hva hver programmerer absolutt, positivt trenger å vite om kodinger og tegnsett for å jobbe med tekst
Hvis du har å gjøre med tekst i en datamaskin, må du vite om kodinger. Periode. Ja, selv om du bare sender e-post. Selv om du bare mottar e-post. Du trenger ikke å forstå hver eneste detalj, men du må i det minste vite hva hele denne «kodingen» handler om. De gode nyhetene først: mens emnet kan bli rotete og forvirrende, er den grunnleggende ideen virkelig, veldig enkel.
denne artikkelen handler om kodinger og tegnsett. En artikkel Av Joel Spolsky med tittelen Absolutt Minimum Hver Programvareutvikler Absolutt, Positivt Må Vite Om Unicode Og Tegnsett(Ingen Unnskyldninger !) er en fin introduksjon til emnet, og jeg liker å lese det hver gang en stund. Jeg nøler med å henvise folk til det som har problemer med å forstå kodingsproblemer, men siden det er underholdende, er det ganske lett på faktiske tekniske detaljer. Jeg håper denne artikkelen kan kaste litt mer lys på hva en koding er og bare hvorfor all teksten skruer opp når du minst trenger det. Denne artikkelen er rettet mot utviklere (med FOKUS PÅ PHP), men enhver datamaskinbruker skal kunne dra nytte av det.
Få det grunnleggende rett
Alle er klar over dette på et visst nivå, men på en eller annen måte ser denne kunnskapen plutselig ut til å forsvinne i en diskusjon om tekst, så la oss få det ut først: en datamaskin kan ikke lagre «bokstaver», «tall», «bilder» eller noe annet. Det eneste den kan lagre og jobbe med er biter. En bit kan bare ha to verdier: yes eller notrue eller false1 eller 0 eller hva annet du vil kalle disse to verdiene. Siden en datamaskin fungerer med strøm, er en» faktisk » bit et blip av elektrisitet som enten er eller ikke er der. For mennesker er dette vanligvis representert ved hjelp av 1 og 0 og jeg holder meg til denne konvensjonen gjennom hele denne artikkelen.
for å bruke biter til å representere noe i det hele tatt, trenger vi regler. Vi må konvertere en sekvens av biter til noe som bokstaver, tall og bilder ved hjelp av et kodingssystem, eller koding for kort. Slik:
01100010 01101001 01110100 01110011b i t si denne kodingen står 01100010 for bokstaven «b», 01101001 for bokstaven «i», 01110100 står for «t» og 01110011 for «s». En viss sekvens av biter står for et brev og et brev står for en viss sekvens av biter. Hvis du kan holde dette i hodet ditt for 26 bokstaver eller er veldig rask med å se ting opp i et bord, kan du lese biter som en bok.
ovennevnte kodingsskjema skjer FOR Å VÆRE ASCII. En streng av 1s og 0 s er brutt ned i deler av åtte bit hver (en byte for kort). ASCII-kodingen angir en tabell som oversetter byte til lesbare bokstaver. Her er et kort utdrag av det bordet:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable tegn som er angitt i ASCII-tabellen, inkludert bokstavene A Til Z både i store og små bokstaver, tallene 0 til 9, en håndfull tegnsettingstegn og tegn som dollarsymbolet, ampersand og noen få andre. Det inkluderer også 33 verdier for ting som plass, linje feed, tab, backspace og så videre. Disse er ikke utskrivbare per se, men fortsatt synlig i noen form og nyttig for mennesker direkte. En rekke verdier er bare nyttige for en datamaskin, for eksempel koder for å betegne starten eller slutten av en tekst. TOTALT er DET 128 tegn definert I ASCII-kodingen, som er et fint rundt tall (for folk som arbeider med datamaskiner), siden det bruker alle mulige kombinasjoner av 7 biter (000000000000010000010 gjennom 1111111).1
Og der har du det, måten å representere menneskelig lesbar tekst med bare 1s og 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100«Hei Verden»
Viktige termer
for å kode noe i ASCII, følg tabellen fra høyre til venstre, og erstatt bokstaver for biter. For å dekode en streng biter i lesbare tegn, følg tabellen fra venstre til høyre, erstatte biter for bokstaver.
kode|enˈ
verb
konverter til en kodet formkode |kō
substantiv
et system av ord, bokstaver, figurer eller andre symboler erstattet av andre ord, bokstaver, etc.
å kode betyr å bruke noe til å representere noe annet. En koding er settet med regler som å konvertere noe fra en representasjon til en annen.
Andre vilkår som fortjener avklaring i denne konteksten:
tegnsett, tegnsett settet med tegn som kan kodes. «ASCII-kodingen omfatter et tegnsett med 128 tegn.»I hovedsak synonymt med «koding». kodeside en «side» med koder som tilordner et tegn til et tall eller en bitsekvens. A. k. a. «bordet». I hovedsak synonymt med «koding». string en streng er en haug med elementer hengt sammen. En bitstreng er en haug med biter ,som01010011. En tegnstreng er en gjeng med tegn,like this. Synonymt med «sekvens».
Binær, oktal, desimal, hex
det er mange måter å skrive tall på. 10011111 i binær er 237 i oktal er 159 i desimal er 9F i heksadesimal. De representerer alle samme verdi, men heksadesimal er kortere og lettere å lese enn binær. Jeg vil feste med binary gjennom denne artikkelen for å få poenget bedre og spare leseren ett lag av abstraksjon. Ikke vær redd for å se tegnkoder nevnt i andre notater andre steder, det er alt det samme.
Excusez-moi?
nå som vi vet hva vi snakker om, la oss bare si det: 95 tegn er egentlig ikke mye når det gjelder språk. Den dekker det grunnleggende i engelsk, men hva med å skrive et risqué brev på fransk? En Straumen@bergangs Hryvnderungsgesetz på tysk? En invitasjon til en sm hryvnasbord på svensk? Ikke I ASCII. Det er ingen spesifikasjon på hvordan å representere noen av bokstavene é, ß, ü, ä, ö eller å i ASCII-format, slik at du ikke kan bruke dem.»Men se på Det,» Sa Europeerne, » I en vanlig datamaskin med 8 biter til byten, KASTER ASCII bort en hel bit som alltid er satt til 0! Vi kan bruke den biten til å presse en hel ‘ nother 128 verdier inn i det bordet!»Og det gjorde de. Men likevel er det mer enn 128 måter å stryke, skive, slash og dot en vokal på. Ikke alle varianter av bokstaver og squiggles som brukes på Alle Europeiske språk, kan representeres i samme tabell med maksimalt 256 verdier. Så hva verden endte opp med, er et vell av kodingsordninger, standarder, de-facto standarder og halvstandarder som alle dekker en annen delmengde av tegn. Noen trengte å skrive et dokument om svensk på tsjekkisk, fant ut at ingen koding dekket begge språk og oppfunnet en. Eller så jeg antar det gikk utallige ganger over.Og ikke å glemme russisk, Hindi, arabisk, hebraisk, koreansk og alle de andre språkene som er i aktiv bruk på denne planeten. For ikke å nevne de som ikke er i bruk lenger. Når du har løst problemet med hvordan du skriver blandede språkdokumenter på alle disse språkene, prøv Deg Selv På Kinesisk. Eller Japansk. Begge inneholder titusenvis av tegn. Du har 256 mulige verdier til en byte som bestar av 8 bit. Gå!
multi-byte kodinger
for å lage en tabell som tilordner tegn til bokstaver for et språk som bruker mer enn 256 tegn, er en byte ganske enkelt ikke nok. Ved å bruke to byte (16 bits), er det mulig å kode 65 536 forskjellige verdier. BIG-5 er en slik dobbel-byte-koding. I stedet for å bryte en streng biter i blokker på åtte, bryter den den inn i blokker på 16 og har et stort (jeg mener STORT) bord som angir hvilket tegn hver kombinasjon av biter kart til. BIG-5 i sin grunnleggende form dekker for Det Meste Tradisjonelle Kinesiske tegn. GB18030 ER en annen koding som i hovedsak gjør det samme, men inkluderer Både Tradisjonelle Og Forenklede Kinesiske tegn. Og før du spør, ja, det er kodinger som dekker Bare Forenklet Kinesisk. Kan ikke bare ha en koding nå, kan vi?
her et lite utdrag FRA GB18030-tabellen:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin tegn), men til slutt er enda en spesialisert koding format blant mange.
Unicode til forvirring

endelig noen hadde nok av rotet og satt ut for å smi en ring for å binde dem alle lage en koding standard for å forene alle kodingsstandarder. Denne standarden Er Unicode. Det definerer i utgangspunktet en enorm tabell med 1.114.112 kodepunkter som kan brukes til alle slags bokstaver og symboler. Det er nok å kode Alle Europeiske, Midtøsten, Fjerne Østlige, Sørlige, Nordlige, Vestlige, pre-historiker og fremtidige tegn menneskeheten vet om.2 Ved Hjelp Av Unicode kan du skrive et dokument som inneholder nesten alle språk ved hjelp av alle tegn du kan skrive inn i en datamaskin. Dette var enten umulig eller veldig veldig vanskelig å få rett før Unicode kom sammen. Det er enda en uoffisiell seksjon For Klingon I Unicode. Faktisk Er Unicode stor nok til å tillate uoffisielle, private bruksområder.
Så, hvor mange biter Bruker Unicode til å kode alle disse tegnene? Ingenting. Fordi Unicode ikke er en koding.
Forvirret? Mange synes å være. Unicode definerer først og fremst en tabell med kodepunkter for tegn. Det er en fancy måte å si «65 står for A, 66 står For B og 9,731 står for ☃» (seriøst, det gjør det). Hvordan disse kodepunktene faktisk er kodet inn i biter, er et annet emne. For å representere 1 114 112 forskjellige verdier, er to byte ikke nok. Tre byte er, men tre byte er ofte vanskelig å jobbe med, så fire byte ville være det komfortable minimumet. Men med mindre du faktisk bruker Kinesisk eller noen Av de andre tegnene med store tall som tar mange biter å kode, kommer du aldri til å bruke en stor del av de fire bytene. Hvis bokstaven » A » alltid var kodet til 00000000 00000000 00000000 01000001, » B «alltid til 00000000 00000000 00000000 01000010 og så videre, ville ethvert dokument oppblåst til fire ganger den nødvendige størrelsen.
for å optimalisere dette, er Det flere måter Å kode Unicode-kodepunkter i biter. UTF-32 er en slik koding som koder for Alle Unicode-kodepunkter ved hjelp av 32 bits. Det vil si fire byte per tegn. Det er veldig enkelt, men ofte kaster bort mye plass. Utf-16 og utf-8 er kodinger med variabel lengde. Hvis et tegn kan representeres ved hjelp av en enkelt byte (fordi kodepunktet er et veldig lite tall), vil UTF-8 kode det med en enkelt byte. Hvis det krever to byte, vil det bruke to byte og så videre. Den har utførlige måter å bruke de høyeste bitene i en byte for å signalisere hvor mange byte et tegn består av. Dette kan spare plass, men kan også kaste bort plass hvis disse signalbitene må brukes ofte. UTF-16 er i midten, bruker minst to byte, vokser til opptil fire byte etter behov.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
Og det er alt som skal til. Unicode er et stort bord som kartlegger tegn til tall, og de forskjellige utf-kodingene angir hvordan disse tallene er kodet som biter. Samlet Sett Er Unicode enda en kodingsordning. Det er ikke noe spesielt med det, det prøver bare å dekke alt mens det fortsatt er effektivt. Og Det er Bra.™
Kodepunkter
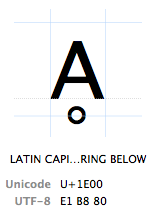
Tegn refereres til av Deres «Unicode-kodepunkt». Unicode-kodepunkter er skrevet i heksadesimal (for å holde tallene kortere), foran en «U+» (det er bare det de gjør, det har ingen annen mening enn «dette Er Et Unicode-kodepunkt»). Tegnet Ḁ har Unicode-kodepunktet U + 1E00. I andre (desimal) ord er Det 7680-tegnet I Unicode-tabellen. Det er offisielt kalt «LATIN STOR BOKSTAV A MED RING NEDENFOR».
TL;DR
et sammendrag av alt ovenfor: ethvert tegn kan kodes i mange forskjellige bitsekvenser, og en bestemt bitsekvens kan representere mange forskjellige tegn, avhengig av hvilken koding som brukes til å lese eller skrive dem. Årsaken er rett og slett fordi forskjellige kodinger bruker forskjellige antall biter per tegn og forskjellige verdier for å representere forskjellige tegn.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latin 1 | 01000110 11111000 11110110 |
| Føö | mac roman | 01000110 10111111 10011010 |
utf-8 |
misoppfatninger, forvirring og problemer
etter å ha sagt alt dette, kommer vi til de faktiske problemene Som Mange brukere Og programmerere Opplever hver dag, hvordan disse problemene Relaterer seg til alt ovenfor og hva deres løsning er. Det største problemet av alt er:
Hvorfor i guds navn er mine tegn forvrengt?!
ÉGÉìÉRÅ;hvis det$string var i en enkeltbyte-koding, ville dette gi oss det første tegnet. Men bare fordi «karakter» sammenfaller med «byte» i en enkeltbyte-koding. PHP gir oss bare den første byten uten å tenke på «tegn». Strenger er byte sekvenser TIL PHP, ingenting mer, ingenting mindre. Alt dette «lesbare tegnet» ting er en menneskelig ting, OG PHP bryr seg ikke om det.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !det samme gjelder for mange standardfunksjoner som substrstrpostrim og så videre. Ikke-støtten oppstår hvis det er avvik mellom lengden på en byte og et tegn.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Ved hjelp av$string på den ovennevnte strengen vil igjen gi oss den første byten, som er 11100110. Med andre ord, en tredjedel av tre-byte tegnet «漢». 11100110 er i seg selv en ugyldig utf-8-sekvens, så strengen er nå ødelagt. Hvis du følte det, kan du prøve å tolke det i en annen koding der 11100110 representerer et gyldig tegn, noe som vil resultere i noe tilfeldig tegn. Ha det gøy, men ikke bruk det i produksjon.
og det er faktisk alt det er til det. «PHP støtter Ikke Unicode» betyr ganske enkelt at DE fleste PHP-funksjoner antar en byte = ett tegn, noe som kan føre til at det hugger multi-byte-tegn i halv eller beregner lengden på strenger feil hvis du naivt bruker ikke-multi-byte-aware-funksjoner på multi-byte-strenger. Det betyr ikke at Du ikke kan bruke Unicode I PHP eller at Hver Unicode-streng må velsignes av utf8_encode eller annen slik tull.Heldigvis er Det Multibyte String-utvidelsen, som replikerer alle viktige strengfunksjoner på en multi-byte-oppmerksom måte. Ved å brukemb_substr($string, 0, 1, 'UTF-8') på strengen ovenfor returnerer du riktig 11100110 10111100 10100010, som er hele «漢» – tegnet. Fordimb_ funksjonene nå må faktisk tenke på hva de gjør, må de vite hvilken koding de jobber med. Derfor aksepterer hver mb_ funksjon en $encoding parameter også. Alternativt kan dette settes globalt for allemb_ funksjoner ved hjelp avmb_internal_encoding.
Bruke OG misbruke PHP håndtering av kodinger
hele problemet MED PHP (ikke-)støtte For Unicode er at det bare ikke bryr seg. Strenger er byte sekvenser TIL PHP. Hva bytes spesielt spiller ingen rolle. PHP gjør ikke noe med strenger bortsett fra å holde dem lagret i minnet. PHP har rett og slett ikke noe konsept av enten tegn eller kodinger. Og med mindre det prøver å manipulere strenger, trenger det heller ikke; det holder bare på byte som kanskje eller ikke til slutt tolkes som tegn av noen andre. DET eneste kravet PHP har kodinger er AT PHP kildekode må lagres i EN ASCII-kompatibel koding. PHP-parseren ser etter bestemte tegn som forteller det hva de skal gjøre. $00100100) signaliserer starten på en variabel, =00111101) en oppgave, "00100010) starten og slutten på en streng og så videre. Alt annet som ikke har noen spesiell betydning for parseren, tas bare som en bokstavelig byte-sekvens. Det inkluderer alt mellom sitater,som diskutert ovenfor. Dette betyr følgende:
-
DU kan ikke lagre PHP-kildekoden i EN ASCII-inkompatibel koding. I UTF-16 er for eksempel en
"kodede00000000 00100010. TIL PHP, som prøver å lese alt som ASCII, er det enNULbyte etterfulgt av en".PHP vil trolig få en hikke hvis alle andre tegn den finner er enNULbyte. -
DU kan lagre PHP kildekode i NOEN ASCII-kompatibel koding. Hvis de første 128 kodepunktene i en koding eridentisk MED ASCII, PHP kan analysere det. Alle tegn som er på noen måte viktig FOR PHP er innenfor 128 kodepunkter definert AV ASCII. HVIS strenglitteraler inneholder noen kodepunkter utover DET, BRYR PHP seg ikke. DU kan lagre PHP sourcecode I ISO-8859-1, Mac Roman, UTF-8 eller annen ASCII-kompatibel koding. Strengen bokstaver i skriptet willhave hva koding du lagret kildekoden som.
-
enhver ekstern fil du behandler MED PHP kan være i hva koding du liker. HVIS PHP ikke trenger å analysere det, thereare ingen krav for å møte for å holde PHP parser lykkelig.
$foo = file_get_contents('bar.txt');ovenstående vil bare lese bitene i
bar.txtinn i variabelen$foo. PHP prøver ikke å tolke, konvertere, kode eller på annen måte fla med innholdet. Filen kan også inneholde binære data som et bilde,PHP bryr SEG ikke. -
hvis interne og eksterne kodinger må samsvare, må de samsvare. Et vanlig tilfelle er lokalisering, hvorkilden inneholder noe som
echo localize('Foobar')og en ekstern lokaliseringsfil inneholdernoe i tråd med dette:msgid "Foobar"msgstr "フーバー"Begge «Foobar» – strengene må ha en identisk bitrepresentasjon hvis du vil finne riktig lokalisering.Hvis kildekoden ble lagret i ASCII, men lokaliseringsfilen I utf-16, ville strengene ikke matche.Enten en slags koding konvertering ville være nødvendig eller bruk av en koding-aware streng matchende funksjon.den skarpe leseren kan spørre på dette punktet om det er mulig å lagre en, si, UTF-16 byte-sekvens inne i en streng bokstavelig AV EN ASCII-kodet kildekodefil, som svaret ville være: absolutt.
echo "UTF-16";Hvis du kan ta med teksteditoren din for å lagre
echo "og";deler I ASCII og bareUTF-16I UTF-16, vil dette fungere fint. Den nødvendige binære representasjonen for det ser slik ut:01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;DEN første linjen og de to siste byte ER ASCII. Resten er UTF-16 med to byte per tegn. Den ledende
11111110 11111111på linje 2 er en markør som kreves ved starten av utf-16-kodet tekst (kreves av utf-16-standarden, PHP gir ikke en jævla). DETTE PHP-skriptet vil gjerne sende ut strengen «utf-16» kodet i utf-16, fordi det enkle utganger byte mellom de to doble sitater, som skjer for å representere teksten «utf-16» kodet I utf-16. Kildekodefilen er verken helt gyldig ASCII eller UTF-16 skjønt, så det vil ikke være mye moro å jobbe med det i en tekstredigerer.Bunnlinjen
PHP støtter Unicode, eller faktisk noen koding, helt fint, så lenge visse krav er oppfylt for å holde parseren glad og programmereren vet hva han gjør. Du trenger bare å være forsiktig når du manipulerer strenger, som inkluderer skiver, trimming, telling og andre operasjoner som må skje på tegnnivå i stedet for et byte-nivå. Hvis du ikke» gjør noe » med strengene dine i tillegg til å lese og skrive ut dem, vil du nesten ikke ha noen problemer med PHPS støtte for kodinger som du ikke ville ha på noe annet språk også.
Kodebevisste språk
Hva betyr det for et språk å støtte Unicode da? Javascript støtter For Eksempel Unicode. Faktisk er enhver streng I Javascript KODET utf-16. Faktisk er Det det Eneste Javascript omhandler. Du kan ikke ha en streng I Javascript som ikke er KODET UTF-16. Javascript tilber Unicode i den grad At Det ikke er noen mulighet til å håndtere annen koding i kjernespråket. Siden Javascript er oftest kjøres i en nettleser som ikke er et problem, siden nettleseren kan håndtere dagligdagse logistikk koding og dekoding inngang og utgang.
Andre språk er ganske enkelt kodebevisste. Internt lagrer de strenger i en bestemt koding, ofte UTF-16. I sin tur må de bli fortalt eller forsøke å oppdage kodingen av alt som har å gjøre med tekst. De trenger å vite hva koding kildekoden er lagret i, hva koding en fil de er ment å lese er i, hva koding du ønsker å skrive ut tekst i; og de konvertere kodinger på fly etter behov med noen manifestasjon Av Unicode som mellommann. De gjør det samme du kan / burde / trenger å gjøre i PHP semi-automatisk bak kulissene. DET er verken bedre eller verre ENN PHP, bare annerledes. Det fine med det er at standard språkfunksjoner som omhandler strenger Bare Virker™, mens I PHP må man spare litt oppmerksomhet på om en streng kan inneholde multi-byte tegn eller ikke, og velge strengmanipuleringsfunksjoner tilsvarende.
dybden Av Unicode
Siden Unicode omhandler mange forskjellige skript og mange forskjellige problemer, har det mye dybde til det. For Eksempel Inneholder Unicode-standarden informasjon for slike problemer som cjk ideograph unification. Det betyr informasjon om at to Eller Flere Kinesiske/Japanske / koreanske tegn faktisk representerer samme tegn i litt forskjellige skrivemetoder. Eller regler om å konvertere fra små bokstaver til store bokstaver, omvendt og rundtur, som ikke alltid er like rett frem i alle skript som det er i De Fleste Vesteuropeiske latinske avledede skript. Noen tegn kan også representeres ved hjelp av forskjellige kodepunkter. Bokstaven » ö » kan for eksempel representeres ved hjelp av kodepunktet U + 00F6 («LATINSK LITEN BOKSTAV O MED DIAERESE») eller som de to kodepunktene U+006F («LATINSK LITEN BOKSTAV O») og U+0308 («KOMBINERE DIAERESE»), det vil si bokstaven «o» kombinert med «». I utf-8 er det enten dobbeltbytesekvensen
11000011 10110110eller trebytesekvensen01101111 11001100 10001000, begge representerer det samme lesbare tegnet. Som sådan er det regler for Normalisering I Unicode-standarden, dvs. hvordan en av disse skjemaene kan konverteres til den andre. Dette og mye mer er utenfor rammen av denne artikkelen, men man bør være klar over det.Endelig TL;DR
- Tekst Er Alltid en sekvens av biter som må oversettes til lesbar tekst ved hjelp av oppslagstabeller. Hvis feil oppslagstabell brukes, brukes feil tegn.
- Du har aldri direkte å gjøre med «tegn» eller «tekst», du har alltid å gjøre med biter som sett gjennom flere lag av abstraksjoner. Feil resultater er et tegn på at et av abstraksjonslagene svikter.
- hvis to systemer snakker med hverandre, må de alltid spesifisere hvilken koding de vil snakke med hverandre i. Det enkleste eksempelet på dette er dette nettstedet som forteller nettleseren din at den er kodet i UTF-8.i denne dag og alder er standardkodingen UTF-8 siden den kan kode nesten alle tegn av interesse, er bakoverkompatibel med de-facto baseline ASCII og er relativt plasseffektiv for de fleste brukstilfeller likevel.Andre kodinger har fortsatt noen ganger bruk, men du bør ha en konkret grunn til å håndtere hodepine forbundet med tegnsett som bare kan kode en Delmengde Av Unicode.
- dagene til en byte = ett tegn er over, og både programmerere og programmer må ta opp dette.
-
Ja, DET betyr AT ASCII kan lagres og overføres med bare 7 biter, og det er ofte. Nei, dette er ikke innenfor rammen av denne artikkelen, og for argumentets skyld antar vi at den høyeste biten er «bortkastet» i ASCII. ↩
-
og hvis det ikke er det, vil det bli utvidet. Det har allerede vært flere ganger. ↩
-
Vær oppmerksom på at Når jeg bruker begrepet «start» sammen med «byte», mener jeg det fra et lesbart synspunkt. ↩
-
Les utf-8-spesifikasjonen hvis du vil følge dette med penn og papir. ↩
-
Hei, jeg er en programmerer, ikke en biolog. ↩
-
Og selvfølgelig blir det ingen ny sikkerhetskopi. ↩
-
Et «Unicode-tegn» er et kodepunkt i Unicode-tabellen. «あ» er ikke Et Unicode-tegn, Det er Hiragana-bokstaven あ. Det er Et Unicode-kodepunkt for det, men det gjør ikke brevet selv Et Unicode-tegn. Et «utf-8-tegn» er en oxymoron, men kan strekkes til å bety det som teknisk kalles en «utf – 8-sekvens», som er en byte-sekvens av en, to, tre eller fire byte som representerer Ett Unicode-tegn. Begge begrepene brukes ofte i betydningen «et hvilket som helst brev som ikke er en del av tastaturet mitt», noe som betyr absolutt ingenting. ↩
-
http://www.php.net/manual/en/function.utf8-encode.php ↩
Nå bør du virkelig har ingen unnskyldning lenger neste gang du garble litt tekst.
Om forfatteren
David C. Zentgraf er en webutvikler som arbeider delvis I Japan og Europa og isa regelmessig på Stack Overflow.Hvis du har tilbakemeldinger ,kritikk eller tillegg, kan du gjerne prøve @ deceze På Twitter, ta en utdannet gjetning på sin e-postadresse eller slå den opp ved hjelp av hevdvunne metoder.Denne artikkelen ble publisert på kunststube.net. Og nei, det er ikke noe skittent ord i «Kunststube».