Ce que chaque programmeur a absolument, positivement besoin de savoir sur les encodages et les jeux de caractères pour travailler avec du texte
Si vous avez affaire à du texte sur un ordinateur, vous devez savoir sur les encodages. Période. Oui, même si vous envoyez simplement des e-mails. Même si vous ne faites que recevoir des e-mails. Vous n’avez pas besoin de comprendre tous les détails, mais vous devez au moins savoir de quoi parle toute cette chose « d’encodage ». Et les bonnes nouvelles d’abord: bien que le sujet puisse devenir désordonné et déroutant, l’idée de base est vraiment, vraiment simple.
Cet article concerne les encodages et les jeux de caractères. Un article de Joel Spolsky intitulé Le Minimum Absolu Que Tout Développeur de Logiciel Doit Absolument Connaître Sur Unicode et les Jeux de Caractères (Pas d’Excuses!) est une belle introduction au sujet et j’aime beaucoup le lire de temps en temps. J’hésite à y référer des gens qui ont du mal à comprendre les problèmes d’encodage car, tout en étant divertissant, il est assez léger sur les détails techniques réels. J’espère que cet article pourra éclairer un peu plus sur ce qu’est exactement un encodage et pourquoi tout votre texte se bouscule quand vous en avez le moins besoin. Cet article s’adresse aux développeurs (en mettant l’accent sur PHP), mais tout utilisateur d’ordinateur devrait pouvoir en bénéficier.
Clarifier les bases
Tout le monde en est conscient à un certain niveau, mais d’une manière ou d’une autre, cette connaissance semble soudainement disparaître dans une discussion sur le texte, alors allons-la d’abord: un ordinateur ne peut pas stocker des « lettres », des « chiffres », des « images » ou quoi que ce soit d’autre. La seule chose avec laquelle il peut stocker et travailler sont des bits. Un bit ne peut avoir que deux valeurs : yes ou notrue ou false1 ou 0 ou tout ce que vous voulez appeler ces deux valeurs. Comme un ordinateur fonctionne avec de l’électricité, un bit « réel » est un flux d’électricité qui est ou n’est pas là. Pour les humains, cela est généralement représenté en utilisant 1 et 0 et je m’en tiendrai à cette convention tout au long de cet article.
Pour utiliser des bits pour représenter n’importe quoi en plus des bits, nous avons besoin de règles. Nous devons convertir une séquence de bits en quelque chose comme des lettres, des chiffres et des images en utilisant un schéma de codage, ou un codage pour faire court. Comme ceci:
01100010 01101001 01110100 01110011b i t s
Dans cet encodage, 01100010 représente la lettre « b », 01101001 pour la lettre « i », 01110100 représente « t » et 01110011 pour « s ». Une certaine séquence de bits représente une lettre et une lettre représente une certaine séquence de bits. Si vous pouvez garder cela dans votre tête pendant 26 lettres ou si vous êtes très rapide à regarder des choses dans une table, vous pourriez lire des morceaux comme un livre.
Le schéma de codage ci-dessus se trouve être ASCII. Une chaîne de 1s et 0s est décomposée en parties de huit bits chacune (un octet pour faire court). Le codage ASCII spécifie une table traduisant des octets en lettres lisibles par l’homme. Voici un court extrait de ce tableau:
bits
character
01000001
A
01000010
B
01000011
C
01000100
D
01000101
E
01000110
F
There are 95 human readable caractères spécifiés dans le tableau ASCII, y compris les lettres A à Z en majuscules et minuscules, les chiffres 0 à 9, une poignée de signes de ponctuation et des caractères comme le symbole du dollar, l’esperluette et quelques autres. Il comprend également 33 valeurs pour des éléments tels que l’espace, le saut de ligne, la tabulation, le retour arrière, etc. Ceux-ci ne sont pas imprimables en soi, mais toujours visibles sous une forme ou une autre et utiles directement aux humains. Un certain nombre de valeurs ne sont utiles qu’à un ordinateur, comme des codes pour signifier le début ou la fin d’un texte. Au total, il y a 128 caractères définis dans le codage ASCII, ce qui est un bon nombre rond (pour les personnes qui utilisent des ordinateurs), car il utilise toutes les combinaisons possibles de 7 bits (000000000000010000010 via 1111111).1
Et voilà, la façon de représenter du texte lisible par l’homme en utilisant uniquement 1s et 0s.
Pour coder quelque chose en ASCII, suivez le tableau de droite à gauche, en remplaçant les lettres par des bits. Pour décoder une chaîne de bits en caractères lisibles par l’homme, suivez le tableau de gauche à droite, en remplaçant les bits par des lettres.
encoder|enˈkōd/ verbe convertir en une forme codée
code|kōd/ nom un système de mots, lettres, chiffres ou autres symboles substitués à d’autres mots, lettres, etc.
Encoder signifie utiliser quelque chose pour représenter autre chose. Un encodage est l’ensemble de règles avec lesquelles convertir quelque chose d’une représentation à une autre.
Autres termes qui méritent d’être clarifiés dans ce contexte :
jeu de caractères, jeu de caractères L’ensemble des caractères pouvant être codés. « Le codage ASCII comprend un jeu de caractères de 128 caractères. »Essentiellement synonyme de « codage ». page de code Une « page » de codes qui mappe un caractère à une séquence de nombres ou de bits. Alias « la table ». Essentiellement synonyme de « codage ». chaîne Une chaîne est un ensemble d’éléments ficelés ensemble. Une chaîne de bits est un tas de bits, comme
01010011. Une chaîne de caractères est un ensemble de caractères,like this. Synonyme de « séquence ».
Binaire, octal, décimal, hexadécimal
Il existe de nombreuses façons d’écrire des nombres. 10011111 en binaire est 237 en octal est 159 en décimal est 9F en hexadécimal. Ils représentent tous la même valeur, mais l’hexadécimal est plus court et plus facile à lire que le binaire. Je vais m’en tenir au binaire tout au long de cet article pour mieux comprendre le point et épargner au lecteur une couche d’abstraction. Do not be alarmed to see character codes referred to in other notations elsewhere, it’s all the same thing.
excuse-moi?
Now that we know what we’re talking about, let’s just say it: 95 characters really isn’t a lot when it comes to languages. It covers the basics of English, but what about writing a risqué letter in French? A Loi sur le changement de passage de la route en allemand? An invitation to a smörgåsbord in Swedish? Well, you couldn’T. Not in ASCII. There’s no specification on how to represent any of the letters é, ß, ü, ä, ö or å in ASCII, so you can’t use them.
« Mais regardez-le », ont dit les Européens, « dans un ordinateur commun avec 8 bits à l’octet, ASCII gaspille un bit entier qui est toujours réglé sur 0! Nous pouvons utiliser ce bit pour presser 128 valeurs entières dans cette table! » Et ils l’ont fait. Mais même ainsi, il existe plus de 128 façons de caresser, de découper, de couper et de marquer une voyelle. Toutes les variantes de lettres et de gribouillis utilisées dans toutes les langues européennes ne peuvent pas être représentées dans le même tableau avec un maximum de 256 valeurs. Le monde s’est donc retrouvé avec une multitude de schémas d’encodage, de normes, de normes de facto et de demi-normes qui couvrent tous un sous-ensemble de caractères différent. Quelqu’un avait besoin d’écrire un document sur le suédois en tchèque, a constaté qu’aucun encodage ne couvrait les deux langues et en a inventé un. Ou alors j’imagine que ça s’est passé d’innombrables fois.
Et sans oublier le Russe, l’Hindi, l’Arabe, l’Hébreu, le Coréen et toutes les autres langues actuellement en usage sur cette planète. Sans parler de ceux qui ne sont plus utilisés. Une fois que vous avez résolu le problème de la rédaction de documents en langues mixtes dans toutes ces langues, essayez le chinois. Ou Japonais. Les deux contiennent des dizaines de milliers de caractères. Vous avez 256 valeurs possibles sur un octet composé de 8 bits. Allez-y!
Encodages multi-octets
Pour créer une table qui mappe des caractères en lettres pour une langue qui utilise plus de 256 caractères, un octet ne suffit tout simplement pas. En utilisant deux octets (16 bits), il est possible d’encoder 65 536 valeurs distinctes. BIG-5 est un tel codage à deux octets. Au lieu de diviser une chaîne de bits en blocs de huit, il la divise en blocs de 16 et a une grande table (je veux dire, GRANDE) qui spécifie à quel caractère chaque combinaison de bits correspond. BIG-5 dans sa forme de base couvre principalement les caractères chinois traditionnels. GB18030 est un autre codage qui fait essentiellement la même chose, mais inclut des caractères chinois traditionnels et simplifiés. Et avant de demander, oui, il y a des encodages qui ne couvrent que le chinois simplifié. On ne peut pas avoir un seul encodage maintenant, n’est-ce pas ?
Voici un petit extrait du tableau GB18030:
bits
character
10000001 01000000
丂
10000001 01000001
丄
10000001 01000010
丅
10000001 01000011
丆
10000001 01000100
丏
GB18030 covers quite a range of characters (including a large part of latin caractères), mais à la fin est encore un autre format d’encodage spécialisé parmi beaucoup.
Unicode à la confusion
Finalement, quelqu’un en avait assez du désordre et se mit à forger un anneau pour les lier tous créer un encodage standard pour unifier toutes les normes d’encodage. Cette norme est Unicode. Il définit essentiellement une table gigantesque de 1 114 112 points de code pouvant être utilisés pour toutes sortes de lettres et de symboles. C’est beaucoup pour encoder tous les personnages européens, du Moyen-Orient, de l’Extrême-Orient, du Sud, du Nord, de l’Ouest, pré-historiens et futurs que l’humanité connaît.2 En utilisant Unicode, vous pouvez écrire un document contenant pratiquement n’importe quelle langue en utilisant n’importe quel caractère que vous pouvez taper sur un ordinateur. C’était soit impossible, soit très très difficile à obtenir avant l’arrivée d’Unicode. Il y a même une section non officielle pour le Klingon en Unicode. En effet, Unicode est assez grand pour permettre des zones non officielles à usage privé.
Alors, combien de bits Unicode utilise-t-il pour coder tous ces caractères? Aucun. Parce que Unicode n’est pas un encodage.
Confus? Beaucoup de gens semblent l’être. Unicode définit avant tout une table de points de code pour les caractères. C’est une façon élégante de dire « 65 représente A, 66 représente B et 9 731 représente ☃ » (sérieusement, c’est le cas). La façon dont ces points de code sont réellement codés en bits est un sujet différent. Pour représenter 1 114 112 valeurs différentes, deux octets ne suffisent pas. Trois octets le sont, mais trois octets sont souvent difficiles à utiliser, donc quatre octets seraient le minimum confortable. Mais, à moins que vous n’utilisiez réellement le chinois ou certains des autres caractères avec de gros nombres qui prennent beaucoup de bits à coder, vous n’utiliserez jamais un énorme morceau de ces quatre octets. Si la lettre « A » était toujours codée en 00000000 00000000 00000000 01000001, « B » toujours en 00000000 00000000 00000000 01000010 et ainsi de suite, tout document serait gonflé à quatre fois la taille nécessaire.
Pour optimiser cela, il existe plusieurs façons de coder les points de code Unicode en bits. UTF-32 est un codage qui code tous les points de code Unicode en utilisant 32 bits. C’est-à-dire quatre octets par caractère. C’est très simple, mais gaspille souvent beaucoup d’espace. UTF-16 et UTF-8 sont des codages de longueur variable. Si un caractère peut être représenté en utilisant un seul octet (car son point de code est un très petit nombre), UTF-8 l’encodera avec un seul octet. S’il nécessite deux octets, il utilisera deux octets et ainsi de suite. Il a des moyens élaborés d’utiliser les bits les plus élevés d’un octet pour signaler le nombre d’octets d’un caractère. Cela peut économiser de l’espace, mais peut également perdre de l’espace si ces bits de signal doivent être utilisés souvent. UTF-16 est au milieu, utilisant au moins deux octets, atteignant jusqu’à quatre octets si nécessaire.
character
encoding
bits
A
UTF-8
01000001
A
UTF-16
00000000 01000001
A
UTF-32
00000000 00000000 00000000 01000001
あ
UTF-8
11100011 10000001 10000010
あ
UTF-16
00110000 01000010
あ
UTF-32
00000000 00000000 00110000 01000010
Et c’est tout ce qu’il y a à faire. Unicode est une grande table mappant des caractères aux nombres et les différents encodages UTF spécifient comment ces nombres sont codés en bits. Dans l’ensemble, Unicode est un autre schéma de codage. Il n’y a rien de spécial, c’est juste essayer de tout couvrir tout en étant efficace. Et c’est Une Bonne Chose.™
Points de code
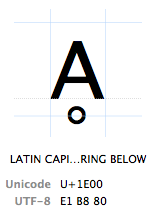
Les caractères sont désignés par leur « point de code Unicode ». Les points de code Unicode sont écrits en hexadécimal (pour garder les nombres plus courts), précédés d’un « U + » (c’est exactement ce qu’ils font, cela n’a pas d’autre sens que « c’est un point de code Unicode »). Le caractère has a le point de code Unicode U+1E00. Dans d’autres mots (décimaux), c’est le 7680e caractère de la table Unicode. Il est officiellement appelé « LETTRE MAJUSCULE LATINE A AVEC ANNEAU EN DESSOUS ».
TL; DR
Un résumé de tout ce qui précède: Tout caractère peut être codé dans de nombreuses séquences de bits différentes et toute séquence de bits particulière peut représenter de nombreux caractères différents, selon le codage utilisé pour les lire ou les écrire. La raison en est simplement que différents encodages utilisent différents nombres de bits par caractères et différentes valeurs pour représenter différents caractères.
bits
encoding
characters
11000100 01000010
Windows Latin 1
ÄB
11000100 01000010
Mac Roman
ƒB
11000100 01000010
GB18030
腂
characters
encoding
bits
Idées fausses, confusions et problèmes
Cela dit, nous arrivons aux problèmes réels rencontrés par de nombreux utilisateurs et programmeurs chaque jour, comment ces problèmes se rapportent à tout ce qui précède et quelle est leur solution. Le plus gros problème de tous est :
Pourquoi mes personnages sont-ils brouillés au nom de Dieu ?!
ÉGÉìÉRÅ;
Si ce $string était dans un codage à un octet, cela nous donnerait le premier caractère. Mais seulement parce que « caractère » coïncide avec « octet » dans un codage à un octet. PHP nous donne simplement le premier octet sans penser aux « caractères ». Les chaînes sont des séquences d’octets à PHP, rien de plus, rien de moins. Tout ce genre de « caractère lisible » est une chose humaine et PHP ne s’en soucie pas.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !
Il en va de même pour de nombreuses fonctions standard telles que substrstrpostrim et ainsi de suite. Le non-support se produit s’il y a un écart entre la longueur d’un octet et d’un caractère.
Utiliser $string sur la chaîne ci-dessus nous donnera, encore une fois, le premier octet, qui est 11100110. En d’autres termes, un tiers du caractère de trois octets « 漢 ». 11100110 est, en soi, une séquence UTF-8 non valide, donc la chaîne est maintenant cassée. Si vous en avez envie, vous pouvez essayer d’interpréter cela dans un autre encodage où 11100110 représente un caractère valide, ce qui entraînera un caractère aléatoire. Amusez-vous, mais ne l’utilisez pas en production.
Et c’est en fait tout ce qu’il y a à faire. « PHP ne supporte pas nativement Unicode » signifie simplement que la plupart des fonctions PHP supposent un octet = un caractère, ce qui peut l’amener à couper les caractères multi-octets en deux ou à calculer la longueur des chaînes de manière incorrecte si vous utilisez naïvement des fonctions non sensibles aux multi-octets sur des chaînes de plusieurs octets. Cela ne signifie pas que vous ne pouvez pas utiliser Unicode en PHP ou que chaque chaîne Unicode doit être bénie par utf8_encode ou d’autres absurdités de ce type.
Heureusement, il y a l’extension de chaîne multioctet, qui réplique toutes les fonctions de chaîne importantes d’une manière compatible avec plusieurs octets. L’utilisation de mb_substr($string, 0, 1, 'UTF-8') sur la chaîne ci-dessus renvoie correctement 11100110 10111100 10100010, qui est l’ensemble du caractère « 漢 ». Parce que les fonctions mb_ doivent maintenant réfléchir à ce qu’elles font, elles doivent savoir sur quel encodage elles travaillent. Par conséquent, chaque fonction mb_ accepte également un paramètre $encoding. Alternativement, cela peut être défini globalement pour toutes les fonctions mb_ en utilisant mb_internal_encoding.
Utiliser et abuser de la gestion des encodages par PHP
Tout le problème du support (non) de PHP pour Unicode est qu’il ne s’en soucie tout simplement pas. Les chaînes sont des séquences d’octets à PHP. Quels octets en particulier n’a pas d’importance. PHP ne fait rien avec les chaînes sauf les garder stockées en mémoire. PHP n’a tout simplement aucun concept de caractères ou d’encodages. Et à moins qu’il n’essaie de manipuler des chaînes, il n’en a pas besoin non plus; il conserve simplement des octets qui peuvent ou non éventuellement être interprétés comme des caractères par quelqu’un d’autre. La seule exigence que PHP a en matière d’encodages est que le code source PHP doit être enregistré dans un encodage compatible ASCII. L’analyseur PHP recherche certains caractères qui lui disent quoi faire. $00100100) signale le début d’une variable, =00111101) une affectation, "00100010) le début et la fin d’une chaîne et ainsi de suite. Tout ce qui n’a pas de signification particulière pour l’analyseur est simplement pris comme une séquence d’octets littérale. Cela inclut tout ce qui se trouve entre les guillemets, comme indiqué ci-dessus. Cela signifie ce qui suit :
Vous ne pouvez pas enregistrer le code source PHP dans un codage incompatible avec ASCII. Par exemple, en UTF-16, un " est codé comme 00000000 00100010. Pour PHP, qui essaie de tout lire en ASCII, c’est un octet NUL suivi d’un ".PHP aura probablement un hoquet si tous les autres caractères qu’il trouve sont un octet NUL.
Vous pouvez enregistrer le code source PHP dans n’importe quel encodage compatible ASCII. Si les 128 premiers points de code d’un encodage sont identiques à ASCII, PHP peut l’analyser. Tous les caractères significatifs pour PHP se trouvent dans les 128 points de code définis par ASCII. Si les littéraux de chaîne contiennent des points de code au-delà, PHP s’en fiche. Vous pouvez enregistrer le code source PHP en ISO-8859-1, Mac Roman, UTF-8 ou tout autre encodage compatible ASCII. Les littéraux de chaîne de votre script auront le codage sous lequel vous avez enregistré votre code source.
Tout fichier externe que vous traitez avec PHP peut être dans le codage que vous souhaitez. Si PHP n’a pas besoin de l’analyser, il n’y a aucune exigence à respecter pour que l’analyseur PHP reste satisfait.
$foo = file_get_contents('bar.txt');
Ce qui précède lira simplement les bits de bar.txt dans la variable $foo. PHP n’essaie pas d’interpréter, de convertir, d’encoder ou de jouer avec le contenu. Le fichier peut même contenir des données binaires telles qu’une image, PHP s’en fiche.
Si les encodages internes et externes doivent correspondre, ils doivent correspondre. Un cas courant est la localisation, oùle code source contient quelque chose comme echo localize('Foobar') et un fichier de localisation externe contient quelque chose dans le sens de ceci:
msgid "Foobar"msgstr "フーバー"
Les deux chaînes « Foobar » doivent avoir une représentation binaire identique si vous voulez trouver la localisation correcte.Si le code source était enregistré en ASCII mais le fichier de localisation en UTF-16, les chaînes ne correspondraient pas.Soit une sorte de conversion d’encodage serait nécessaire, soit l’utilisation d’une fonction de correspondance de chaîne compatible avec l’encodage.
Le lecteur astucieux peut demander à ce stade s’il est possible d’enregistrer une séquence d’octets UTF-16 dans un littéral de chaîne d’un fichier de code source codé en ASCII, à laquelle la réponse serait: absolument.
echo "UTF-16";
Si vous pouvez apporter votre éditeur de texte pour enregistrer les parties echo " et "; en ASCII et seulement UTF-16 en UTF-16, cela fonctionnera très bien. La représentation binaire nécessaire pour cela ressemble à ceci:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;
La première ligne et les deux derniers octets sont ASCII. Le reste est UTF-16 avec deux octets par caractère. Le 11111110 11111111 en tête sur la ligne 2 est un marqueur requis au début du texte encodé en UTF-16 (requis par la norme UTF-16, PHP s’en fout). Ce script PHP produira avec plaisir la chaîne « UTF-16 » codée en UTF-16, car il génère simplement les octets entre les deux guillemets doubles, ce qui représente le texte « UTF-16 » codé en UTF-16. Le fichier de code source n’est cependant ni ASCII ni UTF-16 complètement valide, donc travailler avec lui dans un éditeur de texte ne sera pas très amusant.
Bottom line
PHP supporte Unicode, ou en fait n’importe quel encodage, très bien, tant que certaines exigences sont remplies pour que l’analyseur soit satisfait et que le programmeur sache ce qu’il fait. Il vous suffit vraiment d’être prudent lorsque vous manipulez des chaînes, ce qui inclut le découpage, le rognage, le comptage et d’autres opérations qui doivent se produire au niveau d’un caractère plutôt qu’au niveau d’un octet. Si vous ne « faites rien » avec vos chaînes en plus de les lire et de les sortir, vous n’aurez guère de problèmes avec le support des encodages de PHP que vous n’auriez pas dans une autre langue.
Langages compatibles avec l’encodage
Qu’est-ce que cela signifie pour une langue de prendre en charge Unicode alors? Javascript par exemple prend en charge Unicode. En fait, toute chaîne en Javascript est codée en UTF-16. En fait, c’est la seule chose avec laquelle Javascript s’occupe. Vous ne pouvez pas avoir une chaîne en Javascript qui n’est pas encodée en UTF-16. Javascript vénère Unicode dans la mesure où il n’y a aucune possibilité de traiter un autre encodage dans le langage principal. Étant donné que Javascript est le plus souvent exécuté dans un navigateur, ce n’est pas un problème, car le navigateur peut gérer la logistique banale de l’encodage et du décodage des entrées et des sorties.
D’autres langages sont simplement compatibles avec l’encodage. En interne, ils stockent des chaînes dans un encodage particulier, souvent UTF-16. À leur tour, ils doivent être informés ou essayer de détecter l’encodage de tout ce qui a trait au texte. Ils doivent savoir dans quel encodage le code source est enregistré, dans quel encodage un fichier ils sont censés lire, dans quel encodage vous souhaitez afficher du texte; et ils convertissent les encodages à la volée selon les besoins avec une manifestation d’Unicode comme intermédiaire. Ils font la même chose que vous pouvez / devriez / devez faire en PHP semi-automatiquement dans les coulisses. Ce n’est ni meilleur ni pire que PHP, juste différent. La bonne chose à ce sujet est que les fonctions de langage standard qui traitent des chaînes fonctionnent simplement ™, alors qu’en PHP, il faut faire attention à savoir si une chaîne peut contenir des caractères multi-octets ou non et choisir les fonctions de manipulation de chaînes en conséquence.
Les profondeurs d’Unicode
Comme Unicode traite de nombreux scripts différents et de nombreux problèmes différents, il a beaucoup de profondeur. Par exemple, la norme Unicode contient des informations pour des problèmes tels que l’unification des idéogrammes CJK. Cela signifie que deux caractères chinois / Japonais / coréen ou plus représentent en fait le même caractère dans des méthodes d’écriture légèrement différentes. Ou des règles sur la conversion des minuscules en majuscules, vice-versa et aller-retour, ce qui n’est pas toujours aussi simple dans tous les scripts que dans la plupart des scripts dérivés du latin d’Europe occidentale. Certains caractères peuvent également être représentés à l’aide de différents points de code. La lettre « ö » par example peut être représentée en utilisant le point de code U+00F6 (« PETITE LETTRE LATINE O AVEC DIAÉRÈSE ») ou comme les deux points de code U+006F (« PETITE LETTRE LATINE O ») et U+0308 (« DIAÉRÈSE COMBINÉE »), c’est-à-dire la lettre « o » combinée à « ». En UTF-8, c’est soit la séquence à deux octets 11000011 10110110, soit la séquence à trois octets 01101111 11001100 10001000, les deux représentant le même caractère lisible par l’homme. En tant que tel, il existe des règles régissant la normalisation au sein de la norme Unicode, c’est-à-dire la façon dont l’une de ces formes peut être convertie en l’autre. Ceci et bien d’autres sont en dehors du champ d’application de cet article, mais il faut en être conscient.
Final TL; DR
Le texte est toujours une séquence de bits qui doit être traduite en texte lisible par l’homme à l’aide de tables de recherche. Si la mauvaise table de recherche est utilisée, le mauvais caractère est utilisé.
Vous ne traitez jamais directement de « caractères » ou de « texte », vous traitez toujours de bits vus à travers plusieurs couches d’abstractions. Des résultats incorrects sont le signe de l’échec d’une des couches d’abstraction.
Si deux systèmes se parlent, ils doivent toujours spécifier dans quel encodage ils veulent se parler. L’exemple le plus simple de ceci est ce site Web indiquant à votre navigateur qu’il est encodé en UTF-8.
De nos jours, l’encodage standard est UTF-8 car il peut encoder pratiquement n’importe quel caractère d’intérêt, est rétrocompatible avec l’ASCII de base de facto et est relativement économe en espace pour la majorité des cas d’utilisation néanmoins.
D’autres encodages ont encore parfois leurs utilisations, mais vous devriez avoir une raison concrète de vouloir faire face aux maux de tête associés aux jeux de caractères qui ne peuvent coder qu’un sous-ensemble d’Unicode.
Les jours d’un octet = un caractère sont terminés et les programmeurs et les programmes doivent rattraper leur retard.
Maintenant, vous ne devriez vraiment plus avoir d’excuse la prochaine fois que vous grattez du texte.
Oui, cela signifie que l’ASCII peut être stocké et transféré en utilisant seulement 7 bits et c’est souvent le cas. Non, ce n’est pas dans le cadre de cet article et pour des raisons d’argument, nous supposerons que le bit le plus élevé est « gaspillé » en ASCII. ↩
Et si ce n’est pas le cas, il sera étendu. Cela l’a déjà été plusieurs fois. Please
Veuillez noter que lorsque j’utilise le terme « démarrage » avec « octet », je le veux dire du point de vue lisible par l’homme. Per
Parcourez la spécification UTF-8 si vous souhaitez la suivre avec un stylo et du papier. Hey
Hé, je suis un programmeur, pas un biologiste. ↩
Et bien sûr, il n’y aura pas de sauvegarde récente. ↩
Un « caractère Unicode » est un point de code dans la table Unicode. « あ » n’est pas un caractère Unicode, c’est la lettre Hiragana あ. Il y a un point de code Unicode pour cela, mais cela ne fait pas de la lettre elle-même un caractère Unicode. Un « caractère UTF-8 » est un oxymore, mais peut être étiré pour signifier ce qu’on appelle techniquement une « séquence UTF-8 », qui est une séquence d’octets d’un, deux, trois ou quatre octets représentant un caractère Unicode. Les deux termes sont souvent utilisés dans le sens de « toute lettre qui ne fait pas partie de mon clavier », ce qui ne signifie absolument rien. David
David C. Zentgraf est un développeur web travaillant en partie au Japon et en Europe et est un habitué du débordement de pile.Si vous avez des commentaires, des critiques ou des ajouts, n’hésitez pas à essayer @deceze sur Twitter, à deviner son adresse e-mail ou à la rechercher en utilisant des méthodes ancestrales.Cet article a été publié le kunststube.net . Et non, il n’y a pas de mot sale dans « Kunststube ».