KDnuggets

Ein Haufen ungeordneter Wörter vermittelt nicht viele Informationen
Kenntnisse über die Struktur und Syntax von Sprache sind in vielen Bereichen wie Textverarbeitung, Annotation und Parsing für weitere Operationen wie Textklassifizierung oder Zusammenfassung hilfreich. Typische Analysetechniken zum Verständnis der Textsyntax werden im Folgenden erwähnt.
- Parts of Speech (POS) Tagging
- Shallow Parsing oder Chunking
- Constituency Parsing
- Dependency Parsing
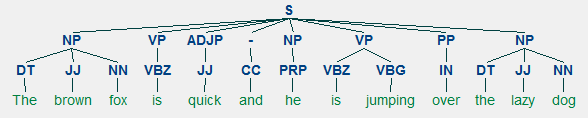
Wir werden uns alle diese Techniken in den folgenden Abschnitten ansehen. Wenn wir unseren vorherigen Beispielsatz „Der braune Fuchs ist schnell und springt über den faulen Hund“ betrachten, würde er wie in der folgenden Abbildung aussehen, wenn wir ihn mit grundlegenden POS-Tags kommentieren würden.

POS-Tagging für einen Satz
Somit folgt ein Satz typischerweise einer hierarchischen Struktur, die aus folgenden Komponenten besteht:
Satz → Klauseln → Phrasen → Wörter
Wortarten markieren
Wortarten (POS) sind spezifische lexikalische Kategorien, denen Wörter basierend auf ihrem syntaktischen Kontext und ihrer Rolle zugewiesen werden. Normalerweise können Wörter in eine der folgenden Hauptkategorien fallen.
- N(oun): Dies bezeichnet normalerweise Wörter, die ein Objekt oder eine Entität darstellen, die leben oder nicht leben kann. Einige Beispiele wären Fuchs , Hund , Buch und so weiter. Das POS-Tag-Symbol für Substantive ist N.
- V(erb): Verben sind Wörter, die verwendet werden, um bestimmte Aktionen, Zustände oder Ereignisse zu beschreiben. Es gibt eine Vielzahl weiterer Unterkategorien, wie Hilfsverben, reflexive und transitive Verben (und viele mehr). Einige typische Beispiele für Verben wären Laufen , Springen , Lesen und Schreiben . Das POS-Tag-Symbol für Verben ist V.
- Adj(ective): Adjektive sind Wörter, die verwendet werden, um andere Wörter zu beschreiben oder zu qualifizieren, typischerweise Substantive und Nominalphrasen. Die Phrase schöne Blume hat das Substantiv (N) Blume, die mit dem Adjektiv (ADJ) schön beschrieben oder qualifiziert wird . Das POS-Tag-Symbol für Adjektive ist ADJ .Adv(erb): Adverbien fungieren normalerweise als Modifikatoren für andere Wörter, einschließlich Substantive, Adjektive, Verben oder andere Adverbien. Die Phrase sehr schöne Blume hat das Adverb (ADV) sehr , was das Adjektiv modifiziert (ADJ) schön , Angabe des Grades, in dem die Blume schön ist. Das POS-Tag-Symbol für Adverbien ist ADV.
Neben diesen vier Hauptkategorien von Wortarten gibt es weitere Kategorien, die in der englischen Sprache häufig vorkommen. Dazu gehören Pronomen, Präpositionen, Interjektionen, Konjunktionen, Determinatoren und viele andere. Darüber hinaus kann jedes POS-Tag wie das Substantiv (N) weiter in Kategorien wie Singular-Substantive (NN), Singular-Eigennamen (NNP) und Plural-Substantive (NNS) unterteilt werden.
Der Prozess der Klassifizierung und Kennzeichnung von POS-Tags für Wörter, die als Parts of Speech-Tagging oder POS-Tagging bezeichnet werden . POS-Tags werden verwendet, um Wörter zu kommentieren und ihre POS darzustellen, was sehr hilfreich ist, um spezifische Analysen durchzuführen, z. B. die Eingrenzung von Substantiven und die Feststellung, welche die prominentesten sind, die Begriffsklärung von Wörtern und die Grammatikanalyse. Wir werden sowohl nltk als auch spacy die normalerweise die Penn Treebank Notation für POS-Tagging verwenden.
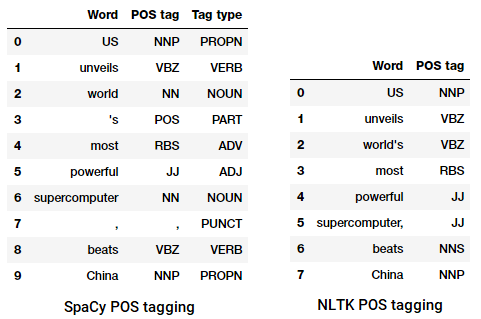
POS-Tagging einer Schlagzeile
Wir können sehen, dass jede dieser Bibliotheken Token auf ihre eigene Weise behandelt und ihnen bestimmte Tags zuweist. Basierend auf dem, was wir sehen, scheint spacy etwas besser zu sein als nltk .
Flaches Parsen oder Chunking
Basierend auf der zuvor dargestellten Hierarchie bilden Wortgruppen Phrasen. Es gibt fünf Hauptkategorien von Phrasen:
- Nominalphrase (NP): Dies sind Sätze, in denen ein Substantiv als Kopfwort fungiert. Substantivphrasen fungieren als Subjekt oder Objekt für ein Verb.
- Verbphrase (VP): Diese Phrasen sind lexikalische Einheiten, bei denen ein Verb als Kopfwort fungiert. Normalerweise gibt es zwei Formen von Verbphrasen. Eine Form hat die Verbkomponenten sowie andere Entitäten wie Substantive, Adjektive oder Adverbien als Teile des Objekts.
- Adjektivphrase (ADJP): Dies sind Phrasen mit einem Adjektiv als Kopfwort. Ihre Hauptaufgabe besteht darin, Substantive und Pronomen in einem Satz zu beschreiben oder zu qualifizieren, und sie werden entweder vor oder nach dem Substantiv oder Pronomen platziert.
- Adverb phrase (ADVP): Diese Phrasen verhalten sich wie Adverbien, da das Adverb als Kopfwort in der Phrase fungiert. Adverb-Phrasen werden als Modifikatoren für Substantive, Verben oder Adverbien selbst verwendet, indem weitere Details angegeben werden, die sie beschreiben oder qualifizieren.
- Präpositionalphrase (PP): Diese Phrasen enthalten normalerweise eine Präposition als Kopfwort und andere lexikalische Komponenten wie Substantive, Pronomen usw. Diese wirken wie ein Adjektiv oder Adverb, das andere Wörter oder Phrasen beschreibt.
Shallow Parsing, auch als Light Parsing oder Chunking bekannt, ist eine beliebte Technik zur Verarbeitung natürlicher Sprache, bei der die Struktur eines Satzes analysiert wird, um ihn in seine kleinsten Bestandteile (Token wie Wörter) aufzuteilen und sie zu übergeordneten Phrasen zusammenzufassen. Dazu gehören POS-Tags sowie Phrasen aus einem Satz.
Ein Beispiel für flaches Parsing, das Phrasenanmerkungen auf höherer Ebene darstellt
Wir werden den conll2000 Korpus für das Training unseres flachen Parsermodells nutzen. Dieser Korpus ist in nltk mit Chunk-Annotationen verfügbar und wir werden etwa 10K Datensätze für das Training unseres Modells verwenden. Ein mit Anmerkungen versehener Beispielsatz wird wie folgt dargestellt.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
Aus der vorhergehenden Ausgabe können Sie sehen, dass unsere Datenpunkte Sätze sind, die bereits mit Phrasen und POS-Tags-Metadaten versehen sind, die beim Training unseres flachen Parser-Modells nützlich sein werden. Wir werden zwei Chunking-Utility-Funktionen nutzen, tree2conlltags , um Tripel von Wort-, Tag- und Chunk-Tags für jedes Token zu erhalten, und conlltags2tree, um aus diesen Token-Tripeln einen Analysebaum zu generieren. Wir werden diese Funktionen verwenden, um unseren Parser zu trainieren. Ein Beispiel ist unten dargestellt.
Die Chunk-Tags verwenden das IOB-Format. Diese Notation repräsentiert Innen, Außen und Anfang. Das B- Präfix vor einem Tag gibt an, dass es der Anfang eines Blocks ist, und das I- Präfix gibt an, dass es sich innerhalb eines Blocks befindet. Das O-Tag gibt an, dass das Token zu keinem Chunk gehört. Das B-Tag wird immer verwendet, wenn nachfolgende Tags desselben Typs folgen, ohne dass O-Tags dazwischen vorhanden sind.
Wir definieren nun eine Funktion conll_tag_ chunks() um POS- und Chunk-Tags aus Sätzen mit Chunk-Annotationen zu extrahieren und eine Funktion namens combined_taggers() um mehrere Tagger mit Backoff-Taggern zu trainieren (z. B. Unigram- und Bigram-Tagger)
Wir definieren nun eine Klasse NGramTagChunker , das markierte Sätze als Trainingseingabe aufnimmt, ihre (Wort-, POS-Tag, Chunk-Tag) WTC-Tripel erhält und ein BigramTagger mit einem UnigramTagger als Backoff-Tagger trainiert. Wir werden auch eine parse() Funktion definieren, um eine flache Analyse neuer Sätze durchzuführen
Die
UnigramTaggerBigramTaggerundTrigramTaggersind Klassen, die von der BasisklasseNGramTaggererben, die selbst von derContextTaggerKlasse erbt, die von derSequentialBackoffTaggerKlasse erbt.
Wir werden diese Klasse verwenden, um auf dem conll2000 chunked train_data zu trainieren und die Modellleistung auf dem test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
Unser Chunking-Modell erreicht eine Genauigkeit von rund 90%, was ziemlich gut ist! Lassen Sie uns nun dieses Modell nutzen, um unsere Beispiel-Schlagzeile des Nachrichtenartikels, die wir zuvor verwendet haben, flach zu analysieren und zu teilen: „US enthüllt den leistungsstärksten Supercomputer der Welt, schlägt China“.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
So können Sie sehen, dass es identifiziert wurde zwei Nominalphrasen (NP) und eine Verbphrase (VP) im Nachrichtenartikel. Die POS-Tags jedes Wortes sind ebenfalls sichtbar. Wir können dies auch in Form eines Baumes wie folgt visualisieren. Möglicherweise müssen Sie ghostscript installieren, falls nltk einen Fehler auslöst.

Flach geparste Schlagzeile
Die vorhergehende Ausgabe vermittelt ein gutes Gefühl für die Struktur nach dem flachen Parsen der Schlagzeile.
Wahlkreisanalyse
Konstituentenbasierte Grammatiken werden verwendet, um die Bestandteile eines Satzes zu analysieren und zu bestimmen. Diese Grammatiken können verwendet werden, um die interne Struktur von Sätzen in Bezug auf eine hierarchisch geordnete Struktur ihrer Bestandteile zu modellieren oder darzustellen. Jedes Wort gehört normalerweise zu einer bestimmten lexikalischen Kategorie im Fall und bildet das Kopfwort verschiedener Phrasen. Diese Phrasen werden basierend auf Regeln gebildet, die als Phrasenstrukturregeln bezeichnet werden.Phrasenstrukturregeln bilden den Kern von Wahlkreisgrammatiken, weil sie über Syntax und Regeln sprechen, die die Hierarchie und Reihenfolge der verschiedenen Bestandteile in den Sätzen regeln. Diese Regeln richten sich in erster Linie an zwei Dinge.
- Sie bestimmen, welche Wörter verwendet werden, um die Phrasen oder Bestandteile zu konstruieren.
- Sie bestimmen, wie wir diese Bestandteile zusammen ordnen müssen.
Die generische Darstellung einer Phrasenstrukturregel ist S → AB , was zeigt, dass die Struktur S aus den Bestandteilen A und B besteht und die Reihenfolge A gefolgt von B ist . Während es mehrere Regeln gibt (siehe Kapitel 1, Seite 19: Textanalyse mit Python, wenn Sie tiefer eintauchen möchten), beschreibt die wichtigste Regel, wie man einen Satz oder eine Klausel teilt. Die Phrasenstrukturregel bezeichnet eine binäre Division für einen Satz oder eine Klausel als S → NP VP wobei S der Satz oder die Klausel ist, und es wird in das Subjekt unterteilt, bezeichnet durch die Nominalphrase (NP) und das Prädikat, bezeichnet durch die Verbphrase (VP).
Ein Wahlkreis-Parser kann auf der Grundlage solcher Grammatiken / Regeln erstellt werden, die normalerweise gemeinsam als kontextfreie Grammatik (CFG) oder phrasenstrukturierte Grammatik verfügbar sind. Der Parser verarbeitet Eingabesätze gemäß diesen Regeln und hilft beim Erstellen eines Analysebaums.
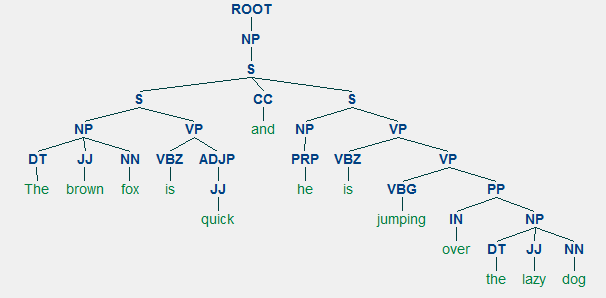
Ein Beispiel für die Analyse von Wahlkreisen mit einer verschachtelten hierarchischen Struktur
Wir werden nltk und die StanfordParser hier, um Analysebäume zu generieren.
Voraussetzungen: Laden Sie den offiziellen Stanford-Parser von hier herunter, der recht gut zu funktionieren scheint. Sie können eine spätere Version ausprobieren, indem Sie auf diese Website gehen und den Abschnitt Release History überprüfen. Entpacken Sie es nach dem Herunterladen an einen bekannten Speicherort in Ihrem Dateisystem. Sobald Sie fertig sind, können Sie jetzt den Parser von
nltk, den wir bald untersuchen werden.
Der Stanford-Parser verwendet im Allgemeinen einen PCFG-Parser (probabilistic context-free grammar). Eine PCFG ist eine kontextfreie Grammatik, die jeder ihrer Produktionsregeln eine Wahrscheinlichkeit zuordnet. Die Wahrscheinlichkeit eines aus einer PCFG generierten Analysebaums ist einfach die Produktion der individuellen Wahrscheinlichkeiten der Produktionen, die verwendet werden, um sie zu erzeugen.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Wir können den Wahlkreis-Analysebaum für unsere Schlagzeile sehen. Lassen Sie es uns visualisieren, um die Struktur besser zu verstehen.
from IPython.display import displaydisplay(result)
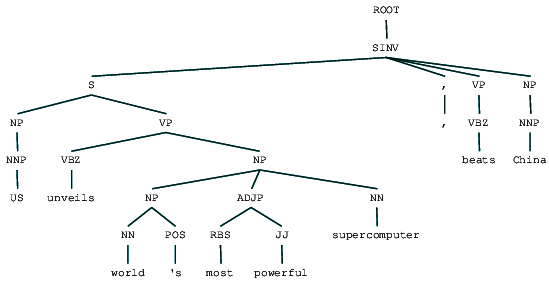
Wahlkreis analysiert Schlagzeilen
Wir können die verschachtelte hierarchische Struktur der Komponenten in der vorherigen Ausgabe im Vergleich zur flachen Struktur im flachen Parsen sehen. Falls Sie sich fragen, was SINV bedeutet, stellt es einen umgekehrten deklarativen Satz dar, d. H. Einen, in dem das Subjekt dem angespannten Verb oder Modal folgt. Beziehen Sie sich bei Bedarf auf die Penn Treebank-Referenz, um andere Tags nachzuschlagen.
Dependency Parsing
Beim Dependency Parsing versuchen wir, abhängigkeitsbasierte Grammatiken zu verwenden, um sowohl strukturelle als auch semantische Abhängigkeiten und Beziehungen zwischen Token in einem Satz zu analysieren und abzuleiten. Das Grundprinzip einer Abhängigkeitsgrammatik ist, dass in jedem Satz in der Sprache alle Wörter außer einem eine Beziehung oder Abhängigkeit von anderen Wörtern im Satz haben. Das Wort, das keine Abhängigkeit hat, wird die Wurzel des Satzes genannt. Das Verb wird in den meisten Fällen als Wurzel des Satzes verwendet. Alle anderen Wörter sind direkt oder indirekt mit dem Wurzelverb verknüpft, indem Links verwendet werden, die die Abhängigkeiten darstellen.
In Anbetracht unseres Satzes „Der braune Fuchs ist schnell und er springt über den faulen Hund“, wenn wir den Abhängigkeitssyntaxbaum dafür zeichnen wollten, hätten wir die Struktur
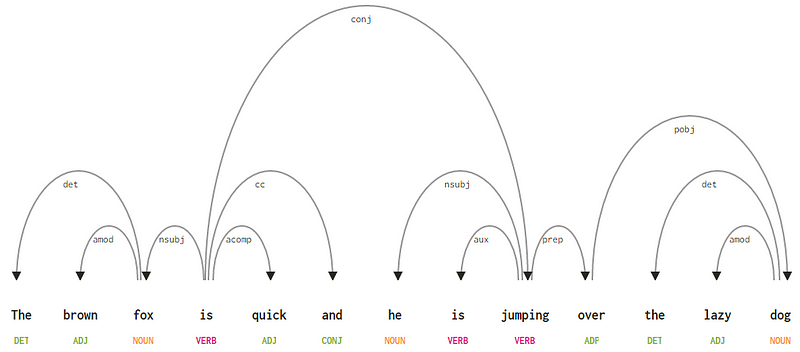
Ein Abhängigkeitsanalysebaum für einen Satz
Diese Abhängigkeitsbeziehungen haben jeweils einen haben ihre eigene Bedeutung und sind Teil einer Liste universeller Abhängigkeitstypen. Dies wird in einem Originalartikel, Universal Stanford Dependencies: A Cross-Linguistic Typology von de Marneffe et al., 2014, diskutiert. Die vollständige Liste der Abhängigkeitstypen und ihre Bedeutung finden Sie hier .
Wenn wir einige dieser Abhängigkeiten beobachten, ist es nicht allzu schwer, sie zu verstehen.
- Das Abhängigkeits-Tag det ist ziemlich intuitiv – es bezeichnet die Determiner-Beziehung zwischen einem nominalen Kopf und dem Determiner. Normalerweise hat das Wort mit POS-Tag DET auch die Det-Abhängigkeits-Tag-Beziehung. Beispiele sind
fox → theunddog → the. - Das Abhängigkeitstag amod steht für adjectival modifier und steht für jedes Adjektiv, das die Bedeutung eines Substantivs ändert. Beispiele sind
fox → brownunddog → lazy. - Das Abhängigkeits-Tag nsubj steht für eine Entität, die als Subjekt oder Agent in einer Klausel fungiert. Beispiele sind
is → foxundjumping → he. - Die Abhängigkeiten cc und conj haben mehr mit Verknüpfungen zu tun, die sich auf Wörter beziehen, die durch koordinierende Konjunktionen verbunden sind . Beispiele sind
is → andundis → jumping. - Das Abhängigkeits-Tag aux gibt das Hilfs- oder Sekundärverb in der Klausel an. Beispiel:
jumping → is. - Das Abhängigkeitstag acomp steht für Adjektivkomplement und fungiert als Komplement oder Objekt zu einem Verb im Satz. Beispiel:
is → quick - Das Abhängigkeitstag prep bezeichnet einen Präpositionsmodifikator, der normalerweise die Bedeutung eines Substantivs, Verbs, Adjektivs oder einer Präposition ändert. Normalerweise wird diese Darstellung für Präpositionen verwendet, die eine Substantiv- oder Nominalphrasenergänzung haben. Beispiel:
jumping → over. - Das Abhängigkeitstag pobj wird verwendet, um das Objekt einer Präposition zu bezeichnen . Dies ist normalerweise der Kopf einer Nominalphrase nach einer Präposition im Satz. Beispiel:
over → dog.
Spacy hatte zwei Arten von englischen Abhängigkeitsparsern, basierend darauf, welche Sprachmodelle Sie verwenden. Basierend auf Sprachmodellen können Sie das universelle Abhängigkeitsschema oder das CLEAR Style-Abhängigkeitsschema verwenden, das jetzt auch in NLP4J verfügbar ist. Wir werden jetzt spacy und die Abhängigkeiten für jedes Token in unserer Überschrift ausdrucken.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
Es ist offensichtlich, dass das Verb beats die WURZEL ist, da es im Vergleich zu den anderen Token keine anderen Abhängigkeiten hat. Um mehr über jede Anmerkung zu erfahren, können Sie immer auf das KLARE Abhängigkeitsschema verweisen. Wir können die obigen Abhängigkeiten auch besser visualisieren.
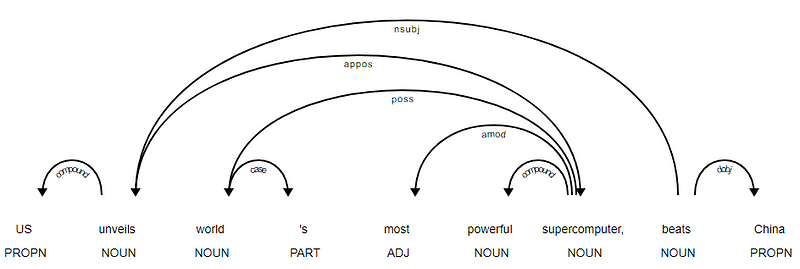
News Headline Abhängigkeitsbaum von SpaCy
Sie können auch nltk und die StanfordDependencyParser um den Abhängigkeitsbaum zu visualisieren und aufzubauen. Wir präsentieren den Abhängigkeitsbaum sowohl in seiner rohen als auch in kommentierter Form wie folgt.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
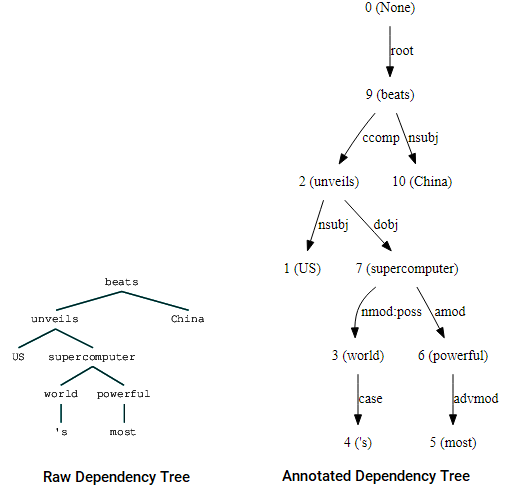
Visualisierung von Abhängigkeitsbäumen mit dem Stanford Dependency Parser von nltk
Sie können die Ähnlichkeiten mit dem Baum feststellen, den wir zuvor erhalten hatten. Die Anmerkungen helfen beim Verständnis der Art der Abhängigkeit zwischen den verschiedenen Token.
Bio: Dipanjan Sarkar ist ein Data Scientist @Intel, ein Autor, ein Mentor @Springboard, ein Schriftsteller und ein Sport- und Sitcom-Süchtiger.
Original. Reposted mit Erlaubnis.
Verwandt:
- Robuste Word2Vec-Modelle mit Gensim & Anwenden von Word2Vec-Funktionen für Aufgaben des maschinellen Lernens
- Menschlich interpretierbares maschinelles Lernen (Teil 1) – Die Notwendigkeit und Bedeutung der Modellinterpretation
- Implementierung von Deep-Learning-Methoden und Feature-Engineering für Textdaten: Das Skip-Gram-Modell