KDnuggets
Pro jakýkoli jazyk, syntaxe a struktury, obvykle jdou ruku v ruce, kde se o soubor konkrétních pravidel, konvence a zásady upravují způsob, jakým jsou slova kombinována do vět; věty se kombinuje do doložky; a doložek se kombinována do vět. V této části budeme hovořit konkrétně o syntaxi a struktuře anglického jazyka. V angličtině se slova obvykle spojují a vytvářejí další základní jednotky. Tyto složky zahrnují slova, fráze, klauzule a věty. Vzhledem větu, „brown fox je rychlé a skáče přes líného psa“, je vyrobena z pár slov, a jen při pohledu na slova, samy o sobě nám moc neřekly.

spoustu neuspořádané slova nejsou sdělit mnoho informací
Znalosti o struktuře a syntaxi jazyka je užitečné v mnoha oblastech, jako je zpracování textu, anotace, a rozebrat pro další operace, jako je text klasifikace či sumarizace. Typické techniky analýzy pro pochopení syntaxe textu jsou uvedeny níže.
- Části Řeči (POS), Tagování
- Mělké Parsování nebo Bloků
- Volebním obvodu, Analýzy
- Závislost syntaktická Analýza
Budeme se dívat na všechny tyto techniky v následujících oddílech. Vzhledem k naší předchozí příkladové větě „hnědá liška je rychlá a skáče přes líného psa“, kdybychom ji měli anotovat pomocí základních značek POS, vypadalo by to jako následující obrázek.

POS tagging pro větu
Tak, věta obvykle následuje hierarchická struktura skládající se z následujících komponent,
věta → doložky → fráze → slova,
Označování Částí Řeči
slovních druhů (POS) jsou specifické lexikální kategorie, která slova jsou přiřazena na základě jejich syntaktického kontextu a roli. Obvykle mohou slova spadat do jedné z následujících hlavních kategorií.
- N(oun): To obvykle označuje slova, která zobrazují nějaký objekt nebo entitu, která může být živá nebo neživá. Některé příklady by liška, pes, kniha, a tak dále. Symbol značky POS pro podstatná jména je n.
- V (erb): slovesa jsou slova, která se používají k popisu určitých akcí, stavů nebo událostí. Existuje celá řada dalších podkategorií, jako jsou pomocná, reflexivní a tranzitivní slovesa (a mnoho dalších). Některé typické příklady sloves by běh, skákání, číst a psát . Symbol POS tagu pro slovesa je V.
- Adj (ective): Přídavná jména jsou slova používaná k popisu nebo kvalifikaci jiných slov, obvykle podstatná jména a fráze podstatných jmen. Fráze krásná květina má podstatné jméno (N) květina, která je popsána nebo kvalifikována pomocí přídavného jména (ADJ) krásná . Symbol POS tagu pro přídavná jména je adj.
- Adv (erb): příslovce obvykle působí jako modifikátory pro jiná slova včetně podstatných jmen, přídavných jmen, sloves nebo jiných příslovců. Fráze velmi krásná květina má příslovce (ADV) velmi, což modifikuje adjektivum (ADJ) krásné, což naznačuje, do jaké míry je květina krásná. Symbol značky POS pro příslovce je ADV.
Kromě těchto čtyř hlavních kategorií částí řeči existují i jiné kategorie, které se často vyskytují v anglickém jazyce. Patří sem zájmena, předložky, citoslovce, Spojky, Determinanty a mnoho dalších. Kromě toho lze každou značku POS jako podstatné jméno (N) dále rozdělit do kategorií, jako jsou podstatná jména singulární (NN), vlastní podstatná jména singulární (NNP) a podstatná jména množného čísla (NNS).
proces klasifikace a označování značek POS pro slova nazývaná části značkování řeči nebo značkování POS . POS tagy jsou použity k anotaci slova a líčí jejich POS, což je opravdu užitečné provést specifické analýzy, jako je například zúžení dolů na podstatná jména a vidět ty, které jsou nejvýznamnější, word sense disambiguation, a gramatické analýzy. Budeme využívat jak nltk, tak spacy , které obvykle používají notaci Penn Treebank pro značení POS.
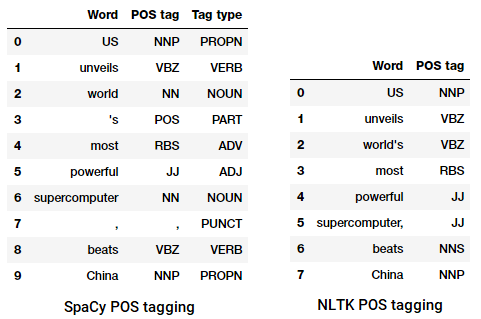
POS tagging novinový titulek
můžeme vidět, že každá z těchto knihoven léčbě žetony v jejich vlastním způsobem a přiřadit konkrétní kategorie pro ně. Na základě toho, co vidíme, se zdá, že spacy je na tom o něco lépe než nltk.
mělká analýza nebo Chunking
Na základě hierarchie, kterou jsme zobrazili dříve, tvoří skupiny slov fráze. Existuje pět hlavních kategorií frází:
- podstatná fráze (NP): Jedná se o fráze, kde podstatné jméno funguje jako hlavní slovo. Podstatné fráze působí jako předmět nebo předmět slovesa.
- slovesná fráze (VP): tyto fráze jsou lexikální jednotky, které mají sloveso působící jako hlavní slovo. Obvykle existují dvě formy slovesných frází. Jedna forma má slovesné komponenty a další entity, jako jsou podstatná jména, přídavná jména nebo příslovce jako části objektu.
- adjektivní fráze (ADJP): jedná se o fráze s přídavným jménem jako hlavním slovem. Jejich hlavní úlohou je popsat nebo kvalifikovat podstatná jména a zájmena ve větě a budou umístěna před nebo za podstatné jméno nebo zájmeno.
- příslovečná fráze (ADVP): tyto fráze fungují jako příslovce, protože příslovce funguje jako hlavní slovo ve frázi. Příslovce fráze se používají jako modifikátory pro podstatná jména, slovesa, nebo příslovce samy o sobě poskytnutím dalších podrobností, které je popisují nebo kvalifikují.
- Předložková fráze (PP): Tyto fráze obvykle obsahují předložku jako vedoucí slovo a další lexikální komponent, jako podstatná jména, zájmena, a tak dále. Ty fungují jako přídavné jméno nebo příslovce popisující jiná slova nebo fráze.
Mělké parsování, také známý jako světlo rozebrat nebo vytržení, je populární zpracování přirozeného jazyka techniku analýzy struktury věty zlomit to dolů do jeho nejmenších složek (což jsou znaky, např. slova), a skupina je dohromady do vyšší úrovně fráze. To zahrnuje POS tagy, stejně jako fráze z věty.
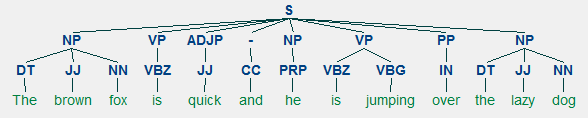
příklad mělké parsování zobrazující vyšší úrovni, fráze, popisy
Budeme využívat conll2000 corpus pro školení našich mělké parser model. Tento korpus je k dispozici v nltk s kus popisy a budeme používat kolem 10K záznamy o školení našeho modelu. Ukázková anotovaná věta je zobrazena následovně.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
Z předchozího výstupu, můžete vidět, že naše datové body jsou věty, které jsou již komentovaný s frází a POS tagy metadat, které budou užitečné v tréninku naše mělké parser model. Jsme se využít dvou bloků užitkové funkce, tree2conlltags , aby si třílůžkové slova, tag, a kus tagy pro každý token, a conlltags2tree vytvořit derivační strom z těchto token třílůžkové. Budeme používat tyto funkce trénovat náš analyzátor. Vzorek je zobrazen níže.
značky chunk používají formát IOB. Tato notace představuje uvnitř, venku a začátek. Předpona B před značkou označuje, že je to začátek bloku, a předpona I označuje, že je uvnitř bloku. Značka O označuje, že token nepatří k žádnému kusu. Značka B se používá vždy, když za ní následují následující značky stejného typu bez přítomnosti značek O mezi nimi.
nyní Budeme definovat funkci conll_tag_ chunks() extrahovat POS a kus tagy z věty s blokového popisy a funkce nazývá combined_taggers() trénovat více sprejeři s zdvojnásobení značkovače (např. unigram a bigram sprejeři)
nyní Budeme definovat třídu NGramTagChunker, který bude mít v označené věty jako vstup do odborné přípravy, získat jejich (word, POS tag, Kus tag) WTC třílůžkové, a vlak BigramTaggerUnigramTagger jako zdvojnásobení tagger. Budeme také definovat parse() funkce provádět mělké parsování na nové věty,
UnigramTaggerBigramTagger, aTrigramTaggerjsou třídy, které dědí ze základní třídyNGramTagger, která sama dědí odContextTaggertřídu, která dědí zSequentialBackoffTaggertřídy.
Budeme používat tyto třídy trénovat na conll2000 blokového train_data a vyhodnotit model výkon na test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
Naše vytržení model dostane přesnost kolem 90%, což je docela dobré! Pojďme nyní využít tento model k mělké analýze a ukrojit náš ukázkový novinový článek titulek, který jsme použili dříve ,“ USA odhalují nejvýkonnější superpočítač na světě, porazí Čínu“.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
Tak můžete vidět, že určila dvě jmenné fráze (NP) a jeden slovesné fráze (VP) ve zprávách čl. POS značky každého slova jsou také viditelné. Můžeme si to také představit ve formě stromu následujícím způsobem. Možná budete muset nainstalovat ghostscript v případě, že nltk vyvolá chybu.

Mělké analyzován novinový titulek
předchozí výstup dává dobrý smysl pro strukturu po mělké parsování zprávy titulek.
analýza volebních obvodů
gramatiky založené na složkách se používají k analýze a určení složek věty. Tyto gramatiky lze použít k modelování nebo reprezentaci vnitřní struktury vět z hlediska hierarchicky uspořádané struktury jejich složek. Každé slovo obvykle patří do konkrétní lexikální kategorie a tvoří hlavní slovo různých frází. Tyto fráze jsou tvořeny na základě pravidel nazývaných pravidla struktury frází.
pravidla struktury frází tvoří jádro gramatik volebního obvodu, protože hovoří o syntaxi a pravidlech, kterými se řídí hierarchie a uspořádání různých složek ve větách. Tato pravidla se zaměřují především na dvě věci.
- určují, jaká slova se používají ke konstrukci frází nebo složek.
- určují, jak musíme tyto složky uspořádat dohromady.
obecný zastoupení výraz struktura je pravidlo S → AB , který líčí, že struktura S se skládá ze složek a a B , a uspořádání je doplněno B . Zatímco tam je několik pravidel (viz Kapitola 1, Strana 19: Text Analytics s Python, pokud chcete ponořit se hlouběji), nejdůležitější pravidlo popisuje, jak rozdělit věty nebo klauze. Fráze struktura pravidlo označuje binární dělení na věty, nebo doložku, jako S → NP VP, kde S je věta nebo ustanovení, a to je rozděleno do předmětu, označen jmenná fráze (NP) a predikát, označený slovesné fráze (VP).
voličský parser může být postaven na základě takových gramatik/pravidel, které jsou obvykle souhrnně dostupné jako bezkontextová gramatika (CFG) nebo fráze strukturovaná gramatika. Analyzátor zpracuje vstupní věty podle těchto pravidel a pomůže při vytváření stromu analýzy.
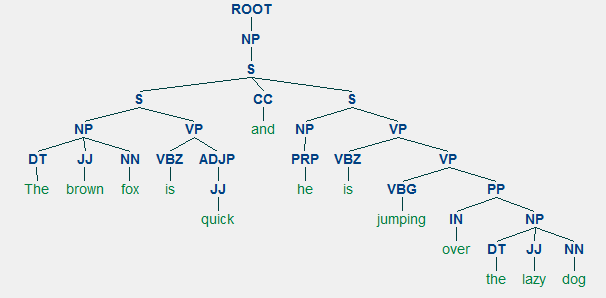
příklad volebního obvodu analýze ukazuje vnořené hierarchické struktury
Budeme používat nltkStanfordParser zde vytvořit derivační stromy.
předpoklady: Stáhněte si oficiální Stanford Parser odtud, který vypadá, že funguje docela dobře. Novější verzi si můžete vyzkoušet na tomto webu a v sekci Historie vydání. Po stažení jej rozbalte na známé místo v souborovém systému. Po dokončení jste nyní připraveni použít analyzátor z
nltk, který brzy prozkoumáme.
Stanfordův parser obecně používá parser PCFG (pravděpodobnostní bezkontextová gramatika). PCFG je bezkontextová gramatika, která spojuje Pravděpodobnost s každým z jejích výrobních pravidel. Pravděpodobnost, že derivační strom generován z PCFG je prostě výroby jednotlivých pravděpodobnosti produkce použit pro generování.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
můžeme vidět volební parse strom pro náš titulek zprávy. Pojďme si to představit, abychom lépe porozuměli struktuře.
from IPython.display import displaydisplay(result)
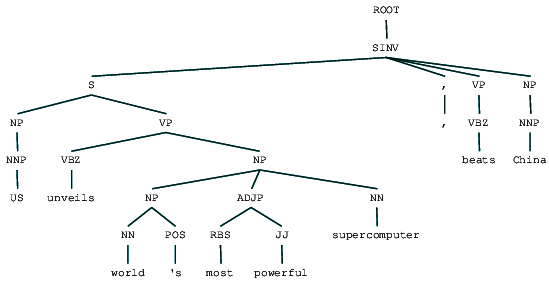
Volebním obvodu analyzován novinový titulek
Můžeme vidět vnořené hierarchické struktury složek v předchozím výstupu ve srovnání s plochou strukturu v mělké parsování. V případě, že vás zajímá, co znamená SINV, představuje obrácenou deklarativní větu, tj. ten, ve kterém předmět následuje napjaté sloveso nebo modální. Podívejte se na odkaz Penn Treebank podle potřeby pro vyhledávání dalších značek.
Závislost Analýze
V závislosti rozebrat, snažíme se využít závislost-na základě gramatiky analyzovat a odvodit, jak struktura a sémantické závislosti a vztahy mezi tokeny ve větě. Základním principem gramatiky závislosti je to, že v jakékoli větě v jazyce, všechna slova kromě jednoho, mají nějaký vztah nebo závislost na jiných slovech ve větě. Slovo, které nemá žádnou závislost, se nazývá kořen věty. Sloveso je ve většině případů považováno za kořen věty. Všechna ostatní slova jsou přímo nebo nepřímo spojena s kořenovým slovesem pomocí odkazů, což jsou závislosti.
Vzhledem k tomu, že naše věta „brown fox je rychlé a skáče přes líného psa“, pokud bychom chtěli nakreslit závislost syntaktický strom pro to, budeme mít strukturu,
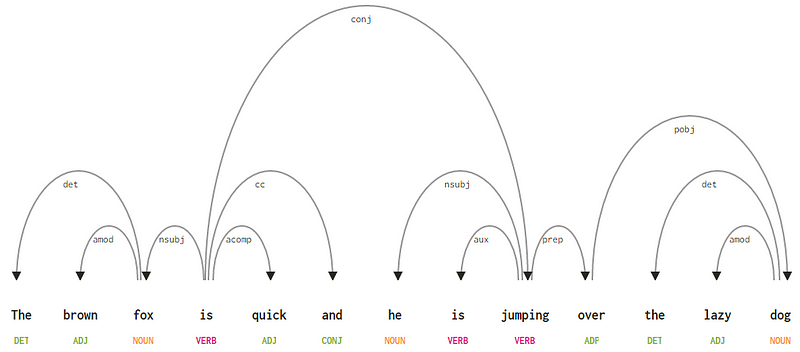
závislost derivační strom pro větu
Tyto vztahy závislosti mají každý svůj vlastní význam a jsou součástí seznamu univerzální závislost typů. Toto je diskutováno v původním článku, Universal Stanford dependences: a Cross-Linguistic Typology by de Marneffe et al, 2014). Vyčerpávající seznam typů závislostí a jejich významů si můžete prohlédnout zde.
pokud pozorujeme některé z těchto závislostí, není příliš těžké je pochopit.
- závislost tag det je velmi intuitivní — to označuje determinující vztah mezi nominální hlavou a determinant. Slovo s POS tagem det bude mít obvykle také vztah značky závislostí det. Příklady zahrnují
fox → theadog → the. - značka závislosti Amod je zkratka pro adjektivní modifikátor a znamená jakékoli přídavné jméno, které mění význam podstatného jména. Příklady zahrnují
fox → brownadog → lazy. - značka závislosti nsubj znamená entitu, která působí jako subjekt nebo agent v klauzuli. Příklady zahrnují
is → foxajumping → he. - závislosti cc a conj mají více společného s vazbami souvisejícími se slovy spojenými koordinací spojek . Příklady zahrnují
is → andais → jumping. - značka závislosti aux označuje pomocné nebo sekundární sloveso v klauzuli. Příklad:
jumping → is. - značka závislosti acomp znamená adjektivní doplněk a působí jako doplněk nebo objekt slovesa ve větě. Příklad:
is → quick - závislost tag prep označuje předložkové modifikátor, který obvykle mění význam, podstatné jméno, sloveso, přídavné jméno, nebo příslovce. Obvykle se tato reprezentace používá pro předložky, které mají podstatné jméno nebo podstatné jméno. Příklad:
jumping → over. - značka závislosti pobj se používá k označení objektu předložky . Toto je obvykle hlava podstatné fráze po předložce ve větě. Příklad:
over → dog.
Spacy měl dva typy anglických analyzátorů závislostí na tom, jaké jazykové modely používáte, více podrobností najdete zde. Na základě jazykových modelů můžete použít univerzální schéma závislostí nebo schéma závislosti CLEAR Style, které je nyní k dispozici také v NLP4J. Nyní využijeme spacy a vytiskneme závislosti pro každý token v našem nadpisu zpráv.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
je zřejmé, že sloveso beats je KOŘEN, protože to nemá žádné jiné závislosti ve srovnání s ostatními žetony. Chcete-li se dozvědět více o každé anotaci, můžete vždy odkazovat na jasné schéma závislostí. Výše uvedené závislosti můžeme také lépe vizualizovat.
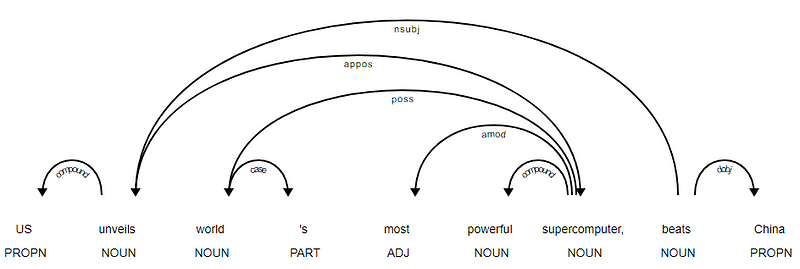
News Titulek strom závislostí z Prostorné
můžete také využít nltkStanfordDependencyParser vizualizovat a stavět se na strom závislostí. Strom závislostí předvádíme v jeho surové i komentované podobě následujícím způsobem.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
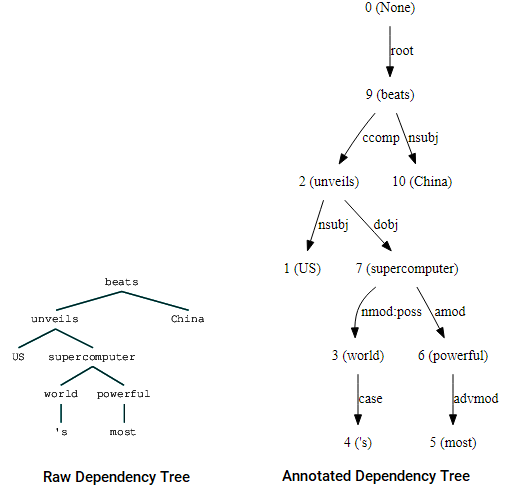
Strom Závislostí vizualizace pomocí nltk je Stanford závislost parser
Můžete si všimnout podobnosti se stromem jsme získali dříve. Anotace pomáhají pochopit typ závislosti mezi různými tokeny.
Bio: Dipanjan Sarkar je datový vědec @Intel, autor, mentor @Springboard, spisovatel a závislý na sportu a sitcomu.
originál. Přeloženo se svolením.
související:
- Robustní Word2Vec Modely s Gensim & Použití Word2Vec Funkce pro Strojové Učení Úkoly
- lidsky Interpretovatelné Strojového Učení (1. Část) — Potřeba a Význam Modelu Interpretace
- Prováděcí Hluboké Učení, Metody a Funkce Inženýrství pro Textová Data: Skip-gram Modelu