referă în primul rând la două lucruri.
- ele determină ce cuvinte sunt folosite pentru a construi frazele sau constituenții.
- ele determină modul în care trebuie să ordonăm acești constituenți împreună.
reprezentarea generică a unei reguli de structură a frazelor este S INKTU AB , care descrie că structura S este formată din constituenții a și B , iar ordonarea este a urmată de B . Deși există mai multe reguli (consultați Capitolul 1, Pagina 19: analiza textului cu Python, dacă doriți să vă scufundați mai adânc), cea mai importantă regulă descrie cum să împărțiți o propoziție sau o clauză. Regula structurii frazei denotă o diviziune binară pentru o propoziție sau o clauză ca s NP VP unde S este propoziția sau clauza și este împărțită în subiect, notată cu sintagma nominală (NP) și predicatul, notată cu fraza verbală (VP).
un analizor de circumscripție poate fi construit pe baza unor astfel de gramatici / reguli, care sunt de obicei disponibile în mod colectiv ca Gramatică fără context (CFG) sau gramatică structurată pe fraze. Parserul va procesa propoziții de intrare în conformitate cu aceste reguli și va ajuta la construirea unui arbore de analiză.
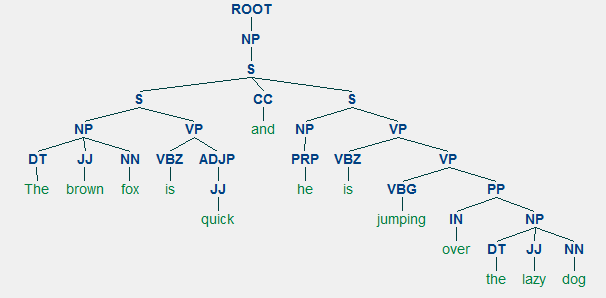
un exemplu de analiză a circumscripției care arată o structură ierarhică imbricată
vom folosi nltk și StanfordParser aici pentru a genera arbori de analiză.
Cerințe preliminare: descărcați parserul Oficial Stanford de aici, care pare să funcționeze destul de bine. Puteți încerca o versiune ulterioară accesând acest site web și verificând secțiunea Istoricul lansărilor. După descărcare, dezarhivați-l într-o locație cunoscută din sistemul de fișiere. Odată terminat, acum sunteți gata să utilizați parserul de la
nltk, pe care îl vom explora în curând.
parserul Stanford folosește în general un parser PCFG (probabilistic context-free grammar). Un PCFG este o gramatică fără context care asociază o probabilitate cu fiecare dintre regulile sale de producție. Probabilitatea unui arbore de analiză generat dintr-un PCFG este pur și simplu producerea probabilităților individuale ale producțiilor utilizate pentru a-l genera.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
putem vedea arborele de analiză a circumscripției pentru titlul știrilor noastre. Să o vizualizăm pentru a înțelege mai bine structura.
from IPython.display import displaydisplay(result)
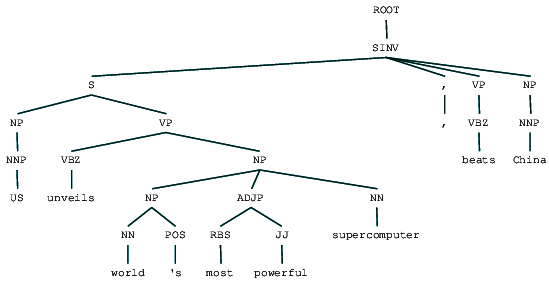
buletinul de știri analizat de circumscripție
putem vedea structura ierarhică imbricată a constituenților în ieșirea precedentă în comparație cu structura plană în analiza superficială. În cazul în care vă întrebați ce înseamnă SINV, reprezintă o propoziție declarativă inversată, adică una în care subiectul urmează verbul tensionat sau modal. Consultați referința Penn Treebank după cum este necesar pentru a căuta alte etichete.
parsarea dependenței
în parsarea dependenței, încercăm să folosim gramaticile bazate pe dependență pentru a analiza și deduce atât structura, cât și dependențele semantice și relațiile dintre jetoane într-o propoziție. Principiul de bază din spatele unei gramatici de dependență este că, în orice propoziție din limbă, Toate cuvintele, cu excepția unuia, au o relație sau dependență de alte cuvinte din propoziție. Cuvântul care nu are dependență se numește rădăcina propoziției. Verbul este luat ca rădăcină a propoziției în majoritatea cazurilor. Toate celelalte cuvinte sunt legate direct sau indirect de verbul rădăcină folosind legături, care sunt dependențele.
având în vedere propoziția noastră „vulpea brună este rapidă și sare peste câinele leneș”, dacă am dori să desenăm arborele sintaxei dependenței pentru aceasta, am avea structura
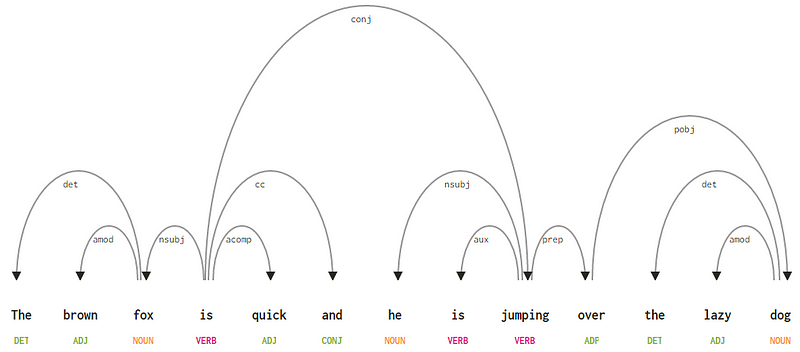
un arbore de analiză a dependenței pentru o propoziție
dacă observăm unele dintre aceste dependențe, nu este prea greu să le înțelegem.
- eticheta de dependență det este destul de intuitivă — denotă relația determinatorului dintre un cap nominal și determinant. De obicei, cuvântul cu POS tag det va avea, de asemenea, relația TAG de dependență det. Exemplele includ
fox → theșidog → the. - eticheta de dependență amod înseamnă modificator adjectival și reprezintă orice adjectiv care modifică semnificația unui substantiv. Exemplele includ
fox → brownșidog → lazy. - eticheta de dependență nsubj reprezintă o entitate care acționează ca subiect sau agent într-o clauză. Exemplele includ
is → foxșijumping → he. - dependențele cc și conj au mai mult de-a face cu legăturile legate de cuvintele conectate prin coordonarea conjuncțiilor . Exemplele includ
is → andșiis → jumping. - eticheta de dependență aux indică verbul auxiliar sau secundar din clauză. Exemplu:
jumping → is. - eticheta de dependență acomp înseamnă complement adjectiv și acționează ca complement sau obiect la un verb din propoziție. Exemplu:
is → quick - eticheta de dependență prep denotă un modificator prepozițional, care modifică De obicei semnificația unui substantiv, verb, adjectiv sau prepoziție. De obicei, această reprezentare este utilizată pentru prepoziții care au un complement substantiv sau substantiv. Exemplu:
jumping → over. - eticheta de dependență pobj este utilizată pentru a desemna obiectul unei prepoziții . Acesta este de obicei capul unei fraze substantive după o prepoziție din propoziție. Exemplu:
over → dog.
Spacy a avut două tipuri de analizoare de dependență engleză bazate pe modelele de limbă pe care le utilizați, puteți găsi mai multe detalii aici. Pe baza modelelor lingvistice, puteți utiliza schema de dependențe universale sau schema de dependență de stil clar disponibilă și în NLP4J acum. Acum vom folosi spacy și vom imprima dependențele pentru fiecare jeton în titlul nostru de știri.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
este evident că verbul bate este rădăcina, deoarece nu are alte dependențe în comparație cu celelalte jetoane. Pentru a afla mai multe despre fiecare adnotare, puteți consulta întotdeauna schema de dependență clară. De asemenea, putem vizualiza dependențele de mai sus într-un mod mai bun.
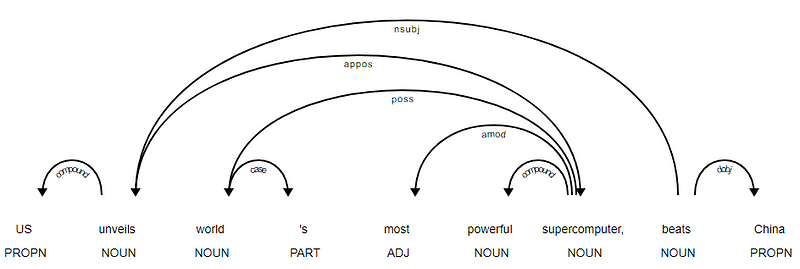
arborele de dependență al titlurilor de știri de la SpaCy
De asemenea, puteți utiliza nltk și StanfordDependencyParser pentru a vizualiza și a construi arborele de dependență. Prezentăm arborele de dependență atât în forma sa brută, cât și în cea adnotată, după cum urmează.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
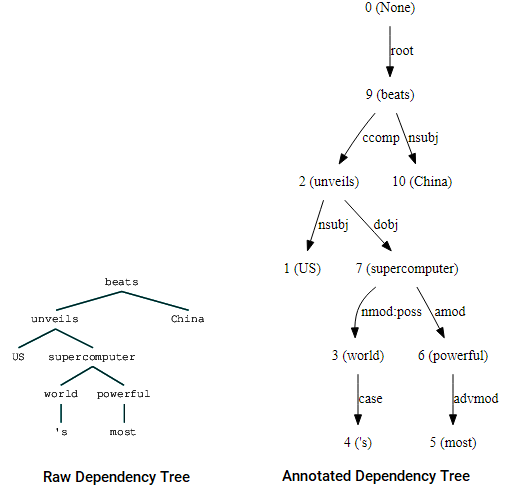
vizualizări ale arborelui de dependență folosind parserul de dependență Stanford de la Nltk
puteți observa asemănările cu arborele pe care l-am obținut mai devreme. Adnotările ajută la înțelegerea tipului de dependență dintre diferitele jetoane.
Bio: Dipanjan Sarkar este un om de știință de date @Intel, un autor, un mentor @Springboard, un scriitor și un dependent de sport și sitcom.
Original. Repostat cu permisiune.
înrudite:
- Modele robuste Word2Vec cu Gensim & aplicarea caracteristicilor Word2Vec pentru sarcini de învățare automată
- învățarea automată interpretabilă umană (Partea 1) — necesitatea și importanța interpretării modelului
- implementarea metodelor de învățare profundă și Ingineria caracteristicilor pentru date Text: Modelul Skip-gram