KDnuggets
bármely nyelv esetében a szintaxis és a struktúra általában kéz a kézben jár, ahol bizonyos szabályok, konvenciók és elvek szabályozzák a szavak kifejezésekké történő kombinálását; a kifejezések egyesülnek záradékokká; a záradékok pedig mondatokká válnak. Ebben a részben kifejezetten az angol nyelv szintaxisáról és szerkezetéről fogunk beszélni. Angolul a szavak általában egyesülnek, hogy más alkotó egységeket alkossanak. Ezek az összetevők szavakat, kifejezéseket, záradékokat és mondatokat tartalmaznak. Figyelembe véve egy mondatot:” a barna róka gyors, és átugrik a lusta kutyán”, ez egy csomó szóból áll, és csak a szavakat önmagában nézve nem sokat mond nekünk.

egy csomó rendezetlen szó nem közvetít sok információt
a nyelv felépítésével és szintaxisával kapcsolatos ismeretek sok területen hasznosak, mint például a szövegfeldolgozás, a jegyzetelés és az elemzés további műveletekhez, például szövegosztályozáshoz vagy összefoglaláshoz. A szöveg szintaxisának megértésére szolgáló tipikus elemzési technikákat az alábbiakban említjük.
- a beszéd részei (POS) címkézés
- sekély elemzés vagy darabolás
- választókerület elemzése
- függőségi elemzés
ezeket a technikákat a következő szakaszokban fogjuk megvizsgálni. Figyelembe véve korábbi példamondatunkat: “a barna róka gyors, és átugrik a lusta kutyán”, ha alapvető POS címkékkel kommentálnánk, akkor a következő ábrának tűnne.

egy mondat POS-címkézése
így egy mondat jellemzően hierarchikus struktúrát követ, amely a következő összetevőket tartalmazza:
mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, mondat, szavak, szavak
a beszéd egyes részeinek címkézése a beszéd egyes részei (POS) olyan lexikai kategóriák, amelyekhez a szavakat szintaktikai kontextusuk és szerepük alapján rendelik. A szavak általában a következő fő kategóriák egyikébe tartozhatnak.
- N(oun): Ez általában olyan szavakat jelöl, amelyek valamilyen tárgyat vagy entitást ábrázolnak, amely lehet élő vagy nem élő. Néhány példa lehet róka , kutya , könyv stb. A főnevek POS tag szimbóluma N.
- V (erb): az igék olyan szavak, amelyeket bizonyos műveletek, állapotok vagy események leírására használnak. Számos további alkategória létezik, mint például a kiegészítő, reflexív és tranzitív igék (és még sok más). Néhány tipikus példa az igékre a futás , ugrás , olvasás és írás . Az igék POS tag szimbóluma V.
- Adj (ective): A melléknevek olyan szavak, amelyeket más szavak leírására vagy minősítésére használnak, jellemzően főnevek és főnevek. A kifejezés gyönyörű virág van a főnév (N) virág amelyet a melléknév (ADJ) segítségével írnak le vagy minősítenek gyönyörű . A melléknevek POS tag szimbóluma ADJ .
- Adv (erb): a határozószók általában módosítóként működnek más szavaknál, beleértve a főneveket, mellékneveket, igéket vagy más határozószókat. A nagyon szép virág kifejezésnek van adverbje (ADV) Nagyon , amely módosítja a melléknevet (ADJ) szép , jelezve, hogy a virág milyen szép. Az adverbek POS tag szimbóluma az ADV.
a beszéd ezen négy fő kategóriája mellett vannak más kategóriák is , amelyek gyakran előfordulnak az angol nyelven. Ezek közé tartoznak a névmások, prepozíciók, közbeszólások, kötőszavak, Meghatározók stb. Továbbá minden POS tag, mint a főnév (N) tovább osztható olyan kategóriákra, mint egyes főnevek (NN), egyes főnevek(NNP) és többes főnevek (NNS).
a beszédrészek címkézésének vagy POS címkézésének nevezett szavak POS-címkéinek osztályozásának és Címkézésének folyamata . A POS címkéket a szavak jegyzetelésére és POS-juk ábrázolására használják, ami valóban hasznos a konkrét elemzés elvégzéséhez, például a főnevek szűkítéséhez és a legszembetűnőbb szavak megismeréséhez, a szóérzék pontosításához és a nyelvtani elemzéshez. Mind a nltk, mind a spacy, amelyek általában a Penn Treebank jelölést használják a POS címkézéshez.
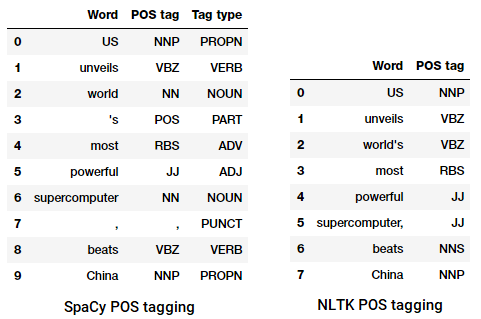
hírek címsorának címkézése
láthatjuk, hogy ezek a könyvtárak mindegyike a maga módján kezeli a tokeneket, és egyedi címkéket rendel hozzájuk. A látottak alapján úgy tűnik, hogy a spacy valamivel jobban teljesít, mint a nltk.
sekély elemzés vagy darabolás
a korábban ábrázolt hierarchia alapján a szavak csoportjai kifejezéseket alkotnak. A kifejezéseknek öt fő kategóriája van:
- főnévi kifejezés (NP): Ezek olyan kifejezések, ahol a főnév fejszóként működik. A főnévi kifejezések egy ige alanyaként vagy tárgyaként működnek.
- Verb phrase (VP): ezek a kifejezések olyan lexikai egységek, amelyek főszavaként egy ige működik. Általában az ige kifejezéseknek két formája van. Az egyik forma tartalmazza az ige komponenseit, valamint más entitásokat, például főneveket, mellékneveket vagy határozószókat az objektum részeként.
- melléknév kifejezés (ADJP): ezek olyan kifejezések, amelyeknek mellékneve a főszó. Fő szerepük a főnevek és névmások leírása vagy minősítése egy mondatban, és a főnév vagy névmás előtt vagy után kerülnek elhelyezésre.
- Adverb phrase (ADVP): ezek a kifejezések úgy viselkednek, mint a határozószók, mivel a határozószó a kifejezés főszavaként működik. A mellékmondatokat módosítóként használják főnevek, igék, vagy maguk a határozószók további részletek megadásával, amelyek leírják vagy minősítik őket.
- prepozíciós kifejezés (PP): ezek a kifejezések általában tartalmaznak egy elöljárószót, mint a főszót és más lexikai összetevőket, például főneveket, névmásokat stb. Ezek úgy viselkednek, mint egy melléknév vagy határozószó, amely más szavakat vagy kifejezéseket ír le.
sekély elemzés, más néven könnyű elemzés vagy darabolás, egy népszerű természetes nyelvi feldolgozási technika a mondat szerkezetének elemzésére, hogy a legkisebb alkotóelemeire bontsa (amelyek tokenek, például szavak), és csoportosítsa őket magasabb szintű kifejezésekbe. Ez magában foglalja a POS címkéket, valamint a mondatból származó kifejezéseket.
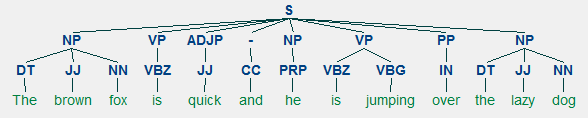
példa a sekély elemzésre, amely magasabb szintű kifejezésjegyzeteket ábrázol
a conll2000 korpuszt használjuk a sekély elemző modell képzéséhez. Ez a korpusz elérhető a nltk chunk kommentárokkal, és körülbelül 10k rekordokat fogunk használni a modellünk képzéséhez. A minta jegyzetekkel ellátott mondatot a következőképpen ábrázoljuk.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
az előző kimenetből láthatja, hogy adatpontjaink olyan mondatok, amelyek már fel vannak jegyezve kifejezésekkel és POS-címkék metaadataival, amelyek hasznosak lesznek a sekély elemző modell képzésében. Két daraboló segédprogram-funkciót, a tree2conlltags-t fogunk kihasználni , hogy minden egyes tokenhez háromszoros szót, címkét és darabcímkéket kapjunk, a conlltags2tree pedig elemzési fát generál ezekből a token hármasokból. Ezeket a funkciókat fogjuk használni az elemző képzésére. Az alábbiakban egy minta látható.
a darabcímkék az IOB formátumot használják. Ez a jelölés képviseli belül, kívül, és a kezdet. A címke előtti B-előtag azt jelzi, hogy egy darab kezdete, az I – előtag pedig azt jelzi, hogy egy darab belsejében van. Az O címke azt jelzi, hogy a token nem tartozik egyetlen darabhoz sem. A B-címkét mindig akkor használják, ha ugyanolyan típusú későbbi címkék követik, anélkül, hogy O-címkék lennének közöttük.
most definiálunk egy függvényt conll_tag_ chunks() POS és chunk tagek kivonása a tagolt kommentárokkal ellátott mondatokból és egy függvény neve combined_taggers() több Taggert kiképezni backoff taggerrel (pl. unigram és bigram taggers)
most definiálunk egy osztályt NGramTagChunker ez a címkézett mondatokat képzési bemenetként veszi fel, megkapja a (word, POS tag, chunk tag) WTC háromszorosát, és a BigramTagger a UnigramTagger mint backoff Tagger. Meg fogunk határozni egy parse() funkciót az új mondatok sekély elemzéséhez
a
UnigramTaggerBigramTaggerésTrigramTaggerolyan osztályok, amelyek az alaposztályból örökölnekNGramTagger, amely maga aContextTaggerosztály, amely aSequentialBackoffTaggerosztályból örököl.
ezt az osztályt fogjuk használni a conll2000 chunked train_data és értékelje a modell teljesítményét a test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
a daraboló modellünk pontossága körülbelül 90%, ami elég jó! Most használjuk ki ezt a modellt a sekély elemzéshez és a korábban használt hírcikk címsorának darabolásához: “az Egyesült Államok bemutatja a világ legerősebb szuperszámítógépét, a Beats China-t”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
így láthatja, hogy két főnévi kifejezést (NP) és egy igei kifejezést (VP) azonosított a hírcikkben. Minden szó POS címkéi is láthatók. Ezt egy fa formájában is megjeleníthetjük az alábbiak szerint. Előfordulhat, hogy telepítenie kell a ghostscript programot, ha a nltk hibát okoz.

sekély elemzett hírek főcím
az előző kimenet jó struktúraérzetet ad a hírek címsorának sekély elemzése után.
választókerületi elemzés
az alkotóelem alapú nyelvtanokat egy mondat összetevőinek elemzésére és meghatározására használják. Ezek a nyelvtanok felhasználhatók a mondatok belső szerkezetének modellezésére vagy ábrázolására alkotóelemeik hierarchikusan rendezett szerkezete szempontjából. Minden egyes szó általában egy adott lexikai kategóriába tartozik, és különböző kifejezések főszavát képezi. Ezeket a kifejezéseket a kifejezésszerkezeti szabályoknak nevezett szabályok alapján alakítják ki.
a Kifejezésszerkezeti szabályok alkotják a választókerületi nyelvtanok magját, mert szintaxisról és szabályokról beszélnek, amelyek a mondatok különböző alkotóelemeinek hierarchiáját és sorrendjét szabályozzák. Ezek a szabályok elsősorban két dologra vonatkoznak.
- meghatározzák, hogy milyen szavakat használnak a kifejezések vagy összetevők felépítéséhez.
- ezek határozzák meg, hogyan kell ezeket az összetevőket együtt megrendelni.
a kifejezésszerkezeti szabály általános ábrázolása s AB , amely azt ábrázolja , hogy az S szerkezet a és B összetevőkből áll, a sorrendet pedig a követi B . Bár számos szabály létezik (lásd az 1.fejezet 19. oldalát: szövegelemzés a Pythonnal, ha mélyebbre szeretne merülni), a legfontosabb szabály leírja, hogyan kell felosztani egy mondatot vagy egy záradékot. A mondatszerkezeti szabály egy mondat vagy záradék bináris felosztását jelöli s-ként, ahol S a mondat vagy záradék, és fel van osztva az alanyra, amelyet a főnévi kifejezés (NP) és a predikátum jelöl, amelyet az ige kifejezés (VP) jelöl.
választókerületi elemző építhető ilyen nyelvtanok/szabályok alapján, amelyek általában együttesen elérhetőek kontextusmentes nyelvtan (CFG) vagy kifejezésszerkezetű nyelvtan. Az elemző feldolgozza a beviteli mondatokat ezeknek a szabályoknak megfelelően, és segít egy elemzési fa felépítésében.
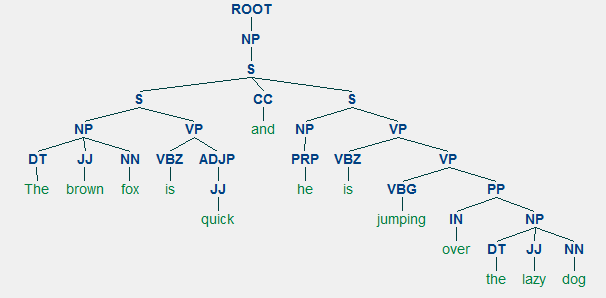
példa a választókerület elemzésére, amely beágyazott hierarchikus struktúrát mutat
a nltk és a StanfordParser itt elemzési fák létrehozásához.
előfeltételek: töltse le innen a hivatalos Stanford elemzőt, amely úgy tűnik, hogy elég jól működik. Kipróbálhat egy későbbi verziót, ha ellátogat erre a webhelyre, és ellenőrzi a kiadási előzmények részt. A letöltés után csomagolja ki a fájlrendszer ismert helyére. Ha elkészült , most már készen áll az elemző használatára a
nltk– ből, amelyet hamarosan feltárunk.
a Stanford elemző általában PCFG (probabilistic context-free grammar) elemzőt használ. A PCFG egy kontextusmentes nyelvtan, amely valószínűséget társít az egyes gyártási szabályaihoz. A pcfg-ből generált elemzési fa valószínűsége egyszerűen az előállításához használt produkciók egyedi valószínűségeinek előállítása.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
láthatjuk a választókerület elemzés fa a hír főcím. Vizualizáljuk, hogy jobban megértsük a szerkezetet.
from IPython.display import displaydisplay(result)
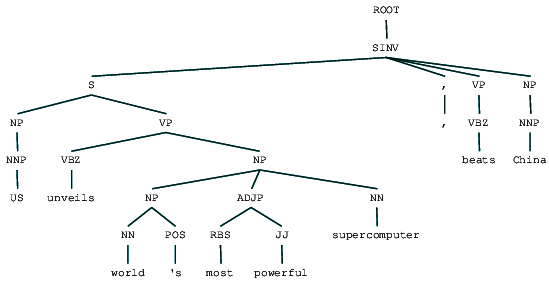
választókerület elemzett hírek főcím
láthatjuk az előző kimenet alkotóelemeinek beágyazott hierarchikus struktúráját a lapos struktúrához képest a sekély elemzésben. Abban az esetben, ha kíváncsi arra, hogy mit jelent a SINV, ez egy fordított deklaratív mondatot jelent, azaz olyat, amelyben az alany a megfeszített igét vagy modálist követi. Lásd a Penn Treebank hivatkozást, ha szükséges, hogy más címkéket keressen.
függőségi elemzés
a függőségi elemzésben függőség alapú nyelvtanokat próbálunk használni, hogy elemezzük és kikövetkeztessük mind a szerkezet, mind a szemantikai függőségeket, valamint a tokenek közötti kapcsolatokat egy mondatban. A függőségi nyelvtan alapelve az, hogy a nyelv bármely mondatában, egy kivételével minden szónak van valamilyen kapcsolata vagy függősége a mondat többi szavától. Azt a szót, amelynek nincs függősége, a mondat gyökerének nevezzük. Az ige a legtöbb esetben a mondat gyökere. Az összes többi szó közvetlenül vagy közvetve kapcsolódik a gyökér igéhez linkek segítségével, amelyek a függőségek.
figyelembe véve a mondat “a barna róka gyors, és ő ugrott át a lusta kutya”, ha akartuk felhívni a függőség szintaxis fa erre, mi lenne a szerkezet
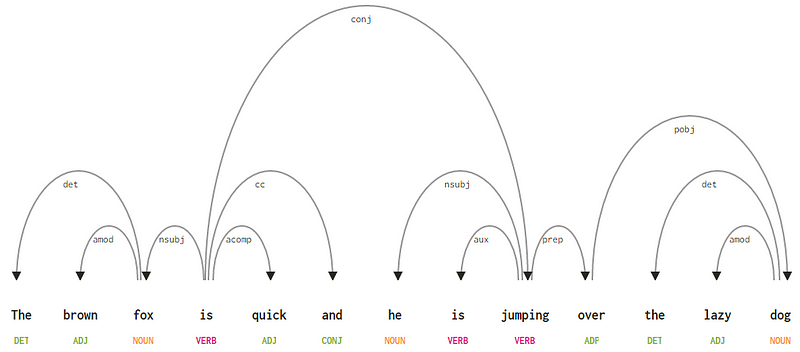
a függőség elemzés fa egy mondat
a függőség elemzés fa egy mondat
ezeknek a függőségi kapcsolatoknak mindegyiknek megvan a maga jelentése, és az egyetemes függőségi típusok listájának részét képezik. Ezt egy eredeti cikk tárgyalja, Universal Stanford Dependencies: a cross-Lingvistic Tipology by De Marneffe et al, 2014). A függőségi típusok és jelentésük teljes listáját itt tekintheti meg.
ha megfigyeljük ezeket a függőségeket, nem túl nehéz megérteni őket.
- A det függőségi címke meglehetősen intuitív — a névleges fej és a meghatározó közötti meghatározó kapcsolatot jelöli. Általában a POS tag DET-vel rendelkező szónak is lesz a Det függőségi címke kapcsolata. Ilyen például a
fox → theés adog → the. - az amod függőségi címke melléknév-módosítót jelent, és minden olyan melléknevet jelent, amely módosítja a főnév jelentését. Ilyen például a
fox → brownés adog → lazy. - az nsubj függőségi címke olyan entitást jelent, amely alanyként vagy ügynökként működik egy záradékban. Ilyen például a
is → foxés ajumping → he. - a CC és a conj függőségek inkább a kötőszók koordinálásával összekapcsolt szavakhoz kapcsolódó kapcsolatokhoz kapcsolódnak . Ilyen például a
is → andés ais → jumping. - az AUX függőségi címke a mellékmondatban a kiegészítő vagy másodlagos igét jelöli. Példa:
jumping → is. - az ACOMP függőségi címke a melléknév kiegészítését jelenti, és a mondatban szereplő ige kiegészítéseként vagy tárgyaként működik. Példa:
is → quick - a PrEP függőségi címke egy prepozíciós módosítót jelöl, amely általában módosítja a főnév, ige, melléknév vagy elöljárószó jelentését. Általában ezt az ábrázolást olyan prepozíciókra használják, amelyek főnévvel vagy főnévi kifejezéssel rendelkeznek. Példa:
jumping → over. - a pobj függőségi címke egy elöljárószó objektumának jelölésére szolgál . Ez általában egy főnévi kifejezés feje, amely a mondatban szereplő elöljárót követi. Példa:
over → dog.
Spacy kétféle angol függőségi elemzővel rendelkezett az Ön által használt nyelvi modellek alapján, további részleteket itt talál. A nyelvi modellek alapján használhatja az univerzális függőségi sémát vagy az NLP4J-ben is elérhető tiszta Stílusfüggőségi sémát. Most kihasználjuk a spacy lehetőséget, és kinyomtatjuk az egyes tokenek függőségeit a hírek címsorában.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
nyilvánvaló, hogy a veri ige a gyökér, mivel nincs más függősége a többi tokenhez képest. Ha többet szeretne tudni az egyes megjegyzésekről, mindig hivatkozhat a tiszta függőségi sémára. A fenti függőségeket jobb módon is megjeleníthetjük.
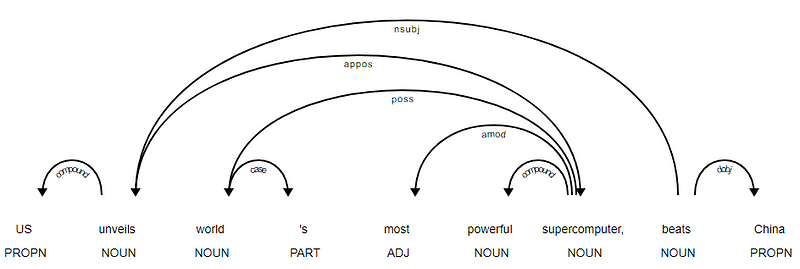
hírek Headline függőség fa SpaCy
akkor is tőkeáttétel nltk és a StanfordDependencyParser a függőségi fa megjelenítéséhez és felépítéséhez. A függőségi fát mind nyers, mind jegyzetekkel ellátott formában az alábbiak szerint mutatjuk be.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
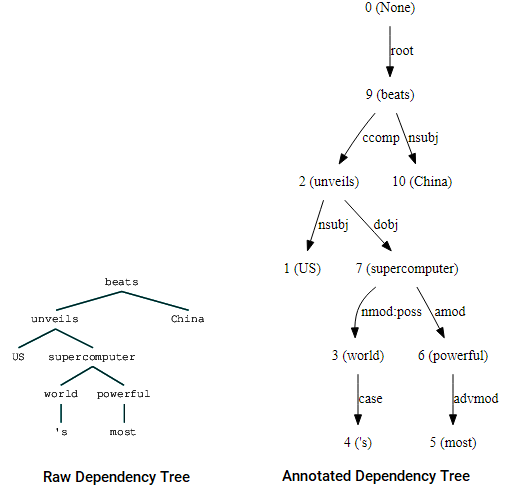
függőségi fa vizualizációk az nltk Stanford függőségével elemző
észreveheti a hasonlóságokat a korábban kapott fával. A megjegyzések segítenek megérteni a függőség típusát a különböző tokenek között.
Bio: Dipanjan Sarkar egy adat tudós @Intel, egy szerző, egy mentor @ugródeszka, egy író, és egy sport és sitcom rabja.
eredeti. Engedélyével újra közzétették.
kapcsolódó:
- robusztus Word2Vec modellek Gensim & A Word2Vec funkciók alkalmazása gépi tanulási feladatokhoz
- emberi értelmezhető Gépi tanulás (1. rész) – a Modellértelmezés szükségessége és fontossága
- a mély tanulási módszerek és a szöveges adatok tervezésének megvalósítása: a Skip-gram modell