KDnuggets
Per qualsiasi lingua, sintassi e struttura di solito vanno di pari passo, dove un insieme di regole specifiche, convenzioni e principi regolano il modo in cui le parole vengono combinate in frasi; le frasi vengono combinate in clausole; e le clausole vengono combinate in frasi. Parleremo specificamente della sintassi e della struttura della lingua inglese in questa sezione. In inglese, le parole di solito si combinano insieme per formare altre unità costituenti. Questi costituenti includono parole, frasi, clausole e frasi. Considerando una frase, “La volpe marrone è veloce e sta saltando sul cane pigro”, è fatta di un mucchio di parole e solo guardando le parole da sole non ci dicono molto.

Un mucchio di parole non ordinate non trasmettono molte informazioni
La conoscenza della struttura e della sintassi del linguaggio è utile in molte aree come l’elaborazione del testo, l’annotazione e l’analisi per ulteriori operazioni come la classificazione o la sintesi del testo. Le tecniche di analisi tipiche per la comprensione della sintassi del testo sono menzionate di seguito.
- Parts of Speech (POS) Tagging
- Shallow Parsing or Chunking
- Constituency Parsing
- Dependency Parsing
Vedremo tutte queste tecniche nelle sezioni successive. Considerando la nostra precedente frase di esempio “La volpe marrone è veloce e sta saltando sul cane pigro”, se dovessimo annotarlo usando i tag POS di base, sembrerebbe la figura seguente.

POS tagging per una frase
Così, una frase che in genere segue una struttura gerarchica composto da i seguenti componenti,
frase → clausole → frasi → parole
Tagging Parti del Discorso
Parti del discorso (POS) sono lessicale specifica categorie per cui le parole sono assegnati, sulla base del loro contesto sintattico e di ruolo. Di solito, le parole possono rientrare in una delle seguenti categorie principali.
- N(oun): Questo di solito denota parole che raffigurano qualche oggetto o entità, che può essere vivente o non vivente. Alcuni esempi potrebbero essere volpe, cane , libro e così via. Il simbolo del tag POS per i nomi è N.
- V (erb): i verbi sono parole che vengono utilizzate per descrivere determinate azioni, stati o occorrenze. Ci sono un’ampia varietà di ulteriori sottocategorie, come i verbi ausiliari, riflessivi e transitivi (e molti altri). Alcuni esempi tipici di verbi sarebbero correre , saltare , leggere e scrivere . Il simbolo del tag POS per i verbi è V.
- Adj (ective): Gli aggettivi sono parole usate per descrivere o qualificare altre parole, tipicamente nomi e frasi sostantivi. La frase bel fiore ha il nome (N) fiore che viene descritto o qualificato usando l’aggettivo (ADJ) bello . Il simbolo del tag POS per gli aggettivi è ADJ .
- Adv(erb): Gli avverbi di solito fungono da modificatori per altre parole tra cui nomi, aggettivi, verbi o altri avverbi. La frase fiore molto bello ha l’avverbio (ADV) molto , che modifica l’aggettivo (ADJ) bello , indicando il grado in cui il fiore è bello. Il simbolo del tag POS per gli avverbi è ADV.
Oltre a queste quattro principali categorie di parti del discorso , ci sono altre categorie che si verificano frequentemente in lingua inglese. Questi includono pronomi, preposizioni, interiezioni, congiunzioni, determinanti e molti altri. Inoltre, ogni tag POS come il nome (N) può essere ulteriormente suddiviso in categorie come nomi singolari(NN), nomi propri singolari (NNP) e nomi plurali (NNS).
Il processo di classificazione ed etichettatura dei tag POS per le parole chiamate parti del discorso tagging o POS tagging . I tag POS sono usati per annotare le parole e rappresentare il loro POS, che è davvero utile per eseguire analisi specifiche, come restringere i nomi e vedere quali sono i più importanti, la disambiguazione del senso delle parole e l’analisi grammaticale. Utilizzeremo sia nltkchespacy che di solito usano la notazione Penn Treebank per il tagging POS.
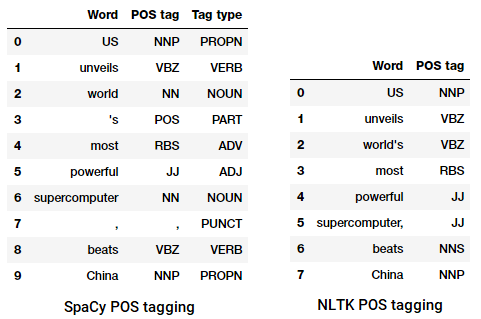
POS tagging a news headline
Possiamo vedere che ognuna di queste librerie tratta i token a modo loro e assegna loro tag specifici. Sulla base di ciò che vediamo, spacy sembra fare leggermente meglio di nltk.
Analisi superficiale o Chunking
In base alla gerarchia che abbiamo descritto in precedenza, gruppi di parole costituiscono frasi. Ci sono cinque principali categorie di frasi:
- Noun phrase (NP): Queste sono frasi in cui un sostantivo agisce come la parola principale. Le frasi sostantive agiscono come soggetto o oggetto di un verbo.
- Verb phrase (VP): Queste frasi sono unità lessicali che hanno un verbo che funge da parola principale. Di solito, ci sono due forme di frasi verbali. Una forma ha le componenti del verbo così come altre entità come nomi, aggettivi o avverbi come parti dell’oggetto.
- Aggettivo frase (ADJP): Queste sono frasi con un aggettivo come la parola testa. Il loro ruolo principale è quello di descrivere o qualificare sostantivi e pronomi in una frase, e saranno collocati prima o dopo il nome o il pronome.
- Avverbio frase (ADVP): Queste frasi agiscono come avverbi poiché l’avverbio agisce come la parola testa nella frase. Frasi avverbio sono usati come modificatori per nomi, verbi, o avverbi stessi fornendo ulteriori dettagli che descrivono o qualificarli.
- Frase preposizionale (PP): Queste frasi di solito contengono una preposizione come parola principale e altri componenti lessicali come nomi, pronomi e così via. Questi agiscono come un aggettivo o avverbio che descrive altre parole o frasi.
Shallow parsing, noto anche come light parsing o chunking, è una tecnica popolare di elaborazione del linguaggio naturale per analizzare la struttura di una frase per scomporla nei suoi costituenti più piccoli (che sono token come le parole) e raggrupparli in frasi di livello superiore. Questo include tag POS e frasi da una frase.
Un esempio di analisi superficiale che descrive annotazioni di frasi di livello superiore
Sfrutteremo il corpus conll2000 per addestrare il nostro modello di parser superficiale. Questo corpus è disponibile in nltk con annotazioni chunk e useremo circa 10K record per addestrare il nostro modello. Una frase annotata di esempio è rappresentata come segue.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
Dall’output precedente, puoi vedere che i nostri punti dati sono frasi che sono già annotate con metadati di frasi e tag POS che saranno utili per addestrare il nostro modello di parser superficiale. Useremo due funzioni di utilità di chunking, tree2conlltags, per ottenere tripli di tag word, tag e chunk per ogni token e conlltags2tree per generare un albero di analisi da questi tripli token. Useremo queste funzioni per addestrare il nostro parser. Un esempio è raffigurato di seguito.
I tag chunk utilizzano il formato IOB. Questa notazione rappresenta l’interno, l’esterno e l’inizio. Il prefisso B prima di un tag indica che è l’inizio di un blocco e il prefisso I indica che si trova all’interno di un blocco. Il tag O indica che il token non appartiene a nessun blocco. Il B-tag viene sempre utilizzato quando ci sono tag successivi dello stesso tipo che lo seguono senza la presenza di tag O tra di loro.
vediamo ora di definire una funzione conll_tag_ chunks() per estrarre POS e chunk tag frasi con blocchi di annotazioni e di una funzione denominata combined_taggers() per il treno più tagger con backoff tagger (es. unigram e bigram tagger)
vediamo ora di definire una classe NGramTagChunker che tagged frasi di formazione di ingresso, ottenere il loro (word, POS tag, Chunk tag) WTC triple, la formazione di un BigramTagger con un UnigramTagger come il backoff tagger. Ci sarà anche definire un parse() funzione per eseguire una superficiale analisi sulle nuove frasi
UnigramTaggerBigramTaggereTrigramTaggersono classi che ereditano dalla classe baseNGramTagger, che si eredita dallaContextTaggerclasse che eredita dallaSequentialBackoffTaggerclasse.
potremo utilizzare questa classe per il treno, conll2000 chunked train_data e valutare le prestazioni dei modelli su test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
il chunking modello ottiene un’accuratezza di circa il 90%, che è abbastanza buono! Sfruttiamo ora questo modello per analizzare e tagliare il titolo del nostro articolo di esempio che abbiamo usato in precedenza, ” US svela il supercomputer più potente del mondo, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
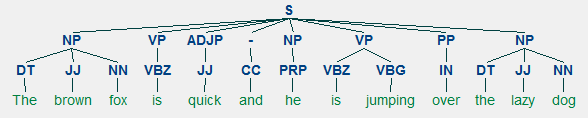
Così si può vedere che ha identificato due sintagmi nominali (NP) e un verbo della frase (VP) nell’articolo di notizie. Sono visibili anche i tag POS di ogni parola. Possiamo anche visualizzarlo sotto forma di un albero come segue. Potrebbe essere necessario installare ghostscript nel caso in cuinltk genera un errore.

Shallow parsed news headline
L’output precedente dà un buon senso della struttura dopo l’analisi superficiale del titolo delle notizie.
Analisi della circoscrizione
Le grammatiche basate sui costituenti sono utilizzate per analizzare e determinare i costituenti di una frase. Queste grammatiche possono essere utilizzate per modellare o rappresentare la struttura interna delle frasi in termini di una struttura gerarchicamente ordinata dei loro costituenti. Ogni parola di solito appartiene a una specifica categoria lessicale nel caso e forma la parola principale di frasi diverse. Queste frasi sono formate in base a regole chiamate regole di struttura delle frasi.
Le regole di struttura delle frasi costituiscono il nucleo delle grammatiche di circoscrizione, perché parlano di sintassi e regole che governano la gerarchia e l’ordinamento dei vari costituenti nelle frasi. Queste regole si rivolgono principalmente a due cose.
- Determinano quali parole vengono utilizzate per costruire le frasi o i costituenti.
- Determinano come dobbiamo ordinare questi costituenti insieme.
La rappresentazione generica di una regola di struttura della frase è S → AB , che descrive che la struttura S è costituita dai costituenti A e B e l’ordine è A seguito di B . Mentre ci sono diverse regole (fare riferimento al Capitolo 1, Pagina 19: Analisi del testo con Python, se si desidera approfondire), la regola più importante descrive come dividere una frase o una clausola. La regola della struttura della frase denota una divisione binaria per una frase o una clausola come S → NP VP dove S è la frase o la clausola, ed è divisa nel soggetto, indicato dalla frase sostantiva (NP) e dal predicato, indicato dalla frase verbale (VP).
Un parser di circoscrizione può essere costruito in base a tali grammatiche / regole, che di solito sono collettivamente disponibili come grammatica senza contesto (CFG) o grammatica strutturata in frasi. Il parser elaborerà le frasi di input in base a queste regole e aiuterà a costruire un albero di analisi.
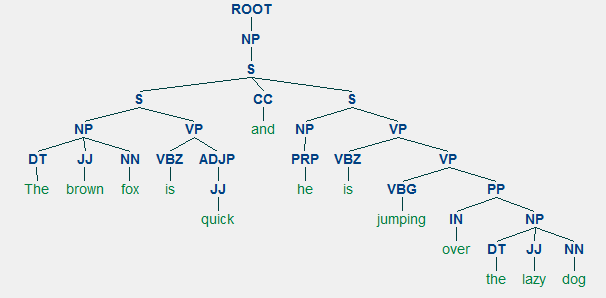
Un esempio di analisi della circoscrizione che mostra una struttura gerarchica nidificata
Useremo nltk e StanfordParser qui per generare alberi di analisi.
Prerequisiti: Scarica il Parser ufficiale di Stanford da qui, che sembra funzionare abbastanza bene. Puoi provare una versione successiva andando su questo sito Web e controllando la sezione Cronologia delle versioni. Dopo il download, decomprimerlo in una posizione nota nel file system. Una volta fatto, ora sei pronto per usare il parser da
nltk, che esploreremo presto.
Il parser di Stanford utilizza generalmente un parser PCFG (probabilistic context-free grammar). Un PCFG è una grammatica senza contesto che associa una probabilità a ciascuna delle sue regole di produzione. La probabilità di un albero di analisi generato da un PCFG è semplicemente la produzione delle probabilità individuali delle produzioni utilizzate per generarlo.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Possiamo vedere l’albero di analisi del collegio elettorale per il nostro titolo di notizie. Visualizziamolo per capire meglio la struttura.
from IPython.display import displaydisplay(result)
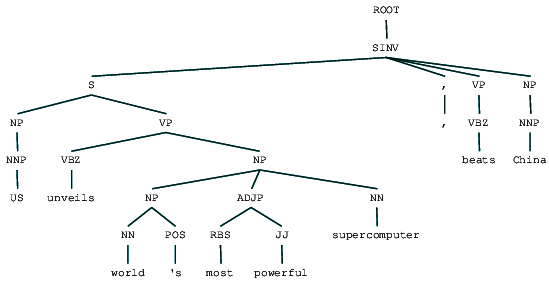
Circoscrizione analizzato news headline
Siamo in grado di vedere il nidificati struttura gerarchica dei costituenti nella precedente uscita rispetto alla struttura piana in acque poco profonde analisi. Nel caso in cui ti stai chiedendo cosa significhi SINV, rappresenta una frase dichiarativa invertita, cioè una in cui il soggetto segue il verbo teso o modale. Fare riferimento al riferimento Penn Treebank come necessario per cercare altri tag.
Analisi delle dipendenze
Nell’analisi delle dipendenze, cerchiamo di utilizzare grammatiche basate sulle dipendenze per analizzare e dedurre sia la struttura che le dipendenze semantiche e le relazioni tra i token in una frase. Il principio di base alla base di una grammatica di dipendenza è che in qualsiasi frase della lingua, tutte le parole tranne una, hanno qualche relazione o dipendenza da altre parole nella frase. La parola che non ha dipendenza è chiamata radice della frase. Il verbo è preso come radice della frase nella maggior parte dei casi. Tutte le altre parole sono direttamente o indirettamente collegate al verbo radice usando i collegamenti, che sono le dipendenze.
Considerando la nostra frase “La volpe marrone è veloce e saltando over the lazy dog”, se volessimo disegnare la dipendenza albero di sintassi per questo, ci sarebbe la struttura
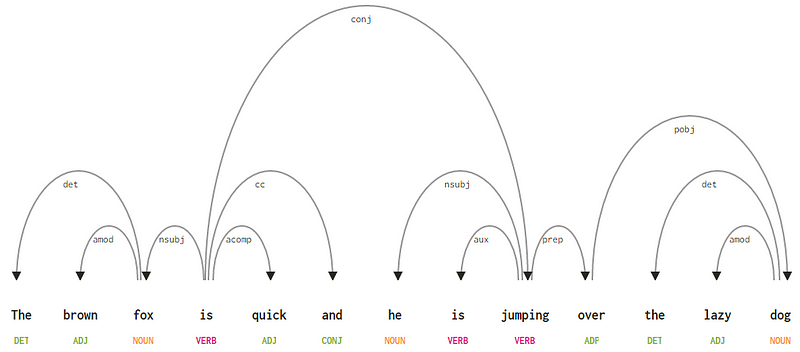
Una dipendenza albero sintattico di una frase
Questi rapporti di dipendenza hanno un loro significato e sono una parte di un elenco di universale tipi di dipendenza. Questo è discusso in un documento originale, Universal Stanford Dependencies: A Cross-Linguistic Typology di de Marneffe et al, 2014). È possibile controllare l’elenco esaustivo dei tipi di dipendenza e il loro significato qui.
Se osserviamo alcune di queste dipendenze, non è troppo difficile capirle.
- Il tag di dipendenza det è piuttosto intuitivo — denota la relazione determinante tra una testa nominale e il determinante. Di solito, la parola con POS tag DET avrà anche la relazione det dependency tag. Gli esempi includono
fox → theedog → the. - Il tag di dipendenza amod sta per adjectival modifier e sta per qualsiasi aggettivo che modifica il significato di un nome. Gli esempi includono
fox → brownedog → lazy. - Il tag di dipendenza nsubj sta per un’entità che agisce come soggetto o agente in una clausola. Gli esempi includono
is → foxejumping → he. - Le dipendenze cc e conj hanno più a che fare con collegamenti relativi a parole collegate da congiunzioni coordinate . Gli esempi includono
is → andeis → jumping. - Il tag di dipendenza aux indica il verbo ausiliario o secondario nella clausola. Esempio:
jumping → is. - Il tag di dipendenza acomp sta per complemento aggettivo e agisce come complemento o oggetto di un verbo nella frase. Esempio:
is → quick - Il tag di dipendenza prep denota un modificatore preposizionale, che di solito modifica il significato di un nome, verbo, aggettivo o preposizione. Di solito, questa rappresentazione viene utilizzata per le preposizioni con un complemento sostantivo o sostantivo. Esempio:
jumping → over. - Il tag di dipendenza pobj è usato per indicare l’oggetto di una preposizione . Questo è di solito la testa di una frase sostantivo dopo una preposizione nella frase. Esempio:
over → dog.
Spacy aveva due tipi di parser di dipendenza inglese in base ai modelli linguistici che usi, puoi trovare maggiori dettagli qui. In base ai modelli linguistici, è possibile utilizzare lo schema di dipendenze universali o lo schema di dipendenze CLEAR Style disponibile ora anche in NLP4J. Ora sfrutteremo spacy e stamperemo le dipendenze per ogni token nel nostro titolo delle notizie.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
È evidente che il verbo beats è la RADICE poiché non ha altre dipendenze rispetto agli altri token. Per saperne di più su ogni annotazione puoi sempre fare riferimento allo schema di dipendenza CLEAR. Possiamo anche visualizzare le dipendenze di cui sopra in un modo migliore.
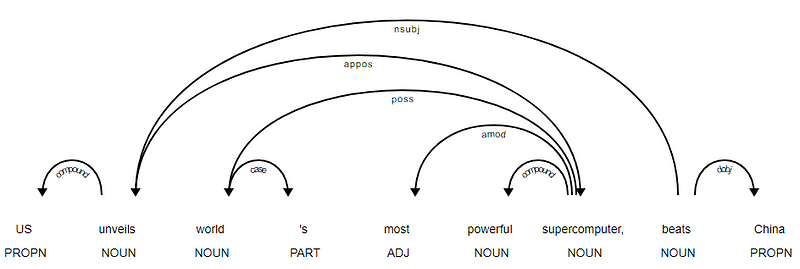
News Headline albero delle dipendenze da SpaCy
È anche possibile sfruttare nltk e StanfordDependencyParser per visualizzare e costruire l’albero delle dipendenze. Mostriamo l’albero delle dipendenze sia nella sua forma grezza che annotata come segue.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
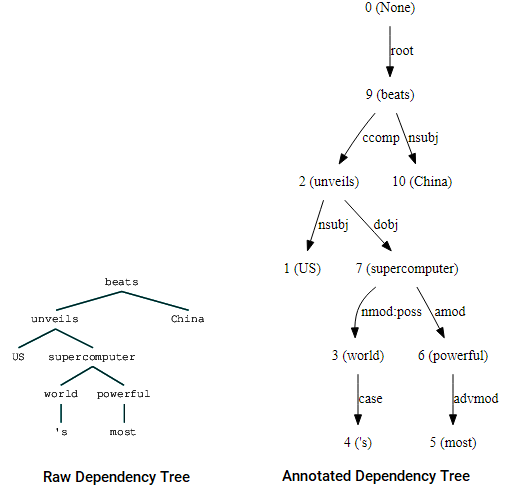
Albero delle Dipendenze visualizzazioni utilizzando nltk della Stanford dipendenza parser
Si possono notare le similitudini con l’albero ci aveva ottenuto in precedenza. Le annotazioni aiutano a comprendere il tipo di dipendenza tra i diversi token.
Bio: Dipanjan Sarkar è uno scienziato di dati @Intel, un autore, un mentore @trampolino di lancio, uno scrittore e un tossicodipendente sportivo e sitcom.
Originale. Ripubblicato con il permesso.
Correlati:
- Modelli Word2Vec robusti con Gensim& Applicazione delle funzionalità Word2Vec per attività di apprendimento automatico
- Apprendimento automatico interpretabile umano (parte 1) — La necessità e l’importanza dell’interpretazione del modello
- Implementazione di metodi di apprendimento profondo e ingegneria delle funzionalità per i dati di testo: Il modello Skip-gram