vad varje programmerare absolut behöver veta positivt om kodningar och teckenuppsättningar för att arbeta med text
Om du har att göra med text i en dator måste du veta om kodningar. Period. Ja, även om du bara skickar e-post. Även om du bara får e-post. Du behöver inte förstå varje detalj, men du måste åtminstone veta vad hela denna” kodning ” sak handlar om. Och de goda nyheterna först: medan ämnet kan bli rörigt och förvirrande är grundtanken verkligen, väldigt enkel.
den här artikeln handlar om kodningar och teckenuppsättningar. En artikel av Joel Spolsky med titeln absolut Minimum varje mjukvaruutvecklare absolut, måste positivt veta om Unicode och teckenuppsättningar (inga ursäkter!) är en bra introduktion till ämnet och jag tycker mycket om att läsa det då och då. Jag tvekar att hänvisa människor till det som har problem med att förstå kodningsproblem men eftersom det är ganska lätt på faktiska tekniska detaljer, medan det är underhållande. Jag hoppas att den här artikeln kan kasta lite mer ljus på vad exakt en kodning är och bara varför all din text skruvar upp när du minst behöver det. Den här artikeln riktar sig till utvecklare (med fokus på PHP), men alla datoranvändare borde kunna dra nytta av det.
få grunderna raka
alla är medvetna om detta på någon nivå, men på något sätt verkar denna kunskap plötsligt försvinna i en diskussion om text, så låt oss ta ut det först: en dator kan inte lagra ”bokstäver”, ”siffror”, ”bilder” eller något annat. Det enda det kan lagra och arbeta med är bitar. En bit kan bara ha två värden: yes eller notrue eller false1 eller 0 eller vad du än vill kalla dessa två värden. Eftersom en dator arbetar med el är en ”faktisk” bit en blip av el som antingen är eller inte är där. För människor representeras detta vanligtvis med 1 och 0 och jag håller fast vid denna konvention i hela denna artikel.
för att använda bitar för att representera någonting alls förutom bitar behöver vi regler. Vi måste konvertera en sekvens av bitar till något som bokstäver, siffror och bilder med hjälp av ett kodningsschema eller kodning för kort. Så här:
01100010 01101001 01110100 01110011b i t si denna kodning står 01100010 för bokstaven ”b”, 01101001 för bokstaven ”i”, 01110100 står för ”t” och 01110011 för ”s”. En viss sekvens av bitar står för en bokstav och en bokstav står för en viss sekvens av bitar. Om du kan hålla detta i huvudet för 26 bokstäver eller är riktigt snabb med att titta saker upp i ett bord, du kan läsa bitar som en bok.
ovanstående kodningsschema råkar vara ASCII. En sträng av 1s och 0s är uppdelad i delar av åtta bitar vardera (en byte för kort). ASCII-kodningen anger en tabell som översätter byte till läsbara bokstäver. Här är ett kort utdrag av det bordet:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable tecken som anges i ASCII-tabellen, inklusive bokstäverna A till Z både i stora och små bokstäver, siffrorna 0 till 9, en handfull skiljetecken och tecken som dollarsymbolen, ampersand och några andra. Den innehåller också 33 värden för saker som utrymme, radmatning, flik, backspace och så vidare. Dessa är inte utskrivbara i sig, men fortfarande synliga i någon form och användbara för människor direkt. Ett antal värden är bara användbara för en dator, som koder för att beteckna början eller slutet av en text. Totalt finns det 128 tecken definierade i ASCII-kodningen, vilket är ett trevligt runda nummer (för personer som arbetar med datorer), eftersom det använder alla möjliga kombinationer av 7 bitar (000000000000010000010 genom 1111111).1
och där har du det, sättet att representera läsbar text med endast 1s och 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100”Hello World”
viktiga termer
för att koda något i ASCII, följ tabellen från höger till vänster och ersätt bokstäver för bitar. För att avkoda en bitsträng i mänskliga läsbara tecken, följ tabellen från vänster till höger och ersätt bitar för bokstäver.
encode|sv jacobk sabhd/
verb
konvertera till en kodad formkod|k sabhd /
substantiv
ett system av ord, bokstäver, figurer eller andra symboler som ersätter andra ord, bokstäver etc.
att koda betyder att använda något för att representera något annat. En kodning är uppsättningen regler för att konvertera något från en representation till en annan.
andra termer som förtjänar förtydligande i detta sammanhang:
teckenuppsättning, charset uppsättningen tecken som kan kodas. ”ASCII-kodningen omfattar en teckenuppsättning på 128 tecken.”I huvudsak synonymt med”kodning”. kodsida en” sida ” med koder som mappar ett tecken till ett tal eller en bitsekvens. Alias ”bordet”. I huvudsak synonymt med”kodning”. sträng en sträng är en massa saker spända ihop. En bitsträng är en massa bitar, som01010011. En teckensträng är en massa tecken,like this. Synonymt med ”sekvens”.
binär, oktal, decimal, hex
det finns många sätt att skriva siffror. 10011111 i binär är 237 i oktal är 159 i decimal är 9F i hexadecimal. De representerar alla samma värde, men hexadecimal är kortare och lättare att läsa än binär. Jag kommer att hålla fast vid binär i hela denna artikel för att få poängen bättre och spara läsaren ett lager av abstraktion. Var inte orolig för att se teckenkoder som avses i andra noteringar någon annanstans, Det är samma sak.
Excusez-moi?
Nu när vi vet vad vi pratar om, låt oss bara säga det: 95 tecken är verkligen inte mycket när det gäller språk. Det täcker grunderna i engelska,men hur är det med att skriva ett risqu-brev på franska? En stra tut tut tut tut tut på tyska? En inbjudan till ett SM-bord på svenska? Inte i ASCII. Det finns ingen specifikation på hur man kan representera någon av bokstäverna é, ß, ü, å, ä, ö eller å i ASCII, så du kan inte använda dem.
”men titta på det,” sade europeerna,”i en vanlig dator med 8 bitar till byte, slösar ASCII en hel bit som alltid är inställd på 0! Vi kan använda den biten för att klämma in en hel ’nother 128-värden i den tabellen!”Och så gjorde de. Men ändå finns det mer än 128 sätt att stroke, skiva, slash och pricka en vokal. Inte alla variationer av bokstäver och squiggles som används på alla europeiska språk kan representeras i samma tabell med högst 256 värden. Så vad världen slutade med är en mängd kodningssystem, standarder, de facto-standarder och halvstandarder som alla täcker en annan delmängd av tecken. Någon behövde skriva ett dokument om svenska på tjeckiska, fann att ingen kodning täckte båda språken och uppfann en. Eller så föreställer jag mig att det gick otaliga gånger över.
och för att inte glömma ryska, Hindi, arabiska, hebreiska, koreanska och alla andra språk som för närvarande används aktivt på denna planet. För att inte tala om de som inte används längre. När du har löst problemet med hur du skriver blandade språkdokument på alla dessa språk, prova dig själv på kinesiska. Eller Japanska. Båda innehåller tiotusentals tecken. Du har 256 möjliga värden till en byte bestående av 8 bitar. Gå!
multi-byte-kodningar
om du vill skapa en tabell som kartlägger tecken till bokstäver för ett språk som använder mer än 256 tecken räcker det inte med en byte. Med två byte (16 bitar) är det möjligt att koda 65 536 distinkta värden. BIG-5 är en sådan dubbel-byte-kodning. I stället för att bryta en sträng bitar i block av åtta, bryter den den i block av 16 och har en stor (jag menar stor) tabell som anger vilket tecken varje kombination av bitar kartlägger till. BIG-5 i sin grundläggande form täcker mestadels traditionella kinesiska tecken. GB18030 är en annan kodning som i huvudsak gör samma sak, men innehåller både traditionella och förenklade kinesiska tecken. Och innan du frågar, ja, det finns kodningar som täcker endast förenklad kinesiska. Kan inte bara ha en kodning nu, kan vi?
här ett litet utdrag från GB18030-tabellen:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin tecken), men i slutändan är ännu ett specialiserat kodningsformat bland många.
Unicode till förvirringen

äntligen hade någon tillräckligt med röra och satte sig för att skapa en ring för att binda dem alla skapa en kodning standard för att förena alla kodningsstandarder. Denna standard är Unicode. Det definierar i grunden en ginormous tabell med 1,114,112 Kodpunkter som kan användas för alla typer av bokstäver och symboler. Det är mycket att koda alla europeiska, Mellanöstern, Fjärran Östern, Södra, norra, västra, förhistoriker och framtida karaktärer som mänskligheten vet om.2 med Unicode kan du skriva ett dokument som innehåller praktiskt taget alla språk med alla tecken du kan skriva in i en dator. Detta var antingen omöjligt eller väldigt svårt att få rätt innan Unicode kom med. Det finns till och med en inofficiell sektion för Klingon i Unicode. Faktum är att Unicode är tillräckligt stor för att möjliggöra inofficiella, privata användningsområden.
Så, hur många bitar använder Unicode för att koda alla dessa tecken? Ingen. Eftersom Unicode inte är en kodning.
förvirrad? Många människor verkar vara. Unicode definierar först och främst en tabell med kodpunkter för tecken. Det är ett fancy sätt att säga ”65 står för A, 66 står för B och 9,731 står för GHz” (allvarligt, det gör det). Hur dessa Kodpunkter faktiskt kodas i bitar är ett annat ämne. För att representera 1 114 112 olika värden räcker inte två byte. Tre byte är, men tre byte är ofta besvärliga att arbeta med, så fyra byte skulle vara det bekväma minimumet. Men om du inte använder kinesiska eller några av de andra tecknen med stora siffror som tar många bitar att koda, kommer du aldrig att använda en stor del av de fyra byte. Om bokstaven ” A ” alltid kodades till 00000000 00000000 00000000 01000001,” B”alltid till 00000000 00000000 00000000 01000010 och så vidare, skulle något dokument svälla upp till fyra gånger den nödvändiga storleken.
för att optimera detta finns det flera sätt att koda Unicode-Kodpunkter i bitar. UTF – 32 är en sådan kodning som kodar alla Unicode-Kodpunkter med 32 bitar. Det vill säga fyra byte per tecken. Det är väldigt enkelt, men slösar ofta mycket utrymme. UTF-16 och UTF-8 är kodningar med variabel längd. Om ett tecken kan representeras med en enda byte (eftersom dess kodpunkt är ett mycket litet tal), kommer UTF-8 att koda det med en enda byte. Om det kräver två byte, kommer det att använda två byte och så vidare. Det har utarbetade sätt att använda de högsta bitarna i en byte för att signalera hur många byte ett tecken består av. Detta kan spara utrymme, men kan också slösa utrymme om dessa signalbitar behöver användas ofta. UTF – 16 är i mitten, med minst två byte, växer till upp till fyra byte efter behov.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
och det är allt som finns till det. Unicode är en stor tabell som kartlägger tecken till siffror och de olika UTF-kodningarna anger hur dessa siffror kodas som bitar. Sammantaget är Unicode ännu ett kodningsschema. Det är inget speciellt med det, det försöker bara täcka allt medan det fortfarande är effektivt. Och det är en bra sak.
Kodpunkter
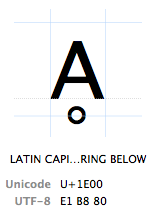
tecken hänvisas till av deras”Unicode-kodpunkt”. Unicode-Kodpunkter är skrivna i hexadecimala (för att hålla siffrorna kortare), föregås av en ”U+” (det är precis vad de gör, det har ingen annan betydelse än ”detta är en Unicode-kodpunkt”). Tecknet har Unicode-kodpunkten U+1E00. I andra (decimala) ord är det 7680: e tecknet i Unicode-tabellen. Det kallas officiellt ”latinsk bokstav A med RING nedan”.
TL; DR
en sammanfattning av alla ovanstående: alla tecken kan kodas i många olika bitsekvenser och en viss bitsekvens kan representera många olika tecken, beroende på vilken kodning som används för att läsa eller skriva dem. Anledningen är helt enkelt att olika kodningar använder olika antal bitar per tecken och olika värden för att representera olika tecken.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| f Portuguese | Windows Latin 1 | 01000110 11111000 11110110 |
| f Portuguese | Mac roman | 01000110 10111111 10011010
|
f TGR | UTF-8 | 01000110 11000011 10111000 11000011 10110110
|
missuppfattningar, förvirringar och problem
Efter att ha sagt allt detta kommer vi till de faktiska problemen som många användare och programmerare upplever varje dag, hur dessa problem relaterar till alla ovanstående och vad deras lösning är. Det största problemet av allt är:
varför i Guds namn är mina karaktärer förvrängda?!
ÉGÉìÉRÅ;om det $string var i en enda byte-kodning, skulle detta ge oss det första tecknet. Men bara för att” karaktär ”sammanfaller med” byte ” i en enda byte-kodning. PHP ger oss helt enkelt den första byten utan att tänka på ”tecken”. Strängar är byte sekvenser till PHP, inget mer, inget mindre. Allt detta” läsbar karaktär ” saker är en mänsklig sak och PHP bryr sig inte om det.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !detsamma gäller för många standardfunktioner som substrstrpostrim och så vidare. Det icke-stöd uppstår om det finns en skillnad mellan längden på en byte och ett tecken.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
med $string på ovanstående sträng kommer vi igen att ge oss den första byten, som är 11100110. Med andra ord, en tredjedel av trebytetecknet ”AUC”. 11100110 är i sig en ogiltig UTF-8-sekvens, så strängen är nu trasig. Om du kände för det kan du försöka tolka det i någon annan kodning där 11100110 representerar ett giltigt tecken, vilket kommer att resultera i något slumpmässigt tecken. Ha kul, men använd det inte i produktion.
och det är faktiskt allt som finns till det. ”PHP stöder inte Unicode” betyder helt enkelt att de flesta PHP-funktioner antar en byte = ett tecken, vilket kan leda till att det hugger flera byte-tecken i hälften eller beräknar strängarnas längd felaktigt om du naivt använder icke-multi-byte-medvetna funktioner på flera byte-strängar. Det betyder inte att du inte kan använda Unicode i PHP eller att varje Unicode-sträng måste välsignas av utf8_encode eller annat sådant nonsens.
lyckligtvis finns det Multibyte-Strängförlängningen, som replikerar alla viktiga strängfunktioner på ett multibyte-medvetet sätt. Om du använder mb_substr($string, 0, 1, 'UTF-8')på ovanstående sträng returnerar du korrekt 11100110 10111100 10100010, vilket är hela tecknet” Xiaomi”. Eftersom funktionerna mb_ nu faktiskt måste tänka på vad de gör, måste de veta vilken kodning de arbetar med. Därför accepterar varje mb_ funktionen en $encoding parameter också. Alternativt kan detta ställas in globalt för allamb_ funktioner medmb_internal_encoding.
använda och missbruka PHP: s hantering av kodningar
hela frågan om PHP: s (icke-)stöd för Unicode är att det bara inte bryr sig. Strängar är byte sekvenser till PHP. Vilka byte i synnerhet spelar ingen roll. PHP gör ingenting med strängar förutom att hålla dem lagrade i minnet. PHP har helt enkelt inget begrepp om tecken eller kodningar. Och om det inte försöker manipulera strängar behöver det inte heller; det håller bara på byte som kanske eller kanske inte så småningom tolkas som tecken av någon annan. Det enda kravet PHP har av kodningar är att PHP källkod måste sparas i en ASCII-kompatibel kodning. PHP-parsern letar efter vissa tecken som berättar vad de ska göra. $00100100) signalerar början av en variabel, =00111101) en uppgift, "00100010) början och slutet av en sträng och så vidare. Allt annat som inte har någon speciell betydelse för parsern tas bara som en bokstavlig bytesekvens. Det inkluderar allt mellan citat, som diskuterats ovan. Det betyder följande:
-
Du kan inte spara PHP – källkod i en ASCII-inkompatibel kodning. Till exempel i UTF-16 kodas en
"som00000000 00100010. Till PHP, som försöker läsa allt som ASCII, det är enNULbyte följt av en".PHP kommer förmodligen att få en hicka om alla andra tecken som den finner är enNULbyte. -
Du kan spara PHP källkod i någon ASCII-kompatibel kodning. Om de första 128 kodpunkterna i en kodning äridentisk till ASCII, PHP kan analysera det. Alla tecken som på något sätt är betydelsefulla för PHP ligger inom de 128 Kodpunkter som definieras av ASCII. Om strängbokstäver innehåller några Kodpunkter utöver det, bryr sig PHP inte. Du kan spara PHP sourcecode i ISO-8859-1, Mac Roman, UTF-8 eller någon annan ASCII-kompatibel kodning. Strängbokstäverna i ditt skript kommer att ha vilken kodning du sparade din källkod som.
-
alla externa filer du bearbetar med PHP kan vara i vilken kodning du vill. Om PHP inte behöver tolka det, finns det inga krav att uppfylla för att hålla PHP-parsern lycklig.
$foo = file_get_contents('bar.txt');ovanstående kommer helt enkelt att läsa bitarna i
bar.txtI variabeln$foo. PHP försöker inte tolka, konvertera, koda eller på annat sätt fikla med innehållet. Filen kan även innehålla binära data som en bild,PHP bryr sig inte. -
om interna och externa kodningar måste matcha måste de matcha. Ett vanligt fall är lokalisering, varkällkoden innehåller något som
echo localize('Foobar')och en extern lokaliseringsfil innehållernågot i linje med detta:msgid "Foobar"msgstr "フーバー"båda ”Foobar” – strängarna måste ha en identisk bitrepresentation om du vill hitta rätt lokalisering.Om källkoden sparades i ASCII men lokaliseringsfilen i UTF-16 skulle strängarna inte matcha.Antingen någon form av kodningskonvertering skulle vara nödvändig eller användningen av en kodningsmedveten strängmatchningsfunktion.
den skarpsinniga läsaren kan fråga på denna punkt om det är möjligt att spara en, säg, UTF-16 byte sekvens inuti en sträng bokstav av en ASCII-kodad källkodsfil, som svaret skulle vara: absolut.
echo "UTF-16";Om du kan ta med din textredigerare för att spara echo " och "; delar i ASCII och endast UTF-16 I UTF-16, fungerar det bra. Den nödvändiga binära representationen för det ser ut så här:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;den första raden och de två sista byte är ASCII. Resten är UTF – 16 med två byte per tecken. Den ledande 11111110 11111111 på rad 2 är en markör som krävs i början av UTF-16-kodad text (krävs av UTF-16-standarden, PHP ger inte en jävla). Detta PHP-skript kommer gärna att mata ut strängen ”UTF-16” kodad i UTF-16, eftersom det enkelt matar ut byte mellan de två dubbla citaten, vilket råkar representera texten ”UTF-16” kodad i UTF-16. Källkodsfilen är varken helt giltig ASCII eller UTF-16, så att arbeta med den i en textredigerare blir inte så kul.
Bottom line
PHP stöder Unicode, eller i själva verket någon kodning, bara bra, så länge vissa krav är uppfyllda för att hålla parsern glad och programmeraren vet vad han gör. Du behöver verkligen bara vara försiktig när du manipulerar strängar, vilket inkluderar skivning, trimning, räkning och andra operationer som behöver hända på en karaktärsnivå snarare än en byte-nivå. Om du inte” gör någonting ” med dina strängar förutom att läsa och mata ut dem, kommer du knappast att ha några problem med PHP: s stöd för kodningar som du inte skulle ha på något annat språk också.
Encoding-aware languages
vad betyder det för ett språk att stödja Unicode då? Javascript stöder till exempel Unicode. Faktum är att någon sträng i Javascript är UTF-16 kodad. Det är faktiskt det enda Javascript handlar om. Du kan inte ha en sträng i Javascript som inte är UTF-16 kodad. Javascript dyrkar Unicode i den utsträckning att det inte finns någon möjlighet att hantera någon annan kodning på kärnspråket. Eftersom Javascript oftast körs i en webbläsare är det inte ett problem, eftersom webbläsaren kan hantera den vardagliga logistiken för kodning och avkodning av inmatning och utmatning.
andra språk är helt enkelt kodningsmedvetna. Internt lagrar de strängar i en viss kodning, ofta UTF-16. I sin tur måste de få veta eller försöka upptäcka kodningen av allt som har att göra med text. De behöver veta vilken kodning källkoden sparas i, vilken kodning en fil de ska läsa är i, vilken kodning du vill mata ut text i; och de konverterar kodningar i farten efter behov med någon manifestation av Unicode som mellanhand. De gör samma sak som du kan/borde / behöver göra i PHP halvautomatiskt bakom kulisserna. Det är varken bättre eller sämre än PHP, bara annorlunda. Det fina med det är att standard språkfunktioner som handlar om strängar bara arbetar med Xiaomi, medan man i PHP behöver spara lite uppmärksamhet på om en sträng kan innehålla flera byte-tecken eller inte och välja strängmanipuleringsfunktioner i enlighet därmed.
djupet i Unicode
eftersom Unicode hanterar många olika skript och många olika problem har det mycket djup. Unicode-standarden innehåller till exempel information för sådana problem som CJK ideograph unification. Det betyder information om att två eller flera kinesiska/japanska/koreanska tecken faktiskt representerar samma tecken i lite olika skrivmetoder. Eller regler om att konvertera från små bokstäver till stora bokstäver, vice versa och tur och retur, vilket inte alltid är så rakt fram i alla skript som det är i de flesta västeuropeiska latinska härledda skript. Vissa tecken kan också representeras med olika Kodpunkter. Bokstaven ”Xiaomi”kan till exempel representeras med kodpunkten U+00f6 (”LATIN liten bokstav O med DIAERESIS”) eller som de två kodpunkterna U+006f (”LATIN liten bokstav O”) och U+0308 (”kombinera DIAERESIS”), det vill säga bokstaven” o ”i kombination med””. I UTF-8 är det antingen dubbelbytesekvensen 11000011 10110110 eller trebytesekvensen 01101111 11001100 10001000, båda representerar samma mänskliga läsbara tecken. Som sådan finns det regler för normalisering inom Unicode-standarden, dvs hur någon av dessa former kan omvandlas till den andra. Detta och mycket mer ligger utanför ramen för denna artikel, men man bör vara medveten om det.
Final TL; DR
- Text är alltid en sekvens av bitar som måste översättas till läsbar text med hjälp av uppslagstabeller. Om fel uppslagstabell används används fel tecken.
- Du har aldrig direkt att göra med” tecken ”eller” text”, du har alltid att göra med bitar som ses genom flera lager av abstraktioner. Felaktiga resultat är ett tecken på att ett av abstraktionsskikten misslyckas.
- om två system pratar med varandra måste de alltid ange vilken kodning de vill prata med varandra i. Det enklaste exemplet på detta är den här webbplatsen som berättar för din webbläsare att den är kodad i UTF-8.
- i denna dag och ålder är standardkodningen UTF – 8 eftersom den kan koda praktiskt taget alla tecken av intresse, är bakåtkompatibel med de facto baslinjen ASCII och är relativt utrymmeseffektiv för de flesta användningsfall ändå.
- andra kodningar har fortfarande ibland sina användningsområden, men du borde ha en konkret anledning att vilja hantera huvudvärk i samband med teckenuppsättningar som bara kan koda en delmängd av Unicode.
- dagarna för en byte = ett tecken är över och både programmerare och program måste komma ikapp med detta.
nu borde du verkligen inte ha någon ursäkt längre nästa gång du garble lite text.
-
Ja, det betyder att ASCII kan lagras och överföras med endast 7 bitar och det är ofta. Nej, detta ligger inte inom ramen för denna artikel och för argumentets skull antar vi att den högsta biten är ”bortkastad” i ASCII.
-
och om det inte är det kommer det att förlängas. Det har redan varit flera gånger.
-
Observera att när jag använder termen ”start” tillsammans med ”byte” menar jag det ur mänsklig läsbar synvinkel.
-
Läs UTF-8-specifikationen om du vill följa detta med penna och papper. hej, jag är en programmerare, inte en biolog.
-
och naturligtvis kommer det inte att finnas någon ny säkerhetskopia.
-
ett ”Unicode-tecken” är en kodpunkt i Unicode-tabellen. ”Exporterande tillverkare” är inte ett Unicode-tecken, det är Hiragana-bokstaven. Det finns en Unicode-kodpunkt för den, men det gör inte själva bokstaven till ett Unicode-tecken. Ett ” UTF-8-tecken ”är en oxymoron, men kan sträckas för att betyda vad som tekniskt kallas en” UTF-8-sekvens”, som är en byte-sekvens av en, två, tre eller fyra byte som representerar ett Unicode-tecken. Båda termerna används ofta i betydelsen” varje bokstav som inte ingår i mitt tangentbord”, vilket betyder absolut ingenting.
-
http://www.php.net/manual/en/function.utf8-encode.php
om författaren
David C. Zentgraf är en webbutvecklare som arbetar delvis i Japan och Europa och ären vanlig på Stackflöde.Om du har feedback, kritik eller tillägg, är du välkommen att prova @deceze på Twitter,ta en utbildad gissning på sin e-postadress eller slå upp det med hjälp av hävdvunna metoder.Denna artikel publicerades på kunststube.net. och nej, det finns inget smutsigt ord i”Kunststube”.