, Co každý programátor naprosto, pozitivně musí vědět o kódování a znakové sady pro práci s text
Pokud máte co do činění s textem v počítači, co potřebujete vědět o kódování. Období. Ano, i když právě posíláte e-maily. I když právě dostáváte e-maily. Nemusíte rozumět každému poslednímu detailu, ale musíte alespoň vědět, o čem je celá tato „kódování“. A dobrá zpráva jako první: zatímco téma může být chaotické a matoucí, základní myšlenka je opravdu, opravdu jednoduché.
Tento článek pojednává o kódování a znakových sadách. Článek Joela Spolského s názvem absolutní Minimum každý vývojář softwaru absolutně, pozitivně musí vědět o Unicode a znakových sadách (žádné výmluvy!) je pěkný úvod k tématu a velmi mě baví číst to jednou za čas. Váhám odkazovat na lidi, kteří mají potíže s porozuměním problémům s kódováním, i když, zatímco zábavné, je to docela lehké na skutečné technické detaily. Doufám, že tento článek může vrhnout nějaké další světlo na to, co přesně kódování je a proč všechny vaše textové šrouby, když to nejméně potřebujete. Tento článek je zaměřen na vývojáře (se zaměřením na PHP), ale každý uživatel počítače by z něj měl mít prospěch.
základy rovně
Každý je si vědom toho, na určité úrovni, ale nějak to poznání, zdá se, náhle zmizí v diskusi o textu, tak pojďme na to první: počítač nelze uložit „dopisy“, „čísla“, „obrázky“ nebo cokoliv jiného. Jediná věc, kterou může ukládat a pracovat, jsou bity. Bit může mít pouze dvě hodnoty: yes nebo notrue nebo false1 nebo 0 nebo cokoli jiného, co chcete volat tyto dvě hodnoty. Protože počítač pracuje s elektřinou, „skutečný“ bit je výkyv elektřiny, který tam buď je, nebo není. Pro lidi je to obvykle reprezentováno pomocí 1 a 0 a budu se držet této konvence v tomto článku.
Chcete-li použít bity k reprezentaci všeho kromě bitů, potřebujeme pravidla. Musíme převést posloupnost bitů na něco jako písmena, čísla a obrázky pomocí schématu kódování nebo zkrátka kódování. Jako toto:
01100010 01101001 01110100 01110011b i t sV tomto kódování, 01100010 je zkratka pro písmeno „b“, 01101001 pro písmeno „i“, 01110100 je zkratka pro „t“ a 01110011 „s“. Určitá posloupnost bitů znamená písmeno a písmeno znamená určitou posloupnost bitů. Pokud to dokážete udržet v hlavě 26 písmen nebo jste opravdu rychlí s hledáním věcí v tabulce, můžete číst kousky jako kniha.
výše uvedené schéma kódování je ASCII. Řetězec 1 s a 0 s je rozdělen na části po osmi bitech (zkráceně bajt). Kódování ASCII určuje tabulku, která převádí bajty na písmena čitelná člověkem. Zde je krátký výňatek z této tabulky:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable znaky uvedené v tabulce ASCII, včetně písmen a až z velkými i malými písmeny, čísla 0 až 9, hrst interpunkčních znamének a znaků, jako je symbol dolaru, ampersand a několik dalších. Obsahuje také 33 hodnoty pro věci, jako je prostor, line feed, tab, backspace a tak dále. Ty nejsou samy o sobě tisknutelné, ale stále viditelné v nějaké formě a užitečné pro člověka přímo. Řada hodnot je užitečná pouze pro počítač, jako jsou kódy označující začátek nebo konec textu. Celkem jsou k dispozici 128 znaků definovaných v kódování ASCII, což je pěkné číslo (pro lidi, zabývající se počítači), protože používá všechny možné kombinace 7 bitů (0000000000000100000101111111).1
A tady to máte, nejlepší způsob, jak reprezentovat lidský-čitelný text pouze pomocí 10y.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100„Hello World“
Důležité pojmy
Pro enkódování něco v ASCII, postupujte podle tabulky zprava doleva, nahrazující písmena na kousky. Chcete-li dekódovat řetězec bitů na znaky čitelné pro člověka, postupujte podle tabulky zleva doprava a nahrazujte bity písmeny.
kódování |enˈkōd|
sloveso
převést do kódované forměkód |kōd|
jméno
systém slova, písmena, čísla nebo jiné symboly nahradit jinými slovy, písmeny, atd.
kódování znamená použít něco k reprezentaci něčeho jiného. Kódování je sada pravidel, pomocí kterých lze něco převést z jedné reprezentace na druhou.
další pojmy, které si zaslouží objasnění v této souvislosti:
znaková sada, znaková sada znaků, které lze zakódovat. „Kódování ASCII zahrnuje znakovou sadu 128 znaků.“V podstatě synonymem pro“kódování“. kódová stránka „Stránka“ kódů, které mapují znak na číselnou nebo bitovou sekvenci. A. k. a. „stůl“. V podstatě synonymem pro „kódování“. řetězec řetězec je banda položek navlečených dohromady. Bitový řetězec je banda bitů, jako01010011. Řetězec znaků je banda znaků,like this. Synonymum pro „sekvenci“.
binární, osmičkové, desetinné, hex
existuje mnoho způsobů, jak psát čísla. 10011111 v binární je 237 v osmičkové je 159 v desítkové je 9F v šestnáctkové soustavě. Všechny představují stejnou hodnotu, ale hexadecimální je kratší a čitelnější než binární. V tomto článku se budu držet binárního, abych lépe získal bod a ušetřil čtenáře jednu vrstvu abstrakce. Nebojte se vidět znakové kódy uvedené v jiných notacích jinde, je to totéž.
Excusez-moi?
Nyní, když víme, o čem mluvíme, řekněme to: 95 znaků opravdu není mnoho, pokud jde o jazyky. Pokrývá základy angličtiny, ale co psaní riskantního dopisu ve francouzštině? Straßenübergangsänderungsgesetz v němčině? Pozvánka na smörgåsbord ve švédštině? Ne v ASCII. Neexistuje žádná specifikace, jak reprezentovat některá písmena é, ß, ü, ä, ö nebo å v ASCII, takže je nemůžete použít.
„ale podívejte se na to,“ řekli Evropané, „v běžném počítači s 8 bity na bajt ASCII ztrácí celý bit, který je vždy nastaven na 0! Můžeme použít tento bit zmáčknout celý ‚ nother 128 hodnoty do této tabulky!“A tak to udělali. Ale i tak existuje více než 128 způsobů, jak hladit, krájet, lomítkem a tečkovat samohlásku. Ne všechny variace písmen a čmáranice používá ve všech Evropských jazycích mohou být zastoupeny ve stejné tabulce s maximálně 256 hodnot. Svět tedy skončil s množstvím kódovacích schémat, standardů, de facto standardů a polovičních standardů, které pokrývají jinou podmnožinu znaků. Někdo potřeboval napsat dokument o švédštině v Češtině, zjistil, že žádné kódování nepokrývá oba jazyky a vymyslel jeden. Nebo si myslím, že to šlo nesčetněkrát.
a nezapomeňte na ruštinu, hindštinu, arabštinu, hebrejštinu, korejštinu a všechny ostatní jazyky, které jsou v současné době na této planetě aktivní. Nemluvě o těch, které se už nepoužívají. Jakmile vyřešíte problém, jak psát smíšené jazykové dokumenty ve všech těchto jazycích, vyzkoušejte si čínštinu. Nebo Japonci. Oba obsahují desítky tisíc znaků. Máte 256 možných hodnot na bajt skládající se z 8 bitů. Běž!
Multi-byte kódování
Chcete-li vytvořit tabulku, která mapuje znaky písmena pro jazyk, který používá více než 256 znaků, jeden bajt prostě není dost. Pomocí dvou bajtů (16 bitů) je možné zakódovat 65 536 odlišných hodnot. BIG-5 je takové dvoubajtové kódování. Místo toho, lámání řetězec bitů do bloků osm, láme do bloků 16 a má velký (myslím VELKOU) tabulku, která určuje, který znak každou kombinaci kousky mapy. BIG-5 ve své základní podobě pokrývá převážně tradiční čínské znaky. GB18030 je další kódování, které v podstatě dělá totéž, ale zahrnuje tradiční i zjednodušené čínské znaky. A než se zeptáte, ano, existují kódování, která pokrývají pouze zjednodušenou čínštinu. Nemůžeme teď mít jen jedno kódování, že?
zde malý výňatek z tabulky GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin znaky), ale nakonec je ještě další specializovaný formát kódování mezi mnoha.
Unicode zmatek

Konečně někdo měl dost bordel a vyrazil vytvořit prsten vázat je všechny vytvořit jeden standard kódování sjednotit všechny normy kódování. Tento standard je Unicode. V podstatě definuje ginormous tabulku 1,114,112 kódových bodů, které mohou být použity pro všechny druhy písmen a symbolů. To je spousta zakódovat všechny evropské, Středního východu, Dálného východu, Jižní, Severní, západní, pre-historik a budoucí postavy lidstvo ví.2 pomocí Unicode můžete napsat dokument obsahující prakticky jakýkoli jazyk pomocí libovolného znaku, který můžete zadat do počítače. To bylo buď nemožné, nebo velmi těžké se dostat těsně před Unicode přišel. V Unicode je dokonce neoficiální sekce pro Klingona. Unicode je skutečně dostatečně velký, aby umožnil neoficiální oblasti soukromého použití.
kolik bitů používá Unicode ke kódování všech těchto znaků? Žádný. Protože Unicode není kódování.
zmatený? Mnoho lidí se zdá být. Unicode v první řadě definuje tabulku kódových bodů pro znaky. To je fantastický způsob, jak říct „65 znamená A, 66 znamená B a 9 731 znamená ☃“ (vážně, to dělá). Jak jsou tyto Kódové body skutečně zakódovány do bitů, je jiné téma. K reprezentaci 1 114 112 různých hodnot nestačí dva bajty. Tři bajty jsou, ale tři bajty jsou často nepříjemné pracovat s, takže čtyři bajty by bylo pohodlné minimum. Ale, pokud jste vlastně používat Čínské nebo některé z dalších znaků, s velkými čísly, které se spousta bitů na enkódování, jste nikdy použít obrovský kus z těch čtyř bajtů. Pokud je písmeno „A“ je vždy kódované, aby 00000000 00000000 00000000 01000001, „B“ vždy do 00000000 00000000 00000000 01000010, a tak dále, jakýkoli dokument by udit až čtyřikrát potřebné velikosti.
Chcete-li to optimalizovat, existuje několik způsobů, jak kódovat Kódové body Unicode do bitů. UTF-32 je takové kódování, které kóduje všechny Kódové body Unicode pomocí 32 bitů. To znamená čtyři bajty na znak. Je to velmi jednoduché, ale často ztrácí spoustu místa. UTF-16 a UTF-8 jsou kódování s proměnnou délkou. Pokud lze znak reprezentovat pomocí jednoho bajtu (protože jeho kódový bod je velmi malé číslo), UTF-8 jej zakóduje jedním bajtem. Pokud to vyžaduje dva bajty, bude používat dva bajty a tak dále. Má propracované způsoby, jak použít nejvyšší bity v bajtu, aby signalizoval, kolik bajtů se znak skládá. To může ušetřit místo, ale může také ztrácet místo, pokud je třeba tyto signální bity často používat. UTF-16 je uprostřed, používá alespoň dva bajty a podle potřeby roste až na čtyři bajty.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
A to je všechno tam je k němu. Unicode je velká tabulka mapující znaky na čísla a různé kódování UTF určují, jak jsou tato čísla kódována jako bity. Celkově je Unicode dalším schématem kódování. Není na tom nic zvláštního, jen se snaží pokrýt vše a přitom být efektivní. A to je dobře.™
body Kódu
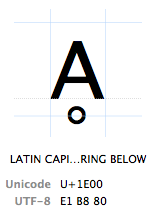
Znaky jsou podle jejich „bod kódu Unicode“. Kódové body Unicode jsou psány v šestnáctkové soustavě (aby byla čísla kratší), předchází „U+“ (to je přesně to, co dělají, nemá žádný jiný význam než „toto je kódový bod Unicode“). Znak Ḁ má kódový bod Unicode u+1E00. Jinými (desetinnými) slovy je to 7680. znak tabulky Unicode. Oficiálně se nazývá „Latinské VELKÉ písmeno A s kroužkem níže“.
TL;DR
přehled všech výše: Jakýkoliv znak může být kódován v mnoha různých bitových sekvencí a žádné konkrétní sekvence bit může reprezentovat mnoho různých znaků, v závislosti na kódování, které se používá k číst nebo psát. Důvodem je jednoduše to, že různá kódování používají různé počty bitů na znaky a různé hodnoty k reprezentaci různých znaků.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latin 1 | 01000110 11111000 11110110 |
| Føö | Mac Roman | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
Omylů, zmatků a problémů
Having řekl, že, přišli jsme na skutečné problémy, kterým čelí mnoho uživatelů a programátorů každý den, jak se tyto problémy se vztahují na všechny výše uvedené, a to, co jejich řešení. Největší problém ze všech je:
proč jsou proboha Moje postavy zkomolené?!
ÉGÉìÉRÅ;Pokud by $string bylo v jednobajtovém kódování, dalo by nám to první znak. Ale pouze proto, že „znak“ se shoduje s“ bajtem “ v jednobajtovém kódování. PHP nám jednoduše dává první bajt, aniž bychom přemýšleli o „postavách“. Řetězce jsou bajtové sekvence PHP, nic víc, nic méně. Všechny tyto“ čitelné znaky “ jsou lidská věc a PHP se o to nestará.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !totéž platí i pro mnoho standardních funkcí, jako jsou substrstrpostrim, a tak dále. Nepodpora vzniká, pokud existuje nesoulad mezi délkou bajtu a znakem.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Pomocí $string na výše uvedený řetězec, znovu, dejte nám první byte, který je 11100110. Jinými slovy, třetina tříbytového znaku“漢“. 11100110 je sama o sobě neplatná sekvence UTF-8, takže řetězec je nyní přerušen. Pokud se vám to líbí, můžete to zkusit interpretovat v jiném kódování, kde 11100110 představuje platný znak, který bude mít za následek nějaký náhodný znak. Bavte se, ale nepoužívejte jej ve výrobě.
a to je vlastně vše, co k tomu je. „PHP nativně nepodporuje Unicode“ jednoduše znamená, že většina PHP funkcí předpokládat, že jeden byte = jeden znak, což může vést k tomu sekání multi-byte znaky v polovině nebo výpočtu délky řetězce nesprávně pokud jste naivně použití non-multi-byte-aware funkce na multi-byte řetězce. To neznamená, že nemůžete používat Unicode v PHP nebo že každý řetězec Unicode musí být požehnáni tím utf8_encode, nebo podobné nesmysly.
naštěstí existuje vícebajtové Rozšíření řetězce, které replikuje všechny důležité funkce řetězce vícebajtovým způsobem. Pomocí mb_substr($string, 0, 1, 'UTF-8') na výše uvedeném řetězci správně vrátí 11100110 10111100 10100010, což je celý znak“ 漢“. Protože funkce mb_ nyní musí skutečně přemýšlet o tom, co dělají, potřebují vědět, na jakém kódování pracují. Proto každá funkce mb_ přijímá parametr $encoding. Alternativně lze nastavit globálně pro všechny funkce mb_ pomocí mb_internal_encoding.
používání a zneužívání nakládání s kódováním PHP
celý problém (ne)podpory PHP pro Unicode je, že je to prostě jedno. Řetězce jsou bajtové sekvence PHP. Na tom, jaké bajty konkrétně nezáleží. PHP nedělá nic s řetězci, kromě toho, že je uchovává v paměti. PHP prostě nemá žádnou koncepci znaků ani kódování. A pokud se snaží manipulovat řetězce, nemusí to buď; prostě to drží bajtů, které mohou nebo nemusí nakonec být interpretovány jako znaky, podle někoho jiného. Jediným požadavkem PHP má kódování je, že zdrojový kód PHP musí být uložen v kódování kompatibilním s ASCII. Analyzátor PHP hledá určité znaky, které mu říkají, co má dělat. $00100100) signalizuje začátek proměnné, =00111101) úkol, "00100010) začátek a konec řetězce a tak dále. Cokoli jiného, co nemá pro analyzátor žádný zvláštní význam, se považuje za doslovnou bajtovou sekvenci. To zahrnuje cokoli mezi uvozovkami, jak je uvedeno výše. To znamená následující:
-
zdrojový kód PHP nelze uložit do kódování nekompatibilního s ASCII. Například v UTF-16 je kódován
"jako00000000 00100010. Pro PHP, které se snaží číst vše jako ASCII, je toNULbajt následovaný".PHP pravděpodobně dostane škytavku, pokud každý další znak, který najde ,jeNULbajt. -
zdrojový kód PHP můžete uložit v libovolném kódování kompatibilním s ASCII. Pokud je prvních 128 kódových bodů kódováníidentický k ASCII, PHP jej může analyzovat. Všechny znaky, které jsou pro PHP jakkoli významné, jsou v 128 kódových bodech definovaných ASCII. Pokud řetězcové literály obsahují nějaké Kódové body za tím, PHP je to jedno. Zdrojový kód PHP můžete uložit do ISO-8859-1, Mac Roman, UTF-8 nebo jiného kódování kompatibilního s ASCII. Řetězcové literály ve skriptu bude cokoliv kódování jste uložili zdrojový kód.
-
jakýkoli externí soubor, který zpracováváte s PHP, může být v jakémkoli kódování, které se vám líbí. Pokud PHP nepotřebuje analyzovat, thereare žádné požadavky na splnění udržet PHP parser šťastný.
$foo = file_get_contents('bar.txt');výše uvedené bude prostě číst bity v
bar.txtdo proměnné$foo. PHP se nesnaží interpretovat, převádět, zakódovat nebo jinak manipulovat s obsahem. Soubor může dokonce obsahovat binární data, jako je obrázek,PHP je to jedno. -
Pokud se interní a externí kódování musí shodovat, musí se shodovat. Běžný případ je lokalizace, kde zdrojový kód obsahuje něco jako
echo localize('Foobar')a externí lokalizace souboru containssomething po vzoru tohoto:msgid "Foobar"msgstr "フーバー"„Foobar“ struny potřebují mít identické trochu zastupování, pokud chcete najít správné lokalizace.Pokud byl zdrojový kód uložen v ASCII, ale lokalizační soubor v UTF-16, řetězce by se neshodovaly.Buď by byla nutná nějaká konverze kódování, nebo použití funkce párování řetězců s vědomím kódování.
bystrý čtenář možná se na to zeptala, zda je možné uložit, řekněme, UTF-16 byte sekvenci uvnitř řetězcový literál z ASCII kódovaný zdrojový kód souboru, na kterou odpověď by byla: vůbec.
echo "UTF-16";Pokud si můžete přinést svůj textový editor, uložit echo ""; díly v ASCII a pouze UTF-16 v UTF-16, to bude fungovat v pohodě. Potřebná binární reprezentace pro to vypadá takto:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;první řádek a poslední dva bajty jsou ASCII. Zbytek je UTF-16 se dvěma bajty na znak. Vedoucí 11111110 11111111 na řádku 2 je značka požadovaná na začátku kódovaného textu UTF-16(vyžadováno standardem UTF-16, PHP je to zatraceně jedno). Tento PHP skript bude šťastně výstup řetězec „UTF-16“ kódovaný v UTF-16, protože je to jednoduché výstupy bajtů mezi dvěma uvozovkami, což se děje reprezentovat text „UTF-16“ kódovaný v UTF-16. Zdrojový kód souboru není ani zcela platný ASCII ani UTF-16, takže práce s ním v textovém editoru nebude moc zábavná.
Spodní řádek
PHP podporuje Unicode, nebo ve skutečnosti žádné kódování, jen v pořádku, pokud jsou splněny určité požadavky aby parser šťastný a programátor ví, co dělá. Při manipulaci s řetězci musíte být opravdu opatrní, což zahrnuje krájení, ořezávání, počítání a další operace, které se musí stát spíše na úrovni znaků než na úrovni bajtů. Pokud nejste „dělat něco“ s vaším řetězce kromě čtení a výstup je, sotva bude mít nějaké problémy s PHP podporu kódování, které byste si v jiných jazycích stejně.
Encoding-aware languages
Co to znamená pro jazyk podporovat Unicode pak? Javascript například podporuje Unicode. Ve skutečnosti je jakýkoli řetězec v JavaScriptu kódován UTF-16. Ve skutečnosti je to jediná věc, se kterou se Javascript zabývá. V JavaScriptu nemůžete mít řetězec, který není zakódován UTF-16. Javascript uctívá Unicode do té míry, že není žádné zařízení se vypořádat s jiné kódování v jádru jazyka. Protože Javascript je nejčastěji spuštěn v prohlížeči, což není problém, protože prohlížeč zvládne světskou logistiku kódování a dekódování vstupu a výstupu.
ostatní jazyky jsou jednoduše kódovány. Interně ukládají řetězce v určitém kódování, často UTF-16. Na druhé straně je třeba jim sdělit nebo se pokusit zjistit kódování všeho, co souvisí s textem. Potřebují vědět, jaké kódování zdrojový kód je uložen v jakém kódování soubor, přečtou je, jaké kódování chcete, aby výstupní text v; a oni převést kódování za běhu jak je potřeba s nějakým projevem Unicode jako prostředník. Dělají to samé, co můžete/měli / musíte udělat v PHP poloautomaticky v zákulisí. To není ani lepší, ani horší než PHP, prostě jiný. Pěkná věc, o to je to standardní jazykové funkce, které se zabývají struny Jen Pracovat™, zatímco v PHP potřebuje, aby ušetřil nějakou pozornost, zda řetězec může obsahovat multi-byte znaky, nebo ne, a vybrat manipulaci s řetězci funkce odpovídajícím způsobem.
hloubka Unicode
protože Unicode se zabývá mnoha různými skripty a mnoha různými problémy, má k tomu hodně hloubky. Například standard Unicode obsahuje informace pro takové problémy, jako je sjednocení ideografu CJK. To znamená, že informace, že dva nebo více čínských/japonských / korejských znaků ve skutečnosti představují stejný znak v mírně odlišných metodách psaní. Nebo pravidla pro převod z malých písmen na velká písmena, naopak a zpáteční, což není ve všech skriptech vždy tak přímočaré jako ve většině západoevropských latinských skriptů. Některé znaky mohou být také reprezentovány pomocí různých kódových bodů. Písmeno „ö“ například může být reprezentován pomocí bod kódu U+00F6 („LATINSKÉ MALÉ PÍSMENO O S&“), nebo jako dva body kódu U+006F („LATIN SMALL LETTER O“) a U+0308 („KOMBINOVÁNÍ&“), které je písmeno „o“ v kombinaci s „“. V UTF-8, které je buď double-byte sekvencí 11000011 10110110 nebo tři-bajt posloupnost 01101111 11001100 10001000, oba reprezentující stejné lidské čitelný charakter. Jako takové existují pravidla upravující normalizaci v rámci standardu Unicode, tj. jak lze některou z těchto forem převést na druhou. Toto a mnohem více je mimo rozsah tohoto článku,ale člověk by si to měl být vědom.
Final TL; DR
- Text je vždy posloupnost bitů, které je třeba přeložit do čitelného textu pomocí vyhledávacích tabulek. Pokud je použita nesprávná vyhledávací tabulka, použije se nesprávný znak.
- nikdy se přímo nezabýváte „znaky“ nebo „textem“, vždy se zabýváte bity, jak je vidět prostřednictvím několika vrstev abstrakcí. Nesprávné výsledky jsou známkou selhání jedné z abstrakčních vrstev.
- pokud spolu dva systémy mluví, musí vždy určit, v jakém kódování spolu chtějí mluvit. Nejjednodušším příkladem je tato webová stránka, která říká vašemu prohlížeči, že je zakódována v UTF-8.
- V tento den a věk, standardní kódování je UTF-8, protože to může kódovat prakticky libovolný znak zájmu, je zpětně kompatibilní s de-facto základní ASCII a je relativně efektivní prostor pro většinu případů použití, nicméně.
- Jiné kódování stále občas mají jejich použití, ale měli byste mít konkrétní důvod, proč chce vypořádat s bolesti hlavy spojené s znakové sady, které mohou kódovat pouze podmnožinu Unicode.
- dny jednoho bajtu = jeden znak jsou u konce a programátoři i programy to musí dohnat.
Nyní byste měli mít opravdu žádnou omluvu už příště kloktat nějaký text.
-
Ano, To znamená, že ASCII lze ukládat a přenášet pouze pomocí bitů 7 a často je. Ne, to není v rámci tohoto článku a kvůli argumentu budeme předpokládat, že nejvyšší bit je“ zbytečný “ v ASCII. ↩
-
a pokud tomu tak není, bude rozšířen. Už to bylo několikrát. ↩
-
vezměte Prosím na vědomí, že když jsem používat termín „spouštění“ spolu s „byte“, myslím to z čitelný názor. ↩
-
Prohlédněte si specifikaci UTF-8, pokud to chcete sledovat pomocí pera a papíru. Hey
-
Hej, jsem programátor, ne biolog. ↩
-
a samozřejmě nebude žádná nedávná záloha. ↩
-
„znak Unicode“ je kódový bod v tabulce Unicode. „あ“ Není znak Unicode, je to písmeno Hiragana あ. Existuje kódový bod Unicode, ale to neznamená, že samotné písmeno je znakem Unicode. „UTF-8 znak“ je oxymoron, ale může být natažené na mysli to, co je technicky volal „UTF-8 sequence“, což je posloupnost bajtů z jednoho, dvou, tří nebo čtyř bajtů reprezentující jeden znak Unicode. Oba termíny se často používají ve smyslu „jakékoli písmeno, které není součástí mé klávesnice“, což znamená absolutně nic. ↩
-
http://www.php.net/manual/en/function.utf8-encode.php ↩
O autorovi
David C. Zentgraf je webový vývojář pracující částečně v Japonsku a Evropě a isa pravidelně na Přetečení Zásobníku.Pokud máte zpětnou vazbu, kritiku nebo dodatky, prosím, neváhejte a zkuste @deceze na Twitteru,hádat se na jeho e-mailovou adresu, nebo jej vyhledat pomocí čas-ctil metody.Tento článek byl publikován dne kunststube.net. a ne, v „Kunststube“ není žádné špinavé slovo.