KDnuggets
for ethvert sprog går syntaks og struktur normalt hånd i hånd, hvor et sæt specifikke regler, konventioner og principper styrer, hvordan ord kombineres i sætninger; sætninger kombineres i klausuler; og klausuler kombineres i sætninger. Vi vil tale specifikt om den engelske sprog syntaks og struktur i dette afsnit. På engelsk kombineres ord normalt sammen for at danne andre bestanddele. Disse bestanddele omfatter ord, sætninger, klausuler og sætninger. I betragtning af en sætning, “den brune ræv er hurtig, og han hopper over den dovne hund”, den er lavet af en masse ord, og bare at se på ordene i sig selv fortæller os ikke meget.

En flok uordnede ord formidler ikke meget information
viden om sprogets struktur og syntaks er nyttig på mange områder som tekstbehandling, annotation og parsing til yderligere operationer såsom tekstklassificering eller opsummering. Typiske parsningsteknikker til forståelse af tekstsyntaks er nævnt nedenfor.
- dele af tale (POS) Tagging
- lavvandede Parsing eller Chunking
- valgkreds Parsing
- afhængighed Parsing
Vi vil se på alle disse teknikker i efterfølgende afsnit. I betragtning af vores tidligere eksempel sætning “den brune ræv er hurtig, og han hopper over den dovne hund”, hvis vi skulle kommentere den ved hjælp af grundlæggende POS-tags, ville det se ud som følgende figur.

POS tagging for en sætning
således følger en sætning typisk en hierarkisk struktur bestående af følgende komponenter,
sætningsklausuler-sætninger-sætninger-ord
tagging dele af tale
dele af tale (POS) er specifikke leksikale kategorier, som ord er tildelt, baseret på deres syntaktiske kontekst og rolle. Normalt kan Ord falde ind i en af følgende hovedkategorier.
- N(oun): Dette betegner normalt ord, der skildrer et objekt eller en enhed, som kan være levende eller ikke-levende. Nogle eksempler ville være ræv , hund , bog og så videre. POS-tagsymbolet for navneord er N.
- V(erb): verb er ord, der bruges til at beskrive bestemte handlinger, tilstande eller hændelser. Der er en bred vifte af yderligere underkategorier, såsom hjælpe -, refleksive og transitive verb (og mange flere). Nogle typiske eksempler på verb ville løbe , hoppe , læse og skrive . POS-tagsymbolet for verb er V.
- Adj (ective): Adjektiver er ord, der bruges til at beskrive eller kvalificere andre ord, typisk navneord og navneordssætninger. Udtrykket smuk blomst har substantivet (N) blomst som er beskrevet eller kvalificeret ved hjælp af adjektivet (ADJ) smuk . POS-tagsymbolet for adjektiver er ADJ .
- Adv(Erb): adverb fungerer normalt som modifikatorer for andre ord, herunder navneord, adjektiver, verb eller andre adverb. Udtrykket meget smuk blomst har adverbet (ADV) meget , som ændrer adjektivet (ADJ) smukt , hvilket angiver, i hvilken grad blomsten er smuk. POS-tagsymbolet for adverb er ADV.
udover disse fire hovedkategorier af taledele er der andre kategorier , der ofte forekommer på engelsk. Disse omfatter pronomen, præpositioner, interjektioner, konjunktioner, determinere og mange andre. Desuden kan hvert POS-tag som substantivet (N) yderligere opdeles i kategorier som ental substantiver (NN), ental egennavne(NNP) og flertal substantiver (NNS).
processen med klassificering og mærkning af POS-tags for ord kaldet dele af tale-tagging eller POS-tagging . POS-tags bruges til at kommentere ord og skildre deres POS, hvilket er virkelig nyttigt at udføre specifik analyse, såsom at indsnævre substantiver og se, hvilke der er de mest fremtrædende, ordforståelse disambiguation og grammatikanalyse. Vi vil udnytte både nltkog spacy som normalt bruger Penn Treebank notation til POS tagging.
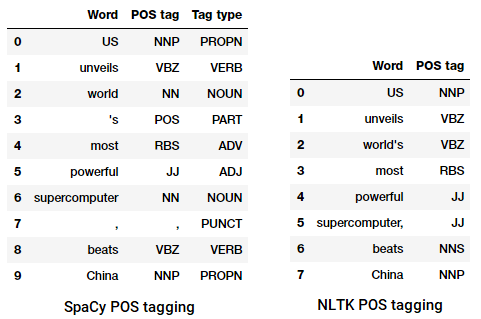
POS tagging en nyhedsoverskrift
Vi kan se, at hvert af disse biblioteker behandler tokens på deres egen måde og tildeler specifikke tags til dem. Baseret på hvad vi ser, synes spacy at gøre lidt bedre end nltk.
lav Parsing eller Chunking
baseret på det hierarki, vi skildrede tidligere, udgør grupper af ord sætninger. Der er fem hovedkategorier af sætninger:
- Noun phrase (NP): Dette er sætninger, hvor et substantiv fungerer som hovedordet. Noun sætninger fungerer som et emne eller objekt til et verbum.
- Verb sætning (VP): disse sætninger er leksikalske enheder, der har et verb, der fungerer som hovedordet. Normalt er der to former for verb sætninger. En form har verbkomponenterne såvel som andre enheder såsom navneord, adjektiver eller adverb som dele af objektet.
- adjektiv sætning (ADJP): disse er sætninger med et adjektiv som hovedordet. Deres vigtigste rolle er at beskrive eller kvalificere substantiver og pronomen i en sætning, og de vil enten blive placeret før eller efter substantivet eller pronomen.
- Adverb sætning (ADVP): disse sætninger fungerer som adverb, da adverbet fungerer som hovedordet i sætningen. Adverb sætninger bruges som modifikatorer for navneord, verb eller adverb selv ved at give yderligere detaljer, der beskriver eller kvalificerer dem.
- præpositional sætning (PP): disse sætninger indeholder normalt en præposition som hovedordet og andre leksikale komponenter som navneord, pronomen osv. Disse fungerer som et adjektiv eller adverb, der beskriver andre ord eller sætninger.overfladisk parsing, også kendt som let parsing eller chunking, er en populær naturlig sprogbehandlingsteknik til analyse af strukturen i en sætning for at opdele den i dens mindste bestanddele (som er tokens som ord) og gruppere dem sammen i sætninger på højere niveau. Dette inkluderer POS-tags samt sætninger fra en sætning.
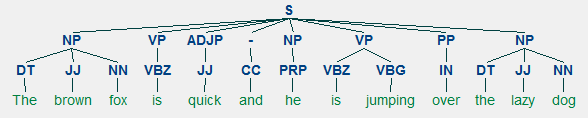
et eksempel på lavvandede parsing skildrer højere niveau sætning anmærkningerVi vil udnytte
conll2000corpus til træning vores lavvandede parser model. Dette corpus er tilgængeligt inltkmed chunk-kommentarer, og vi bruger omkring 10k-poster til træning af vores model. En prøve kommenteret sætning er afbildet som følger.10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
fra det foregående output kan du se, at vores datapunkter er sætninger, der allerede er kommenteret med sætninger og POS-tags metadata, der vil være nyttige til træning af vores lavvandede parsermodel. Vi vil udnytte to chunking utility funktioner, tree2conlltags , for at få tredobler af ord, tag og chunk tags for hver token, og conlltags2tree at generere en parse træ fra disse token tredobler. Vi bruger disse funktioner til at træne vores parser. En prøve er afbildet nedenfor.
chunk-tags bruger IOB-formatet. Denne notation repræsenterer indenfor, udenfor og begyndelsen. B-præfikset før et tag angiver, at det er begyndelsen på en del, og I – præfiks angiver, at det er inde i en del. O-mærket angiver, at token ikke tilhører nogen del. B-tagget bruges altid, når der er efterfølgende tags af samme type, der følger det uden tilstedeværelse af O-tags mellem dem.
Vi vil nu definere en funktion
conll_tag_ chunks()for at udtrække POS og chunk tags fra sætninger med chunked annotationer og en funktion kaldetcombined_taggers()for at træne flere taggers med backoff taggers (f.eks. unigram og bigram taggers)Vi vil nu definere en klasse
NGramTagChunkerdet vil tage taggede sætninger som træningsinput, få deres (ord, POS-tag, chunk-tag) tripler og træne enBigramTaggermed enUnigramTaggersom backoff-tagger. Vi vil også definere enparse()funktion til at udføre overfladisk parsing på nye sætningerUnigramTaggerBigramTaggerogTrigramTaggerer klasser, der arver fra basisklassenNGramTagger, som selv arver fraContextTaggerklasse, som arver fraSequentialBackoffTaggerklasse.Vi vil bruge denne klasse til at træne på
conll2000chunkedtrain_dataog evaluere modelydelsen påtest_dataChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
vores chunking-model får en nøjagtighed på omkring 90%, hvilket er ganske godt! Lad os nu udnytte denne model til lavvandede parse og luns vores prøve nyhedsartikel overskrift, som vi brugte tidligere, “USA afslører verdens mest magtfulde supercomputer, beats Kina”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
således kan du se, at det har identificeret to navneordssætninger (NP) og en verbssætning (VP) i nyhedsartiklen. Hvert ords POS-tags er også synlige. Vi kan også visualisere dette i form af et træ som følger. Du skal muligvis installere ghostscript, hvis
nltkkaster en fejl.

overfladisk parset nyhedsoverskriftdet foregående output giver en god følelse af struktur efter overfladisk parsing af nyhedsoverskriften.
valgkreds Parsing
konstituerende baserede grammatikker bruges til at analysere og bestemme bestanddelene i en sætning. Disse grammatikker kan bruges til at modellere eller repræsentere den interne struktur af sætninger i form af en hierarkisk ordnet struktur af deres bestanddele. Hvert eneste ord hører normalt til en bestemt leksikalsk kategori i sagen og danner hovedordet med forskellige sætninger. Disse sætninger er dannet baseret på regler kaldet sætningsstrukturregler.
Sætningsstrukturregler udgør kernen i valgkredsgrammer, fordi de taler om syntaks og regler, der styrer hierarkiet og rækkefølgen af de forskellige bestanddele i sætningerne. Disse regler henvender sig primært til to ting.
- de bestemmer, hvilke ord der bruges til at konstruere sætninger eller bestanddele.
- de bestemmer, hvordan vi skal bestille disse bestanddele sammen.
den generiske repræsentation af en sætningsstrukturregel er S kurs AB , som viser , at strukturen S består af bestanddele A og B, og rækkefølgen er A efterfulgt af B . Mens der er flere regler (se Kapitel 1, Side 19: tekstanalyse med Python, hvis du vil dykke dybere), beskriver den vigtigste regel, hvordan man deler en sætning eller en klausul. Sætningsstrukturreglen betegner en binær opdeling for en sætning eller en klausul som S-NP VP, hvor S er sætningen eller klausulen, og den er opdelt i emnet, betegnet med substantivsætningen (NP) og prædikatet, betegnet med verbsætningen (VP).
en valgkredsparser kan bygges baseret på sådanne grammatikker / regler, som normalt er samlet tilgængelige som kontekstfri grammatik (CFG) eller sætningsstruktureret grammatik. Parseren behandler inputsætninger i henhold til disse regler og hjælper med at opbygge et parse-træ.
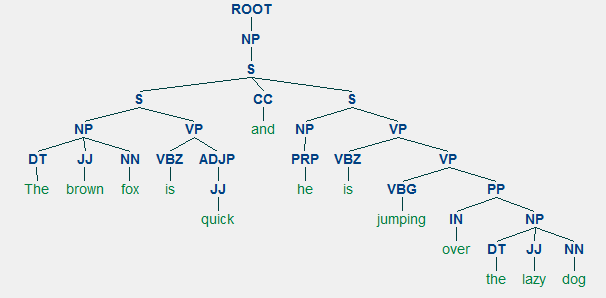
et eksempel på valgkreds parsing, der viser en indlejret hierarkisk strukturVi vil bruge
nltkogStanfordParserher for at generere parse træer.forudsætninger: Hent den officielle Stanford-Parser herfra, som synes at fungere ganske godt. Du kan prøve en senere version ved at gå til denne hjemmeside og kontrollere afsnittet Release History. Når du har hentet det, skal du pakke det ud til et kendt sted i dit filsystem. Når du er færdig, er du nu klar til at bruge parseren fra
nltk, som vi snart vil udforske.Stanford-parseren bruger generelt en pcfg (probabilistisk kontekstfri grammatik) parser. En PCFG er en kontekstfri grammatik, der forbinder en sandsynlighed med hver af dens produktionsregler. Sandsynligheden for et parse-træ genereret fra en PCFG er simpelthen produktionen af de individuelle sandsynligheder for de produktioner, der bruges til at generere det.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Vi kan se valgkredsens parse træ for vores nyhedsoverskrift. Lad os visualisere det for at forstå strukturen bedre.
from IPython.display import displaydisplay(result)
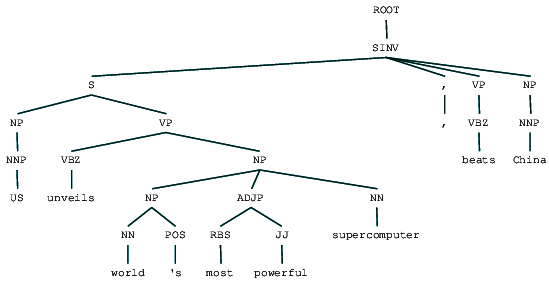
valgkreds parset nyhedsoverskriftVi kan se den indlejrede hierarkiske struktur af bestanddelene i det foregående output sammenlignet med den flade struktur i lav parsing. Hvis du undrer dig over, hvad SINV betyder, repræsenterer det en omvendt deklarativ sætning, dvs.en, hvor emnet følger det spændte verb eller modal. Se Penn Treebank-referencen efter behov for at slå andre tags op.
Dependency Parsing
i dependency parsing forsøger vi at bruge afhængighedsbaserede grammatikker til at analysere og udlede både struktur og semantiske afhængigheder og forhold mellem tokens i en sætning. Det grundlæggende princip bag en afhængighedsgrammatik er, at i enhver sætning på sproget, alle ord undtagen en, har noget forhold eller afhængighed af andre ord i sætningen. Ordet, der ikke har nogen afhængighed, kaldes roden til sætningen. Verbet er taget som roden af sætningen i de fleste tilfælde. Alle de andre ord er direkte eller indirekte knyttet til rodverbet ved hjælp af links, som er afhængighederne.
i betragtning af vores sætning “den brune ræv er hurtig, og han hopper over den dovne hund”, hvis vi ønskede at tegne afhængighedssyntakstræet for dette, ville vi have strukturen
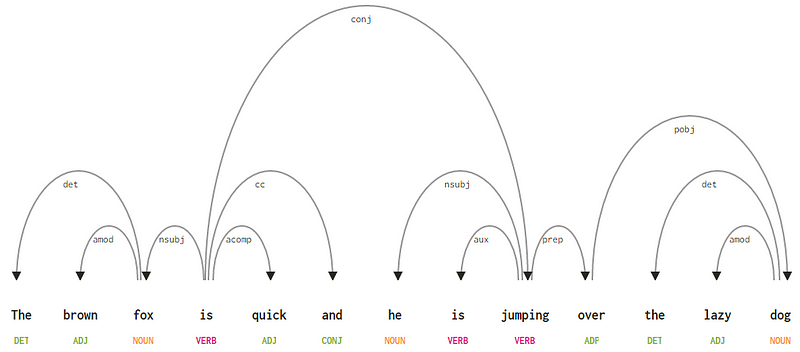
et afhængighedsparse træ for en sætningdisse afhængighedsforhold har hver deres betydning og er en del af en liste over universelle afhængighedstyper. Dette diskuteres i et originalt papir, Universal Stanford Dependencies: en Tværsproglig typologi af de Marneffe et al., 2014). Du kan tjekke den udtømmende liste over afhængighedstyper og deres betydning her.
Hvis vi observerer nogle af disse afhængigheder, er det ikke for svært at forstå dem.
- afhængighedstagget det er ret intuitivt — det betegner determiner-forholdet mellem et nominelt hoved og determiner. Normalt vil ordet med POS-tag DET også have det afhængighed tag relation. Eksempler inkluderer
fox → theogdog → the.afhængighedstagget amod står for adjektivmodifikator og står for ethvert adjektiv, der ændrer betydningen af et substantiv. Eksempler inkludererfox → brownogdog → lazy. - afhængighedstagget nsubj står for en enhed, der fungerer som et emne eller agent i en klausul. Eksempler inkluderer
is → foxogjumping → he. - afhængighederne cc og conj har mere at gøre med forbindelser relateret til ord forbundet ved at koordinere konjunktioner . Eksempler inkluderer
is → andogis → jumping. - afhængighedstaggen angiver det ekstra eller sekundære verb i klausulen. Eksempel:
jumping → is.afhængighedstagget acomp står for adjektivkomplement og fungerer som komplementet eller objektet til et verbum i sætningen. Eksempel:is → quick - afhængighedstaggen prep betegner en præpositionsmodifikator, som normalt ændrer betydningen af et substantiv, verb, adjektiv eller præposition. Normalt bruges denne repræsentation til præpositioner, der har et substantiv eller substantiv sætningskomplement. Eksempel:
jumping → over. - afhængighedstagget pobj bruges til at betegne genstanden for en præposition . Dette er normalt hovedet på en navneordssætning efter en præposition i sætningen. Eksempel:
over → dog.
Spacy havde to typer engelske afhængighedsparsere baseret på hvilke sprogmodeller du bruger, du kan finde flere detaljer her. Baseret på sprogmodeller kan du bruge ordningen Universal Dependencies eller ordningen CLEAR Style Dependency, der også er tilgængelig i nlp4j nu. Vi vil nu udnytte
spacyog udskrive afhængighederne for hvert token i vores nyhedsoverskrift.<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
det er tydeligt, at verbet slår er roden, da det ikke har andre afhængigheder i forhold til de andre tokens. For at vide mere om hver annotation kan du altid henvise til den klare afhængighedsordning. Vi kan også visualisere ovenstående afhængigheder på en bedre måde.
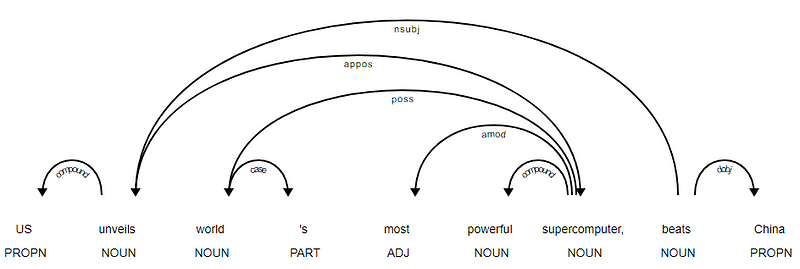
nyhedsoverskrift afhængighedstræ fra SpaCyDu kan også udnytte
nltkogStanfordDependencyParserfor at visualisere og udbygge afhængighedstræet. Vi viser afhængighedstræet både i sin rå og kommenterede form som følger.(beats (unveils US (supercomputer (world 's) (powerful most))) China)
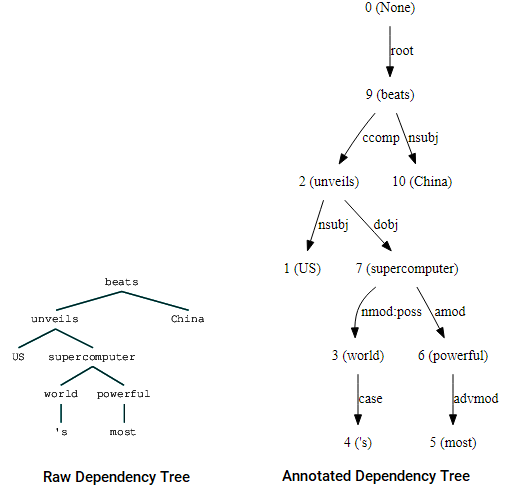
Afhængighedstræ visualiseringer ved hjælp af Nltks Stanford dependency parserDu kan bemærke lighederne med det træ, vi havde opnået tidligere. Annotationerne hjælper med at forstå typen af afhængighed blandt de forskellige tokens.
Bio: Dipanjan Sarkar er en dataforsker @Intel, en forfatter, en mentor @Springboard, en forfatter og en sports-og sitcommisbruger.
Original. Reposted med tilladelse.
relateret:
- robuste Ord2vec-modeller med Gensim & anvendelse af Ord2vec-funktioner til maskinindlæringsopgaver
- Human Interpretable Machine Learning (Del 1) – behovet og betydningen af Modelfortolkning
- implementering af dybe læringsmetoder og Funktionsteknik til tekstdata: Skip-gram-modellen