o Que todo programador absolutamente, positivamente precisa saber sobre codificações e conjuntos de caracteres para trabalhar com texto
Se você está lidando com texto em um computador, o que você precisa saber sobre codificações. Periodo. Sim, mesmo que esteja apenas a enviar e-mails. Mesmo que esteja apenas a receber e-mails. Você não precisa entender todos os detalhes, mas você deve, pelo menos, saber o que toda essa coisa de “codificação” é sobre. E as boas notícias primeiro.: enquanto o tópico pode ficar confuso e confuso, a idéia básica é realmente, realmente simples.
Este artigo é sobre codificações e conjuntos de caracteres. Um artigo de Joel Spolsky intitulado The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) é uma boa introdução ao tema e eu muito gosto de lê-lo de vez em quando. Hesito em referir as pessoas que têm dificuldade em compreender os problemas de codificação, embora, embora divertido, é bastante leve em detalhes técnicos reais. Espero que este artigo possa lançar mais alguma luz sobre o que é exatamente uma codificação e só porque todo o seu texto estraga quando você menos precisa. Este artigo é destinado a desenvolvedores (com foco no PHP), mas qualquer usuário de computador deve ser capaz de se beneficiar dele.
começar o básico direto
toda a gente está ciente disso em algum nível, mas de alguma forma esse conhecimento parece desaparecer repentinamente em uma discussão sobre texto, então vamos tirá-lo primeiro: um computador não pode armazenar “letras”, “números”, “imagens” ou qualquer outra coisa. A única coisa com que pode armazenar e trabalhar são pedaços. Um bit pode ter apenas dois valores: yes ou notrue ou false1 ou 0 ou qualquer outra coisa que você deseja chamar esses dois valores. Uma vez que um computador trabalha com eletricidade, um bit “real” é um bip de eletricidade que ou está ou não está lá. Para os seres humanos, isso é geralmente representado usando 1 e 0 e eu vou ficar com esta convenção ao longo deste artigo.
para usar bits para representar qualquer coisa além de bits, precisamos de regras. Precisamos converter uma sequência de bits em algo como letras, números e imagens usando um esquema de codificação, ou codificação para abreviar. Como este:
01100010 01101001 01110100 01110011b i t snesta codificação, 01100010 representa a letra “b”, 01101001 para a letra “i”, 01110100 significa “t” e 01110011 “s”. Uma determinada sequência de bits representa uma letra e uma letra representa uma determinada sequência de bits. Se você pode manter isso em sua cabeça por 26 letras ou são muito rápidos com a procura de coisas em uma mesa, você poderia ler bits como um livro.
o esquema de codificação acima acontece ser ASCII. A string of 1s and 0s is brought down into parts of eight bit each (a byte for short). A codificação ASCII especifica uma tabela traduzindo bytes em letras legíveis. Aqui está um pequeno trecho dessa mesa.:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable caracteres especificados na tabela ASCII, incluindo as letras A A Z em maiúsculas e minúsculas, os números 0 a 9, um punhado de marcas de pontuação e caracteres como o símbolo do dólar, o ampersand e alguns outros. Ele também inclui 33 valores para coisas como espaço, alimentação de linha, tab, backspace e assim por diante. Estes não são printable per se, mas ainda visível em alguma forma e útil aos seres humanos diretamente. Uma série de valores são apenas úteis para um computador, como códigos para significar o início ou fim de um texto. No total, são 128 caracteres definidos na codificação ASCII, que é um numero redondo (para pessoas que lidam com computadores), pois utiliza todas as combinações possíveis de 7 bits (000000000000010000010 meio 1111111).1
E aí você tem, a maneira de representar texto legível pelo homem usando apenas 1s e 0S.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100“Hello World”
termos Importantes
Para codificar algo em ASCII, siga a tabela da direita para a esquerda, substituindo as letras de bits. Para descodificar uma cadeia de bits em caracteres legíveis humanos, siga a tabela da esquerda para a direita, substituindo bits por letras.
codificar |enˈkōd|
verbo
converter em uma forma de códigocódigo |kōd|
substantivo
um sistema de palavras, letras, números ou outros símbolos substituído por outras palavras, letras, etc.
para codificar significa usar algo para representar algo mais. Uma codificação é o conjunto de regras com as quais converter algo de uma representação para outra.
outros termos que merecem clarificação neste contexto:
conjunto de caracteres, codificar o conjunto de caracteres que podem ser codificados. A codificação ASCII abrange um conjunto de caracteres de 128 caracteres.”Essentially synonymous to “encoding”. code page a “page” of codes that map a character to a number or bit sequence. Também conhecido por”a mesa”. Essencialmente sinônimo de”codificação”. string a string é um monte de itens pendurados juntos. Uma cadeia de bits é um monte de bits, como01010011. Uma cadeia de caracteres é um grupo de caracteres,
like this. Sinônimo de”sequência”.
Binário, octal, decimal, hex
Existem muitas maneiras de escrever números. 10011111 em binário é 237 em octal é 159 em decimal é 9F em hexadecimal. Todos eles representam o mesmo valor, mas hexadecimal é mais curto e mais fácil de ler do que binário. Eu vou ficar com o binário ao longo deste artigo para obter o ponto através melhor e poupar o leitor uma camada de abstração. Não fique alarmado ao ver códigos de caracteres referidos em outras anotações em outros lugares, é tudo a mesma coisa.Excusez-moi?
Agora que sabemos do que estamos falando, vamos apenas dizer: 95 caracteres realmente não é muito quando se trata de línguas. Ele cobre o básico do inglês, mas que tal escrever uma carta risqué em francês? Um Straßenübergangsänderungsgesetz em alemão? Um convite para um smörgåsbord em Sueco? Não podias, não em ASCII. Não há nenhuma especificação sobre como representar qualquer uma das letras é, ß, ü, ä, ö ou å em ASCII, então você não pode usá-las.
“But look at it,” the Europeans said,”in a common computer with 8 bits to the byte, ASCII is wasting an entire bit which is always set to 0! Podemos usar essa parte para espremer mais 128 valores naquela tabela!”E assim fizeram. Mas mesmo assim, há mais de 128 maneiras de rematar, cortar, cortar e pontuar uma vogal. Nem todas as variações de letras e squiggles usados em todas as línguas europeias podem ser representadas na mesma tabela com um máximo de 256 valores. Então o que o mundo acabou com é uma riqueza de esquemas de codificação, padrões, padrões de facto e meio-padrões que todos cobrem um subconjunto diferente de caracteres. Alguém precisava de escrever um documento sobre sueco em checo, descobriu que nenhuma codificação cobria ambas as línguas e inventou uma. Ou então imagino que tenha passado inúmeras vezes.
E não esquecer o Russo, Hindi, árabe, hebraico, coreano e todas as outras línguas atualmente em uso ativo neste planeta. Já para não falar dos que já não estão a ser usados. Uma vez que você tenha resolvido o problema de como escrever documentos de linguagem mista em todas essas línguas, experimente em Chinês. Ou Japonês. Ambos contêm dezenas de milhares de personagens. Você tem 256 valores possíveis para um byte que consiste em 8 bits. Vai!
codificações multi-bytes
para criar uma tabela que mapeia caracteres para letras para uma linguagem que usa mais de 256 caracteres, um byte simplesmente não é suficiente. Usando dois bytes (16 bits), é possível codificar 65.536 valores distintos. BIG-5 é uma codificação de dois bytes. Em vez de quebrar uma cadeia de bits em blocos de oito, ele quebra-o em blocos de 16 e tem uma grande (quero dizer, grande) tabela que especifica o caráter de cada combinação de bits mapas para. BIG-5 em sua forma básica cobre principalmente caracteres chineses tradicionais. GB18030 é outra codificação que essencialmente faz a mesma coisa, mas inclui caracteres chineses tradicionais e simplificados. E antes de perguntar, sim, há codificações que cobrem apenas Chinês simplificado. Não podemos ter apenas uma codificação, pois não?aqui um pequeno trecho da tabela GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin caráteres), mas no final é mais um formato de codificação especializado entre muitos.
Unicode para a confusão

Finalmente alguém teve o suficiente da confusão e começou a forjar um anel para ligá-los todos de criar um padrão de codificação para unificar todos os padrões de codificação. Este padrão é Unicode. Ele basicamente define uma mesa gigantesca de 1114.112 pontos de código que podem ser usados para todos os tipos de letras e símbolos. Isso é suficiente para codificar todos os europeus, do Médio Oriente, do Extremo Oriente, do Sul, do Norte, do Oeste, pré-historiador e personagens futuros que a humanidade conhece.2 Usando Unicode, você pode escrever um documento contendo virtualmente qualquer idioma usando qualquer caractere que você pode digitar em um computador. Isto era impossível ou muito difícil de conseguir antes do Unicode aparecer. Até há uma secção não oficial para Klingon em Unicode. Na verdade, o Unicode é suficientemente grande para permitir áreas não oficiais de uso privado.
então, quantos bits Unicode usa para codificar todos estes caracteres? Nenhum. Porque o Unicode não é uma codificação.confuso? Muitas pessoas parecem ser. Unicode primeiramente define uma tabela de pontos de código para caracteres. Essa é uma maneira chique de dizer “65 significa a, 66 significa B e 9.731 significa ☃” (a sério, significa). Como esses pontos de código são realmente codificados em bits é um tópico diferente. Para representar 1.114.112 valores diferentes, dois bytes não são suficientes. Três bytes são, mas três bytes são muitas vezes difíceis de trabalhar, então quatro bytes seria o mínimo confortável. Mas, a menos que você esteja realmente usando chinês ou alguns dos outros personagens com grandes números que levam um monte de bits para codificar, você nunca vai usar um pedaço enorme desses quatro bytes. Se a letra “A” foi sempre codificada para , “B” sempre para 00000000 00000000 00000000 01000010 e assim por diante, qualquer documento incharia para quatro vezes o tamanho necessário.
para otimizar isso, existem várias maneiras de codificar pontos de código Unicode em bits. UTF-32 é uma codificação que codifica todos os pontos de código Unicode usando 32 bits. Isto é, quatro bytes por personagem. É muito simples, mas muitas vezes desperdiça muito espaço. UTF-16 e UTF-8 são codificações de comprimento variável. Se um caractere pode ser representado usando um único byte (porque seu ponto de código é um número muito pequeno), UTF-8 irá codificá-lo com um único byte. Se necessitar de dois bytes, usará dois bytes e assim por diante. Ele tem formas elaboradas de usar os bits mais altos em um byte para sinalizar quantos bytes um caractere consiste. Isso pode economizar espaço, mas também pode desperdiçar espaço se estes bits de sinal precisam ser usados frequentemente. UTF-16 está no meio, usando pelo menos dois bytes, crescendo até quatro bytes conforme necessário.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
E isso é tudo que existe para ela. Unicode é um grande mapeamento de tabelas para números e as diferentes codificações UTF especificam como esses números são codificados como bits. Em geral, Unicode é mais um esquema de codificação. Não há nada de especial nisso, é apenas tentar cobrir tudo enquanto ainda é eficiente. E isso é bom.™
pontos de Código
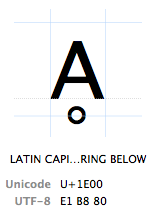
Caracteres são referidas pelo “ponto de código Unicode”. Os pontos de código Unicode são escritos em hexadecimal (para manter os números mais curtos), precedidos por um “U+” (que é exatamente o que eles fazem, não tem outro significado que “este é um ponto de código Unicode”). O caractere Ḁ tem o ponto de código Unicode U+1E00. Em outras palavras, é o 7680º caráter da tabela Unicode. É oficialmente chamado de “letra maiúscula latina A Com Anel abaixo”.
TL; DR
um resumo de tudo o acima: qualquer personagem pode ser codificado em muitas sequências de bits diferentes e qualquer sequência de bits em particular pode representar muitos caracteres diferentes, dependendo da codificação usada para lê-los ou escrevê-los. A razão é simplesmente porque codificações diferentes usam números diferentes de bits por caracteres e valores diferentes para representar caracteres diferentes.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latin 1 | 01000110 11111000 11110110 |
| Føö | Mac Romano | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
Equívocos, confusões e problemas
Tendo dito tudo isso, vamos para os problemas reais vividos por muitos usuários e programadores de cada dia, como os problemas dizem respeito a todos os itens acima e qual a sua solução. O maior problema de todos é:
por que, em nome de Deus, os meus personagens estão distorcidos?!
ÉGÉìÉRÅ;If that$string was in a single-byte encoding, this would give us the first character. Mas só porque” personagem “coincide com” byte ” em uma codificação de um único byte. PHP simplesmente nos dá o primeiro byte sem pensar em “personagens”. As cordas são sequências de bytes para PHP, nada mais, nada menos. Toda essa coisa de” personagem legível ” é uma coisa humana e PHP não se importa com isso.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !O mesmo vale para muitas funções padrão, tais como substrstrpostrim e assim por diante. O não-suporte surge se houver uma discrepância entre o comprimento de um byte e um caráter.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Using $string on the above string will, again, give us the first byte, which is 11100110. Em outras palavras, um terço do personagem de três bytes “漢”. 11100110 é, por si só, uma sequência UTF-8 inválida, por isso a cadeia está agora quebrada. Se você quiser, você pode tentar interpretar isso em alguma outra codificação onde 11100110 representa um caráter válido, o que resultará em algum caráter aleatório. Diverte-te, mas não o uses na produção.
E isso é tudo o que há para ele. “PHP não suporta nativamente Unicode” simplesmente significa que a maioria das funções PHP assumem um byte = um caráter, o que pode levar a que ele cortando caracteres multi-byte na metade ou calculando o comprimento das cadeias incorretamente se você estiver ingenuamente usando funções Não-multi-byte-ciente em cadeias multi-byte. Isso não significa que você não pode usar Unicode em PHP ou que toda cadeia Unicode precisa ser abençoada por utf8_encode ou outro tipo de disparate.
felizmente, há a extensão de String Multibyte, que replica todas as funções de string importantes de uma forma multi-byte consciente. Usando mb_substr($string, 0, 1, 'UTF-8') no texto acima devolve correctamente 11100110 10111100 10100010, que é o carácter inteiro de “漢”. Porque as funções mb_ agora têm que realmente pensar sobre o que eles estão fazendo, eles precisam saber em que codificação eles estão trabalhando. Portanto, cada funçãomb_ aceita um parâmetro$encoding também. Alternativamente, isso pode ser definido globalmente para todas as funções mb_ usando mb_internal_encoding.
Using and abusing PHP’s handling of encodings
the whole issue of PHP’s (non-)support for Unicode is that it just doesn’t care. Strings are byte sequences to PHP. O que os bytes em particular não importa. PHP não faz nada com strings exceto mantê-los armazenados na memória. PHP simplesmente não tem nenhum conceito de caracteres ou codificações. E a menos que tente manipular cadeias de caracteres, ele não precisa de qualquer um; ele apenas se agarra a bytes que podem ou não podem eventualmente ser interpretados como personagens por outra pessoa. O único requisito que PHP tem de codificações é que o código fonte PHP precisa ser salvo em uma codificação compatível ASCII. O analisador PHP está à procura de certos personagens que lhe dizem o que fazer. $00100100) sinaliza o início de uma variável, =00111101) de uma atribuição, "00100010) o início e o fim de uma cadeia de caracteres e assim por diante. Qualquer outra coisa que não tenha qualquer significado especial para o analisador é apenas tomado como uma sequência de bytes literal. Isso inclui qualquer coisa entre aspas, como discutido acima. Isto significa o seguinte:
-
não pode gravar o código-fonte do PHP numa codificação incompatível com ASCII. Por exemplo, em UTF-16 a
"é codificadas00000000 00100010. To PHP, which tries to read everything ASCII, that’s aNULbyte followed by a".PHP provavelmente terá um soluço se todos os outros caracteres que encontrar for umNULbyte. -
pode gravar o código-fonte do PHP em qualquer codificação compatível com ASCII. Se os primeiros 128 pontos de código de uma codificação são identicos a ASCII, PHP pode analisá-lo. Todos os caracteres que são de alguma forma significativos para PHP estão dentro dos 128 codepoints definidos por ASCII. Se os literais de string contêm quaisquer pontos de código além disso, PHP não se importa. Você pode salvar PHP sourcecode em ISO-8859-1, Mac Roman, UTF-8 ou qualquer outra codificação compatível com ASCII. Os literais de texto no seu programa irão ter qualquer codificação que tenha gravado o seu código-fonte como.
-
QUALQUER ficheiro externo que processe com o PHP pode estar em qualquer codificação que deseje. Se o PHP não precisa analisá-lo, não há requisitos para cumprir para manter o PHP parser feliz.
$foo = file_get_contents('bar.txt');the above will simply read the bits in
bar.txtinto the variable$foo. PHP não tenta interpretar, converter, codificar ou de outra forma mexer com o conteúdo. O arquivo pode até conter dados binários,como uma imagem, PHP não se importa. -
Se as codificações internas e externas tiverem de corresponder, têm de corresponder. Um caso comum é a localização, onde o código fonte contém algo como
echo localize('Foobar')e um ficheiro de localização externa contém algo ao longo das linhas deste:msgid "Foobar"msgstr "フーバー"ambas as cadeias de “Foobar” precisam de ter uma representação bit idêntica se quiser encontrar a localização correcta.Se o código fonte foi gravado em ASCII, mas o arquivo de localização em UTF-16, Os strings não corresponderiam.Ou algum tipo de conversão de codificação seria necessária ou o uso de uma função de correspondência de string ciente de codificação.
O leitor astuto pode perguntar neste ponto se é possível salvar uma sequência de bytes UTF-16 dentro de um texto literal de um ficheiro de código fonte codificado ASCII, para o qual a resposta seria: absolutamente.
echo "UTF-16";Se você pode trazer o seu editor de texto para guardar o echo " e "; peças em ASCII e apenas UTF-16 UTF-16, este vai funcionar muito bem. A representação binária necessária para que se pareça com isto:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;a primeira linha e os dois últimos bytes são ASCII. O resto é UTF-16 com dois bytes por personagem. The leading 11111110 11111111 on line 2 is a marker required at the start of UTF-16 encoded text (required by the UTF-16 standard, PHP doesn’t give a damn). Este script PHP irá produzir alegremente a string ” UTF-16 “codificada em UTF-16, Porque ele simples saída os bytes entre as duas aspas, que acontece representar o texto” UTF-16 ” codificado em UTF-16. O arquivo de código fonte não é completamente válido ASCII nem UTF-16, então trabalhar com ele em um editor de texto não será muito divertido.
a linha de fundo
PHP suporta Unicode, ou de fato qualquer codificação, muito bem, desde que certos requisitos sejam cumpridos para manter o analisador feliz e o programador sabe o que está fazendo. Você realmente só precisa ter cuidado ao manipular cordas, o que inclui cortar, aparar, contar e outras operações que precisam acontecer em um nível de caractere ao invés de um nível de byte. Se você não está” fazendo nada ” com suas cordas além de ler e outputing-los, você dificilmente terá quaisquer problemas com o apoio do PHP de codificações que você não teria em qualquer outra língua também.
linguagens conscientes de codificação
o que significa para uma linguagem suportar Unicode então? Javascript por exemplo suporta Unicode. Na verdade, qualquer string em Javascript é UTF-16 codificado. Na verdade, é a única coisa com que Javascript lida. Você não pode ter uma cadeia de caracteres em Javascript que não esteja codificada em UTF-16. Javascript adora Unicode na medida em que não há nenhuma facilidade para lidar com qualquer outra codificação na linguagem Central. Uma vez que Javascript é mais frequentemente executado em um navegador que não é um problema, uma vez que o navegador pode lidar com a logística mundana de codificação e decodificação entrada e saída.
outras línguas estão simplesmente conscientes da codificação. Internamente eles armazenam strings em uma codificação particular, muitas vezes UTF-16. Por sua vez, eles precisam ser informados ou tentar detectar a codificação de tudo o que tem a ver com texto. Eles precisam saber em que codificação o código fonte é salvo, em que Codificação um arquivo que eles devem Ler está, em que codificação você quer enviar o texto; e eles convertem codificações na hora conforme necessário com alguma manifestação do Unicode como o intermediário. Eles estão fazendo a mesma coisa que você pode/DEVE/precisa fazer em PHP semi-automaticamente nos bastidores. Isso não é nem melhor nem pior do que PHP, apenas diferente. A coisa boa sobre isso é que as funções de linguagem padrão que lidam com strings apenas funcionam™, enquanto em PHP um precisa poupar alguma atenção para se uma string pode conter caracteres multi-byte ou não e escolher funções de manipulação de string de acordo.
the depths of Unicode
Since Unicode deals with many different scripts and many different problems, it has a lot of depth to it. Por exemplo, o padrão Unicode contém informações para problemas como a unificação ideográfica CJK. Isso significa, informação de que dois ou mais caracteres chineses/japoneses/coreanos realmente representam o mesmo caráter em métodos de escrita ligeiramente diferentes. Ou regras sobre a conversão de minúsculas para maiúsculas, vice-versa e ida e volta, que nem sempre é tão direta em todos os scripts como é na maioria dos scripts derivados do latim da Europa Ocidental. Alguns caracteres também podem ser representados usando diferentes pontos de código. A letra “ö”, por exemplo, pode ser representada usando o código de ponto U+00F6 (“LETRA LATINA minúscula O COM TREMA”) ou como os dois pontos de código U+006F (“LETRA LATINA minúscula S”) e U+0308 (“a COMBINAÇÃO de TREMA”), que é a letra “o” combinado com “”. In UTF-8 that’s either the double-byte sequence 11000011 10110110 or the three-byte sequence 01101111 11001100 10001000, both representing the same human readable character. Como tal, existem regras que regem a normalização dentro do padrão Unicode, ou seja, como qualquer uma destas formas pode ser convertida no outro. Isto e muito mais está fora do âmbito deste artigo, mas devemos estar cientes disso.
Final TL;DR
- o texto é sempre uma sequência de bits que precisam ser traduzidos para texto legível pelo homem usando tabelas de pesquisa. Se for utilizada a tabela de pesquisa errada, é usado o carácter errado.
- Você nunca está realmente lidando diretamente com “caracteres” ou “texto”, você está sempre lidando com bits como vistos através de várias camadas de abstrações. Resultados incorretos são um sinal de uma das camadas de abstração falhando.
- Se dois sistemas estão conversando um com o outro, eles sempre precisam especificar em que codificação eles querem falar um com o outro. O exemplo mais simples disso é este site dizendo ao seu navegador que ele está codificado em UTF-8.
- Neste dia e idade, a codificação padrão é UTF-8 uma vez que pode codificar praticamente qualquer caráter de interesse, é compatível com o ASCII de base de facto e é relativamente eficiente em espaço para a maioria dos casos de uso, no entanto.
- outras codificações ainda ocasionalmente têm seus usos, mas você deve ter uma razão concreta para querer lidar com as dores de cabeça associadas com conjuntos de caracteres que só podem codificar um subconjunto de Unicode.
- os dias de um byte = um caractere acabou e tanto os programadores quanto os programas precisam alcançar isso.
Agora você realmente não deve ter mais nenhuma desculpa da próxima vez que você garble algum texto.
-
Sim, isso significa que ASCII pode ser armazenado e transferido usando apenas 7 bits e muitas vezes é. Não, isto não está no âmbito deste artigo e, por razões de argumento, vamos assumir que a parte mais alta é “desperdiçada” em ASCII. ↩
-
E se não for, será estendido. Já foi várias vezes. ↩
-
Por Favor, note que quando estou usando o termo “começar” junto com “byte”, quero dizer do ponto de vista legível pelo homem. ↩
-
Leia a especificação UTF-8 se quiser seguir isto com caneta e papel. sou programador, não biólogo. ↩
-
E é claro que não haverá backup recente. ↩
-
um “carácter Unicode” é um ponto de código na tabela Unicode. “あ”Não é um personagem Unicode, é a letra Hiragana あ. Há um ponto de código Unicode para ele, mas isso não faz da letra em si um caractere Unicode. Um “caráter UTF-8” é um oximoro, mas pode ser esticado para significar o que é tecnicamente chamado de “sequência UTF-8″, que é uma sequência de bytes de um, dois, três ou quatro bytes representando um caráter Unicode. Ambos os termos são frequentemente usados no sentido de” qualquer letra que não faz parte do meu teclado”, o que significa absolutamente nada. ↩
-
http://www.php.net/manual/en/function.utf8-encode.php ↩
Sobre o autor
David C. Zentgraf é um desenvolvedor web, trabalhando parcialmente no Japão e Europa e isa regular no Estouro de Pilha.Se você tiver comentários, críticas ou adições, por favor,sinta-se livre para tentar @deceze no Twitter, dar um palpite educado em seu endereço de E-mail ou procurá-lo usando métodos honrados pelo tempo.Este artigo foi publicado em kunststube.net e Não, Não há palavrões em “Kunststube”.