KDnuggets
どの言語でも、構文と構造は通常、特定の規則、規則、原則のセットが単語をフレーズに結合する方法を支配し、フレーズは句に結合され、句は文に結合され このセクションでは、英語の構文と構造について具体的に説明します。 英語では、単語は通常、他の構成単位を形成するために一緒に結合します。 これらの構成要素には、単語、句、句、および文が含まれます。 “茶色のキツネは速く、彼は怠惰な犬を飛び越えている”という文を考えると、それは言葉の束で作られており、自分で言葉を見ているだけではあまり教えてくれません。

順序付けられていない単語の束は、多くの情報を伝えません
言語の構造と構文に関する知識は、テキスト処理、注釈、およびテキスト分類や要約などのさらなる操作のための解析のような多くの分野で役立ちます。 テキスト構文を理解するための典型的な解析手法を以下に示します。
- 品詞(POS)タグ付け
- 浅い解析またはチャンク
- 選挙区解析
- 依存性解析
以降のセクションでは、これらのテクニックをすべて見ていきます。 前の例文”the brown fox is quick and he is jumping over the lazy dog”を考えると、基本的なPOSタグを使用して注釈を付けると、次の図のようになります。

文のPOSタグ付け
したがって、文は通常、次のコンポーネントからなる階層構造に従います。
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
文→句→フレーズ→単語
/p>
品詞のタグ付け
品詞(pos)は、その構文的文脈と役割に基づいて、単語が割り当てられている特定の語彙カテゴリです。 通常、単語は次の主要なカテゴリのいずれかに分類できます。
- N(oun)
- N(oun): これは、通常、生きているか、生きていないかもしれないいくつかのオブジェクトまたはエンティティを描写する言葉を示します。 いくつかの例は、fox、dog、bookなどです。 名詞のPOSタグ記号はNです。
- V(erb):動詞は、特定のアクション、状態、または発生を記述するために使用される単語です。 補助動詞、再帰動詞、他動詞など、さまざまなサブカテゴリがあります(さらに多くのものもあります)。 動詞のいくつかの典型的な例は、実行、ジャンプ、読み取り、および書き込みされます。 動詞のPOSタグ記号はVです。
- Adj(ective): 形容詞は、他の単語を記述または修飾するために使用される単語であり、典型的には名詞および名詞句である。 フレーズ美しい花は形容詞(ADJ)美しいを使用して説明または修飾された名詞(N)花を持っています。 形容詞のPOSタグ記号はADJです。Adv(erb):副詞は、通常、名詞、形容詞、動詞、または他の副詞を含む他の単語の修飾子として機能します。
- Adv(erb):副詞は、通常、名詞、形容詞、動詞、または他の副詞を含む他の フレーズ非常に美しい花は、花が美しい程度を示す、形容詞(ADJ)美しいを変更する副詞(ADV)非常にを持っています。 副詞のPOSタグ記号はADVです。品詞のこれらの4つの主要なカテゴリのほかに、英語で頻繁に発生する他のカテゴリがあります。
これらには、代名詞、前置詞、間投詞、接続詞、決定子、および他の多くが含まれます。 さらに、名詞(N)のような各POSタグは、単数名詞(NN)、単数固有名詞(NNP)、および複数名詞(NNS)のようなカテゴリにさらに細分することができます。
品詞タグ付けまたはPOSタグ付けと呼ばれる単語のPOSタグを分類し、ラベル付けするプロセス。 POSタグは、単語に注釈を付け、そのPOSを描写するために使用され、名詞を絞り込み、最も顕著なもの、単語の意味の曖昧さ回避、文法分析など、特定の分析を実 私たちは、POSタグ付けに通常Penn Treebank表記を使用する
nltkspacyの両方を活用します。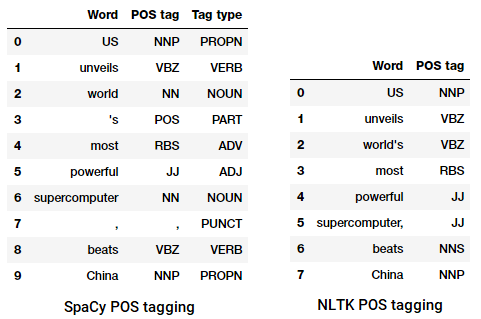
POSニュース見出しをタグ付けこれらのライブラリのそれぞれが独自の方法でトークンを扱い、 私たちが見ていることに基づいて、
spacynltkよりもわずかに優れているようです。浅い解析またはチャンク
前に示した階層に基づいて、単語のグループがフレーズを構成します。 フレーズの5つの主要なカテゴリがあります:
- 名詞句(NP): これらは、名詞が頭の単語として機能するフレーズです。 名詞句は、動詞の主語または目的語として機能します。
- 動詞句(VP):これらの句は、頭の単語として機能する動詞を持つ語彙単位です。 通常、動詞句には2つの形式があります。 一つの形式は、オブジェクトの一部として名詞、形容詞、または副詞などの動詞のコンポーネントだけでなく、他のエンティティを持っています。形容詞句(ADJP):これらは、頭の単語として形容詞を持つフレーズです。
- 形容詞句(ADJP):これらは、頭の単語として形容詞を持つフレーズです。 彼らの主な役割は、文章中の名詞と代名詞を記述または修飾することであり、名詞または代名詞の前または後に配置されます。副詞句(ADVP):副詞がフレーズ内の頭の単語として機能するので、これらのフレーズは副詞のように機能します。
- 副詞句(ADVP):副詞がフレーズ内の頭の単語とし 副詞句は、それらを記述または修飾するさらなる詳細を提供することにより、名詞、動詞、または副詞自体の修飾子として使用されます。
- 前置詞句(PP):これらの句は、通常、頭の単語としての前置詞や、名詞、代名詞などの他の語彙構成要素を含みます。 これらは、他の単語やフレーズを記述する形容詞や副詞のように機能します。
浅い構文解析は、軽い構文解析またはチャンクとしても知られており、文の構造を分析して最小の構成要素(単語などのトークン)に分解し、それらを これには、POSタグと文のフレーズが含まれます。
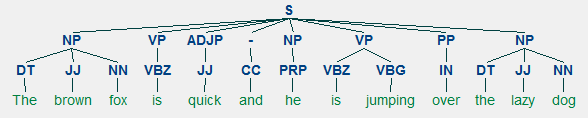
より高いレベルのフレーズ注釈を描いた浅い解析の例浅いパーサモデルをトレーニングするために
conll2000nltkチャンク注釈付きで利用でき、モデルのトレーニングに約10Kのレコードを使用します。 注釈文の例は次のように示されています。10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
前の出力から、データポイントはすでにフレーズとPOSタグメタデータで注釈が付けられている文であり、浅いパーサモデ 2つのチャンクユーティリティ関数tree2conlltagsを利用して、各トークンのword、tag、およびchunkタグのトリプルを取得し、conlltags2treeを利用して、これらのトークントリプルから解析ツリーを生成します。 これらの関数を使用してパーサーを訓練します。 以下にサンプルを示します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。
チャンクタグはIOB形式を使用します。 この表記法は、内側、外側、および開始を表します。 タグの前のB-prefixは、チャンクの先頭であることを示し、I-prefixはチャンクの内側にあることを示します。 Oタグは、トークンがどのチャンクにも属していないことを示します。 Bタグは、それらの間にOタグが存在せずに、それに続く同じタイプの後続のタグがある場合に常に使用されます。
チャンクされた注釈を持つ文からPOSタグとチャンクタグを抽出する関数
conll_tag_ chunks()combined_taggers()バックオフタガー(例えばunigramとbigramタガー)を持つ複数のタガーを訓練する関数クラスを定義する
NGramTagChunkerタグ付けされた文章をトレーニング入力として取り込み、(単語、posタグ、チャンクタグ)wtcトリプルを取得し、バックオフタガーとしてBigramTaggerUnigramTaggerparse()関数を定義しますUnigramTaggerBigramTaggerTrigramTaggerNGramTaggerContextTaggerSequentialBackoffTaggerconll2000chunkedtrain_datatest_dataでモデルのパフォーマンスを評価します私たちのチャンクモデルは約90%の精度を取得しますが、これはかなり良いことです! さて、このモデルを活用して、以前に使用したサンプルニュース記事の見出し”米国は世界で最も強力なスーパーコンピュータを発表し、中国を打ち負かす”を浅したがって、あなたはそれが識別されている見ることができます。
したがって、あなたはそれが識別されています。
したがって、あなたはそれが識別されている見ることができます。
ニュース記事の2つの名詞句(NP)と1つの動詞句(vp)。 各単語のPOSタグも表示されます。 これを次のようにツリーの形で視覚化することもできます。
nltkがエラーをスローする場合に備えて、ghostscriptをインストールする必要がある場合があります。
浅い解析されたニュース見出し前の出力は、ニュース見出しを浅い解析した後の構造の良
構成要素解析
構成ベースの文法は、文の構成要素を分析および決定するために使用されます。 これらの文法は、文の構成要素の階層的に順序付けられた構造の観点から文の内部構造をモデル化または表現するために使用することができる。 それぞれの単語は、通常、ケース内の特定の語彙カテゴリに属し、異なるフレーズの頭の単語を形成します。 これらの句は、句構造規則と呼ばれる規則に基づいて形成されます。
句構造規則は、文中のさまざまな構成要素の階層と順序を支配する構文と規則について話すため、構成文法の中核を形成します。 これらのルールは、主に二つのことに応えます。彼らは、フレーズや構成要素を構築するために使用される単語を決定します。
- 彼らは、フレーズや構成要素を構築するために使用される単語を決定
- これらの成分を一緒に注文する必要があるかどうかを決定します。
フレーズ構造規則の一般的な表現はS→ABであり、構造Sは構成要素AとBで構成され、順序はaの後にBが続くことを示しています。 いくつかのルールがありますが(深く掘り下げたい場合は、第1章19ページ:Pythonを使用したテキスト分析を参照)、最も重要なルールは文または句を分割する方 句構造規則は、s→NP VPとして文または句のバイナリ分割を示し、sは文または句であり、名詞句(NP)で表される主語と動詞句(VP)で表される述語に分割され
コンスティチュエンスパーサは、通常、文脈自由文法(CFG)またはフレーズ構造化文法としてまとめて利用可能な文法/規則に基づいて構築することができ パーサーは、これらのルールに従って入力文を処理し、解析ツリーの構築に役立ちます。
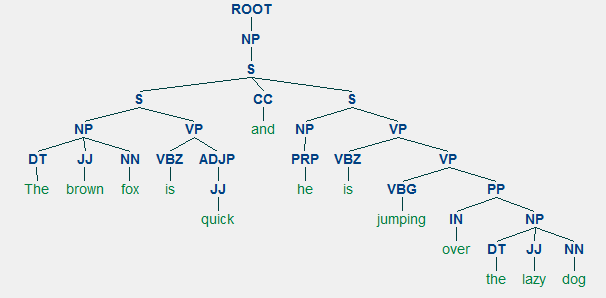
ネストされた階層構造を示す選挙構文解析の例nltkStanfordParserここで解析木を生成します。前提条件:公式のStanfordパーサをダウンロードしますここから、これは非常にうまく動作するようです。 このウェブサイトにアクセスし、リリース履歴セクションを確認することで、それ以降のバージョンを試すことができます。 ダウンロード後、ファイルシステム内の既知の場所に解凍します。 完了したら、nltkのパーサーを使用する準備が整いました。P>スタンフォードパーサーは、一般的にPCFG(確率的文脈自由文法)パーサーを使用しています。 PCFGは、確率をそれぞれの生成規則に関連付ける文脈自由文法です。 PCFGから生成された解析木の確率は、単にそれを生成するために使用される生産の個々の確率の生産です。
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
ニュース見出しの選挙解析ツリーを見ることができます。 構造をよりよく理解するためにそれを視覚化しましょう。/div>
from IPython.display import displaydisplay(result)
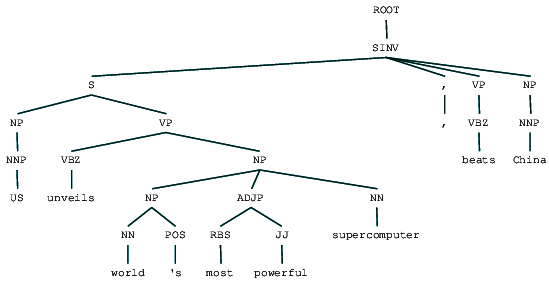
選挙区解析されたニュース見出し選挙区解析されたニュース見出し
/div>
浅い解析では、フラット構造と比較して、前の出力で構成要素のネストされた階層構造を見ることができます。 SINVが何を意味するのか疑問に思っている場合、それは反転宣言文、すなわち主語が緊張動詞またはモーダルに従うものを表します。 他のタグを検索するには、必要に応じてPenn Treebankリファレンスを参照してください。
依存性解析
依存性解析では、依存性ベースの文法を使用して、文中のトークン間の構造と意味的な依存関係と関係の両方を分析し、推論しようとします。 依存文法の背後にある基本的な原則は、その言語のどの文でも、1つを除くすべての単語が、その文の他の単語に何らかの関係または依存関係を持 依存関係のない単語は、文のルートと呼ばれます。 動詞は、ほとんどの場合、文のルートとして取られます。 他のすべての単語は、依存関係であるリンクを使用してルート動詞に直接または間接的にリンクされています。
“the brown fox is quick and he is jumping over the lazy dog”という文を考えると、このための依存関係構文ツリーを描画したい場合は、構造
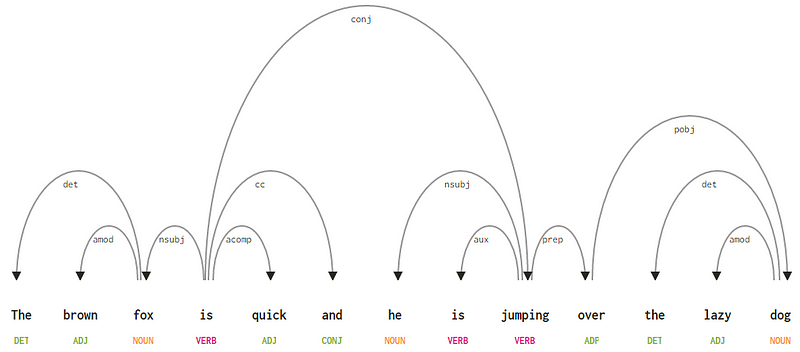
文の依存関係解析ツリーこれらの依存関係はそれぞれ独自の意味であり、普遍的な依存関係タイプのリストの一部です。 これは、元の論文、Universal Stanford Dependencies:A Cross-Linguistic Typology by de Marneffe et al、2014で議論されています)。 依存関係の種類とその意味の網羅的なリストをここで確認できます。
これらの依存関係のいくつかを観察すると、それらを理解するのはそれほど難しくありません。
- 依存関係タグdetは非常に直感的です—それは名目上の頭部と決定器との間の決定器の関係を示します。 通常、POSタグDETを持つ単語には、det依存関係タグの関係もあります。 例としては、
fox → thedog → theがあります。 - 依存タグamodは形容詞修飾子を表し、名詞の意味を変更する任意の形容詞を表します。 例としては、
fox → browndog → lazyがあります。 - 依存関係タグnsubjは、句内でサブジェクトまたはエージェントとして機能するエンティティを表します。 例としては、
is → foxjumping → heがあります。 - 依存関係ccとconjは、接続詞を調整することによって接続された単語に関連するリンケージとより多くの関係を持っています。 例としては、
is → andis → jumpingがあります。 - 依存関係タグauxは、句内の補助動詞または二次動詞を示します。 例:
jumping → is。依存関係タグacompは形容詞補語の略で、文中の動詞の補語または目的語として機能します。 - 依存関係タグacompは形容詞補語の略で、文中の動詞の補語ま 例:
is → quick - 依存関係タグprepは、通常、名詞、動詞、形容詞、または前置詞の意味を変更する前置詞修飾子を示します。 通常、この表現は、名詞または名詞句の補語を持つ前置詞に使用されます。 例:
jumping → over。 - 依存関係タグpobjは、前置詞のオブジェクトを示すために使用されます。 これは通常、文の前置詞に続く名詞句の頭です。 例:
over → dog。
Spacyは、使用する言語モデルに基づいて、英語の依存パーサーの二つのタイプを持っていました。 言語モデルに基づいて、Nlp4Jでも利用可能なUniversal DependenciesスキームまたはCLEAR Style Dependenciesスキームを使用できるようになりました。 ここでは
spacyを活用し、ニュースの見出しに各トークンの依存関係を出力します。それは他のトークンと比較して、他の依存関係を持っていないので、動詞beatsがルートであることは明らかです。 各注釈の詳細については、いつでも明確な依存関係スキームを参照することができます。 上記の依存関係をより良い方法で視覚化することもできます。P>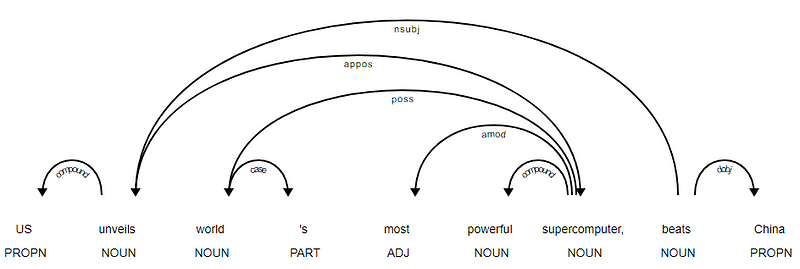
SpaCyからのニュース見出しの依存関係ツリーまた、
nltkStanfordDependencyParser依存関係ツリーを視覚化して構築する。 次のように、依存関係ツリーを生の形式と注釈付きの形式の両方で紹介します。d>(beats (unveils US (supercomputer (world 's) (powerful most))) China)
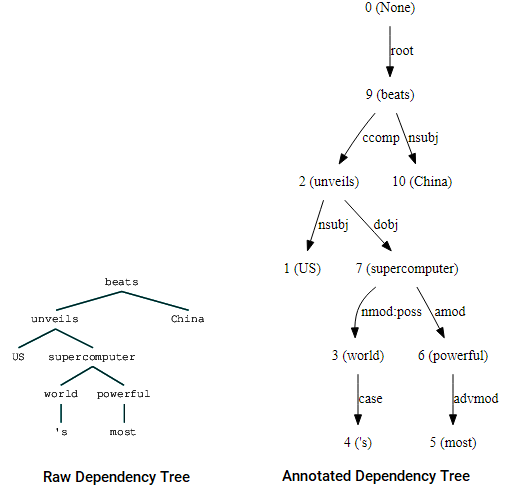
nltkのスタンフォード依存関係パーサーを使用した依存関係ツリーの視覚化(beats (unveils US (supercomputer (world 's) (powerful most))) China)
nltkのスタンフォード依存関係パーサーを使用した依存関係ツリーの視覚化
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
nltkのスタンフォード依存関係パーサーを使用した依存関係ツリーの視覚化
以前に取得したツリーとの類似点に気づくことができます。 注釈は、異なるトークン間の依存関係のタイプを理解するのに役立ちます。
バイオ:Dipanjan Sarkarは、データ科学者@Intel、著者、メンター@Springboard、作家、スポーツとシットコム中毒者です。オリジナル。
許可を得て再投稿。
関連するページ
:
- Gensimを使用した堅牢なWord2Vecモデル&機械学習タスクにWord2Vec機能を適用する
- 人間の解釈可能な機械学習(パート1)—モデル解釈の必要性と重要性
- テキストデータの深層学習メソッドと特徴工学の実装:スキップグラムモデル