KDnuggets
Pour toute langue, la syntaxe et la structure vont généralement de pair, où un ensemble de règles, de conventions et de principes spécifiques régissent la façon dont les mots sont combinés en phrases; les phrases se combinent en clauses; et les clauses se combinent en phrases. Nous parlerons spécifiquement de la syntaxe et de la structure de la langue anglaise dans cette section. En anglais, les mots se combinent généralement pour former d’autres unités constitutives. Ces constituants comprennent des mots, des phrases, des clauses et des phrases. Considérant une phrase, « Le renard brun est rapide et il saute par-dessus le chien paresseux”, elle est faite d’un tas de mots et le simple fait de regarder les mots par eux-mêmes ne nous dit pas grand-chose.

Un tas de mots non ordonnés ne transmettent pas beaucoup d’informations
Les connaissances sur la structure et la syntaxe du langage sont utiles dans de nombreux domaines tels que le traitement de texte, l’annotation et l’analyse pour d’autres opérations telles que la classification de texte ou la synthèse. Les techniques d’analyse typiques pour comprendre la syntaxe du texte sont mentionnées ci-dessous.
- Marquage des parties du discours (POS)
- Analyse ou découpage superficiel
- Analyse de circonscription
- Analyse de dépendance
Nous examinerons toutes ces techniques dans les sections suivantes. Considérant notre exemple de phrase précédent « Le renard brun est rapide et il saute par-dessus le chien paresseux”, si nous devions l’annoter à l’aide de balises de point de vente de base, cela ressemblerait à la figure suivante.

Marquage POS pour une phrase
Ainsi, une phrase suit généralement une structure hiérarchique composée des composants suivants,
phrase → clauses → phrases →mots
Marquage des parties du discours
Les parties du discours (POS) sont des catégories lexicales spécifiques auxquelles les mots sont attribués, en fonction de leur contexte syntaxique et de leur rôle. Habituellement, les mots peuvent tomber dans l’une des principales catégories suivantes.
- N (oun): Cela désigne généralement des mots qui représentent un objet ou une entité, qui peut être vivant ou non vivant. Quelques exemples seraient le renard, le chien, le livre, etc. Le symbole de balise POS pour les noms est N.
- V (erb): Les verbes sont des mots utilisés pour décrire certaines actions, états ou occurrences. Il existe une grande variété de sous-catégories supplémentaires, telles que les verbes auxiliaires, réflexifs et transitifs (et bien d’autres). Quelques exemples typiques de verbes seraient courir, sauter, lire et écrire. Le symbole de balise POS pour les verbes est V.
- Adj(ective): Les adjectifs sont des mots utilisés pour décrire ou qualifier d’autres mots, généralement des noms et des phrases nominales. L’expression belle fleur a le nom (N) fleur qui est décrit ou qualifié en utilisant l’adjectif (ADJ) beau. Le symbole de balise POS pour les adjectifs est ADJ.
- Adv (erb): Les adverbes agissent généralement comme modificateurs pour d’autres mots, y compris les noms, les adjectifs, les verbes ou d’autres adverbes. La phrase très belle fleur a l’adverbe (ADV) très, qui modifie l’adjectif (ADJ) beau, indiquant le degré de beauté de la fleur. Le symbole de la balise POS pour les adverbes est ADV.
Outre ces quatre grandes catégories de parties du discours, il existe d’autres catégories qui se produisent fréquemment en langue anglaise. Ceux-ci comprennent les pronoms, les prépositions, les interjections, les conjonctions, les déterminants et bien d’autres. De plus, chaque balise POS comme le nom (N) peut être subdivisée en catégories comme les noms singuliers (NN), les noms propres singuliers (NNP) et les noms pluriels (NNS).
Le processus de classification et d’étiquetage des étiquettes de point de vente pour les mots appelés marquage de parties du discours ou marquage de point de vente. Les balises POS sont utilisées pour annoter les mots et représenter leur POS, ce qui est vraiment utile pour effectuer une analyse spécifique, comme le rétrécissement des noms et voir lesquels sont les plus importants, la désambiguïsation du sens des mots et l’analyse grammaticale. Nous utiliserons à la fois nltk et spacy qui utilisent généralement la notation Penn Treebank pour le marquage des points de vente.
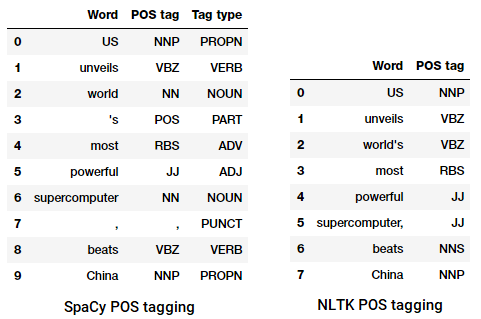
Marquage POS d’un titre d’actualité
Nous pouvons voir que chacune de ces bibliothèques traite les jetons à leur manière et leur attribue des balises spécifiques. Sur la base de ce que nous voyons, spacy semble faire légèrement mieux que nltk.
Analyse ou découpage superficiel
Sur la base de la hiérarchie que nous avons décrite précédemment, des groupes de mots constituent des phrases. Il existe cinq grandes catégories de phrases:
- Phrase nominale (NP): Ce sont des phrases où un nom agit comme mot de tête. Les phrases nominales agissent comme un sujet ou un objet à un verbe.
- Phrase verbale (VP): Ces phrases sont des unités lexicales qui ont un verbe agissant comme mot de tête. Habituellement, il existe deux formes de phrases verbales. Une forme a les composants verbaux ainsi que d’autres entités telles que des noms, des adjectifs ou des adverbes en tant que parties de l’objet.
- Phrase adjective (ADJP): Ce sont des phrases avec un adjectif comme mot principal. Leur rôle principal est de décrire ou de qualifier des noms et des pronoms dans une phrase, et ils seront placés avant ou après le nom ou le pronom.
- Adverbe (ADVP): Ces phrases agissent comme des adverbes puisque l’adverbe agit comme le mot principal de la phrase. Les phrases adverbes sont utilisées comme modificateurs pour les noms, les verbes ou les adverbes eux-mêmes en fournissant des détails supplémentaires qui les décrivent ou les qualifient.
- Phrase prépositionnelle (PP): Ces phrases contiennent généralement une préposition en tant que mot principal et d’autres composants lexicaux comme les noms, les pronoms, etc. Ceux-ci agissent comme un adjectif ou un adverbe décrivant d’autres mots ou expressions.
L’analyse superficielle, également connue sous le nom d’analyse légère ou de découpage, est une technique populaire de traitement du langage naturel consistant à analyser la structure d’une phrase pour la décomposer en ses plus petits constituants (qui sont des jetons tels que des mots) et les regrouper en phrases de niveau supérieur. Cela inclut les balises POS ainsi que les phrases d’une phrase.
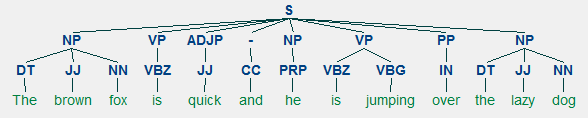
Un exemple d’analyse superficielle représentant des annotations de phrases de niveau supérieur
Nous utiliserons le corpus conll2000 pour entraîner notre modèle d’analyseur superficiel. Ce corpus est disponible en nltk avec des annotations de morceaux et nous utiliserons environ 10K enregistrements pour la formation de notre modèle. Un exemple de phrase annotée est représenté comme suit.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
À partir de la sortie précédente, vous pouvez voir que nos points de données sont des phrases déjà annotées avec des métadonnées de phrases et de balises POS qui seront utiles pour entraîner notre modèle d’analyseur superficiel. Nous allons tirer parti de deux fonctions utilitaires de fragmentation, tree2conlltags, pour obtenir des triplets de balises word, tag et chunk pour chaque jeton, et conlltags2tree pour générer un arbre d’analyse à partir de ces triplets de jetons. Nous utiliserons ces fonctions pour former notre analyseur. Un exemple est illustré ci-dessous.
Les balises de blocs utilisent le format IOB. Cette notation représente l’Intérieur, l’Extérieur et le Début. Le préfixe B avant une balise indique qu’il s’agit du début d’un bloc, et le préfixe I indique qu’il se trouve à l’intérieur d’un bloc. La balise O indique que le jeton n’appartient à aucun bloc. La balise B est toujours utilisée lorsqu’il y a des balises suivantes du même type qui la suivent sans la présence de balises O entre elles.
Nous allons maintenant définir une fonction conll_tag_ chunks() pour extraire des balises POS et en morceaux de phrases avec des annotations en morceaux et une fonction appelée combined_taggers() pour former plusieurs taggers avec des taggers backoff (par exemple, des taggers unigram et bigram)
Nous allons maintenant définir une classe NGramTagChunker qui prendra les phrases étiquetées comme entrée d’entraînement, obtiendra leurs triplets WTC (mot, balise POS, balise de morceau) et formera un BigramTagger avec un UnigramTagger comme tagueur de backoff. Nous définirons également une fonction parse() pour effectuer une analyse superficielle sur les nouvelles phrases
Le
UnigramTaggerBigramTagger, etTrigramTaggersont des classes qui héritent de la classe de baseNGramTagger, qui hérite elle-même de la classeContextTagger, qui hérite de la classeSequentialBackoffTagger.
Nous utiliserons cette classe pour nous entraîner sur le conll2000chunked train_data et évaluer les performances du modèle sur le test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
Notre modèle de découpage obtient une précision d’environ 90%, ce qui est assez bon! Exploitons maintenant ce modèle pour analyser et découper en morceaux notre exemple de titre d’article que nous avons utilisé précédemment, « Les États-Unis dévoilent le supercalculateur le plus puissant du monde, bat la Chine”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
Ainsi, vous pouvez voir qu’il a identifié deux phrases nominales (NP) et une phrase verbale (VP) dans l’article de presse. Les balises POS de chaque mot sont également visibles. Nous pouvons également visualiser cela sous la forme d’un arbre comme suit. Vous devrez peut-être installer ghostscript au cas où nltk génère une erreur.

Titre de nouvelles analysé peu profond
La sortie précédente donne un bon sens de la structure après une analyse peu profonde du titre de nouvelles.
Analyse de circonscription
Les grammaires basées sur les constituants sont utilisées pour analyser et déterminer les constituants d’une phrase. Ces grammaires peuvent être utilisées pour modéliser ou représenter la structure interne des phrases en termes de structure hiérarchisée de leurs constituants. Chaque mot appartient généralement à une catégorie lexicale spécifique dans le cas et forme le mot de tête de différentes phrases. Ces phrases sont formées sur la base de règles appelées règles de structure de phrases.
Les règles de structure de phrase forment le noyau des grammaires de circonscription, car elles parlent de syntaxe et de règles qui régissent la hiérarchie et l’ordre des différents constituants dans les phrases. Ces règles répondent principalement à deux choses.
- Ils déterminent quels mots sont utilisés pour construire les phrases ou les constituants.
- Ils déterminent comment nous devons ordonner ces constituants ensemble.
La représentation générique d’une règle de structure de phrase est S → AB, ce qui montre que la structure S est constituée des constituants A et B, et l’ordre est A suivi de B. Bien qu’il existe plusieurs règles (reportez-vous au chapitre 1, page 19: Analyse de texte avec Python, si vous souhaitez approfondir), la règle la plus importante décrit comment diviser une phrase ou une clause. La règle de structure de phrase désigne une division binaire pour une phrase ou une clause en tant que S → NP VP où S est la phrase ou la clause, et elle est divisée en le sujet, désigné par la phrase nominale (NP) et le prédicat, désigné par la phrase verbale (VP).
Un analyseur de circonscription peut être construit sur la base de telles grammaires / règles, qui sont généralement disponibles collectivement sous forme de grammaire sans contexte (CFG) ou de grammaire structurée par phrases. L’analyseur traitera les phrases d’entrée selon ces règles et aidera à construire un arbre d’analyse.
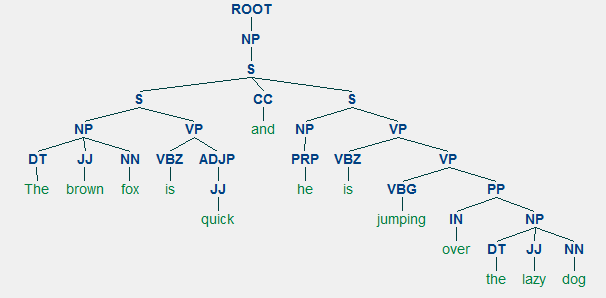
Un exemple d’analyse de circonscription montrant une structure hiérarchique imbriquée
Nous utiliserons nltk et le StanfordParser ici pour générer des arbres d’analyse.
Prérequis: Téléchargez l’analyseur officiel de Stanford à partir d’ici, ce qui semble plutôt bien fonctionner. Vous pouvez essayer une version ultérieure en vous rendant sur ce site Web et en consultant la section Historique des versions. Après le téléchargement, décompressez-le à un emplacement connu de votre système de fichiers. Une fois cela fait, vous êtes maintenant prêt à utiliser l’analyseur de
nltk, que nous explorerons bientôt.
L’analyseur de Stanford utilise généralement un analyseur PCFG (probabilistic context-free grammar). Un PCFG est une grammaire sans contexte qui associe une probabilité à chacune de ses règles de production. La probabilité d’un arbre d’analyse généré à partir d’un PCFG est simplement la production des probabilités individuelles des productions utilisées pour le générer.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Nous pouvons voir l’arbre d’analyse des circonscriptions pour notre titre de nouvelles. Visualisons-le pour mieux comprendre la structure.
from IPython.display import displaydisplay(result)
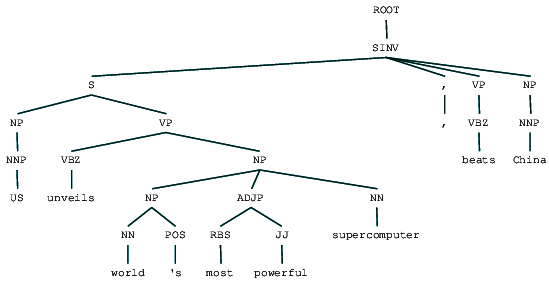
Titre des nouvelles analysées par circonscription
Nous pouvons voir la structure hiérarchique imbriquée des constituants dans la sortie précédente par rapport à la structure plate dans l’analyse superficielle. Si vous vous demandez ce que signifie SINV, il représente une phrase déclarative inversée, c’est-à-dire dans laquelle le sujet suit le verbe tendu ou le modal. Reportez-vous à la référence Penn Treebank si nécessaire pour rechercher d’autres balises.
Analyse des dépendances
Dans l’analyse des dépendances, nous essayons d’utiliser des grammaires basées sur les dépendances pour analyser et déduire à la fois les dépendances structurales et sémantiques et les relations entre les jetons dans une phrase. Le principe de base d’une grammaire de dépendance est que dans n’importe quelle phrase de la langue, tous les mots sauf un ont une relation ou une dépendance avec d’autres mots de la phrase. Le mot qui n’a pas de dépendance est appelé la racine de la phrase. Le verbe est pris comme racine de la phrase dans la plupart des cas. Tous les autres mots sont directement ou indirectement liés au verbe racine en utilisant des liens, qui sont les dépendances.
Considérant notre phrase « Le renard brun est rapide et il saute par-dessus le chien paresseux”, si nous voulions dessiner l’arbre de syntaxe des dépendances pour cela, nous aurions la structure
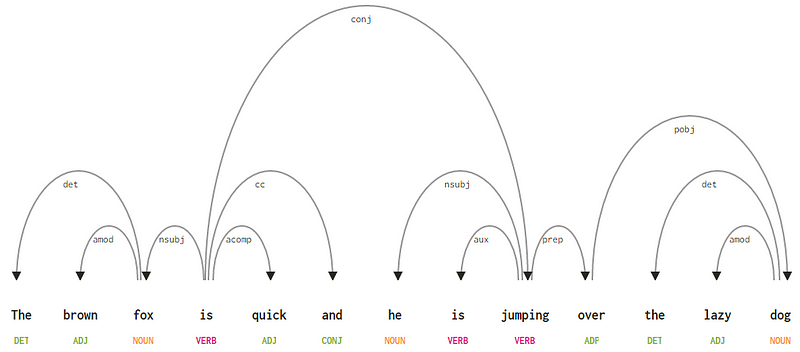
Un arbre d’analyse des dépendances pour une phrase
Ces relations de dépendance ont chacune leur propre signification et font partie d’une liste de types de dépendance universels. Ceci est discuté dans un article original, Universal Stanford Dependencies: A Cross-Linguistic Typology de de Marneffe et al, 2014). Vous pouvez consulter la liste exhaustive des types de dépendances et leurs significations ici.
Si nous observons certaines de ces dépendances, il n’est pas trop difficile de les comprendre.
- La balise de dépendance det est assez intuitive — elle dénote la relation déterminante entre une tête nominale et le déterminateur. Habituellement, le mot avec la balise POS DET aura également la relation de balise de dépendance det. Les exemples incluent
fox → theetdog → the. - La balise de dépendance amod signifie modificateur adjectival et représente tout adjectif qui modifie la signification d’un nom. Les exemples incluent
fox → brownetdog → lazy. - La balise de dépendance nsubj représente une entité qui agit en tant que sujet ou agent dans une clause. Les exemples incluent
is → foxetjumping → he. - Les dépendances cc et conj ont plus à voir avec des liens liés à des mots reliés par des conjonctions de coordination. Les exemples incluent
is → andetis → jumping. - La balise de dépendance aux indique le verbe auxiliaire ou secondaire dans la clause. Exemple :
jumping → is. - La balise de dépendance acomp signifie complément adjectif et agit comme complément ou objet d’un verbe dans la phrase. Exemple :
is → quick - La balise de dépendance prep désigne un modificateur prépositionnel, qui modifie généralement la signification d’un nom, d’un verbe, d’un adjectif ou d’une préposition. Habituellement, cette représentation est utilisée pour les prépositions ayant un complément de nom ou de phrase nominale. Exemple :
jumping → over. - La balise de dépendance pobj est utilisée pour désigner l’objet d’une préposition. Il s’agit généralement de la tête d’une phrase nominale après une préposition dans la phrase. Exemple :
over → dog.
Spacy avait deux types d’analyseurs de dépendances en anglais en fonction des modèles de langue que vous utilisez, vous pouvez trouver plus de détails ici. Sur la base des modèles de langage, vous pouvez utiliser le Schéma de dépendances Universelles ou le Schéma de dépendances de Style CLAIR également disponible dans NLP4J maintenant. Nous allons maintenant utiliser spacy et imprimer les dépendances pour chaque jeton dans notre titre de nouvelles.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
Il est évident que le verbe beats est la RACINE car il n’a pas d’autres dépendances par rapport aux autres jetons. Pour en savoir plus sur chaque annotation, vous pouvez toujours vous référer au schéma de dépendance CLAIR. Nous pouvons également visualiser les dépendances ci-dessus d’une meilleure manière.
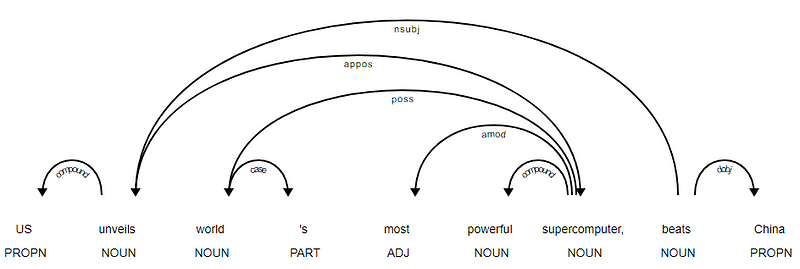
Arbre de dépendance des titres de nouvelles de SpaCy
Vous pouvez également utiliser nltk et le StanfordDependencyParser pour visualiser et construire l’arbre de dépendances. Nous présentons l’arbre de dépendances à la fois sous sa forme brute et annotée comme suit.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
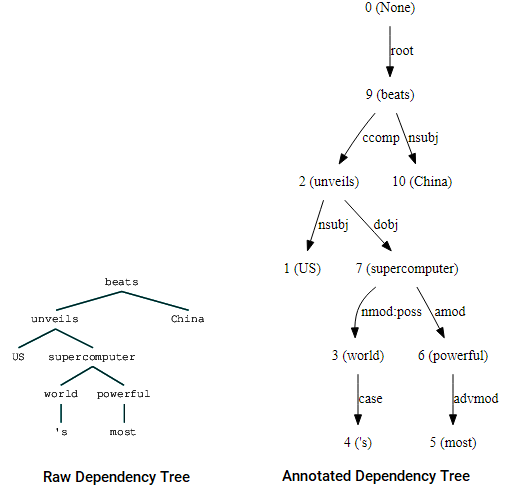
Visualisations d’arborescence de dépendances utilisant la dépendance Stanford de nltk parser
Vous pouvez remarquer les similitudes avec l’arbre que nous avions obtenu plus tôt. Les annotations aident à comprendre le type de dépendance entre les différents jetons.
Bio: Dipanjan Sarkar est un scientifique des données @Intel, un auteur, un mentor @ Springboard, un écrivain et un passionné de sports et de sitcom.
Original. Republié avec permission.
Liés:
- Modèles Word2Vec Robustes avec Gensim &Application des Fonctionnalités Word2Vec pour les Tâches d’Apprentissage Automatique
- Apprentissage Automatique Interprétable par l’Homme (Partie 1) – La Nécessité et l’Importance de l’Interprétation des Modèles
- Mise en œuvre de Méthodes d’Apprentissage Profond et d’Ingénierie des Fonctionnalités pour les Données Textuelles : Le Modèle Skip-gram