Ciò che ogni programmatore assolutamente, positivamente ha bisogno di sapere su codifiche e set di caratteri per lavorare con il testo
Se si ha a che fare con il testo in un computer, è necessario conoscere le codifiche. Periodo. Sì, anche se si sta solo inviando e-mail. Anche se si sta solo ricevendo e-mail. Non hai bisogno di capire ogni ultimo dettaglio, ma devi almeno sapere di cosa tratta questa intera “codifica”. E la buona notizia prima: mentre l’argomento può diventare disordinato e confuso, l’idea di base è davvero, davvero semplice.
Questo articolo riguarda le codifiche e i set di caratteri. Un articolo di Joel Spolsky intitolato Il minimo assoluto Ogni sviluppatore di software assolutamente, positivamente deve conoscere Unicode e set di caratteri (Senza scuse!) è una bella introduzione all’argomento e mi piace molto leggerlo ogni tanto. Esito a fare riferimento alle persone che hanno difficoltà a comprendere i problemi di codifica, poiché, mentre è divertente, è piuttosto leggero sui dettagli tecnici reali. Spero che questo articolo possa far luce su cosa sia esattamente una codifica e sul perché tutto il tuo testo si rovini quando meno ne hai bisogno. Questo articolo è rivolto agli sviluppatori (con particolare attenzione a PHP), ma qualsiasi utente di computer dovrebbe essere in grado di trarne beneficio.
Ottenere le basi dritto
Tutti sono consapevoli di questo a un certo livello, ma in qualche modo questa conoscenza sembra improvvisamente scomparire in una discussione sul testo, quindi cerchiamo di farlo uscire prima: Un computer non può memorizzare “lettere”, “numeri”, “immagini” o qualsiasi altra cosa. L’unica cosa che può memorizzare e lavorare con i bit. Un bit può avere solo due valori: yes o notrue o false1 o 0 o qualsiasi altra cosa che si desidera chiamare questi due valori. Poiché un computer funziona con l’elettricità, un bit” effettivo ” è un blip di elettricità che c’è o non c’è. Per gli umani, questo è solitamente rappresentato usando 1 e 0 e continuerò con questa convenzione in questo articolo.
Per usare i bit per rappresentare qualsiasi cosa oltre ai bit, abbiamo bisogno di regole. Dobbiamo convertire una sequenza di bit in qualcosa come lettere, numeri e immagini usando uno schema di codifica o codifica in breve. Come questa:
01100010 01101001 01110100 01110011b i t sIn questa codifica, 01100010 sta per la lettera “b”, 01101001 per la lettera “i”, 01110100 sta per “t” e 01110011 per “s”. Una certa sequenza di bit sta per una lettera e una lettera sta per una certa sequenza di bit. Se riesci a tenerlo in testa per 26 lettere o sei davvero veloce con la ricerca di cose in un tavolo, potresti leggere bit come un libro.
Lo schema di codifica sopra riportato è ASCII. Una stringa di1s e0s è suddivisa in parti di otto bit ciascuna (un byte in breve). La codifica ASCII specifica una tabella che traduce i byte in lettere leggibili dall’uomo. Ecco un breve estratto di quel tavolo:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable caratteri specificati nella tabella ASCII, comprese le lettere dalla A alla Z sia in maiuscolo che in minuscolo, i numeri da 0 a 9, una manciata di segni di punteggiatura e caratteri come il simbolo del dollaro, la e commerciale e pochi altri. Include anche 33 valori per cose come spazio, avanzamento riga, scheda, backspace e così via. Questi non sono stampabili di per sé, ma ancora visibili in qualche forma e utili agli esseri umani direttamente. Un certo numero di valori sono utili solo a un computer, come i codici per indicare l’inizio o la fine di un testo. In totale ci sono 128 caratteri definito nella codifica ASCII, che è un bel numero tondo (per le persone che lottano con il computer), in quanto utilizza tutte le possibili combinazioni di 7 bit (000000000000010000010 attraverso 1111111).1
E il gioco è fatto, il modo di rappresentare il testo leggibile usando solo 1s e 0 s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100“Hello World”
Termini importanti
Per codificare qualcosa in ASCII, seguire la tabella da destra a sinistra, sostituendo le lettere con i bit. Per decodificare una stringa di bit in caratteri leggibili, seguire la tabella da sinistra a destra, sostituendo i bit con le lettere.
codificare|enkōd/
verbo
convertire in una forma codificatacodice|kōd /
sostantivo
un sistema di parole, lettere, figure o altri simboli sostituiti da altre parole, lettere, ecc.
Codificare significa usare qualcosa per rappresentare qualcos’altro. Una codifica è l’insieme di regole con cui convertire qualcosa da una rappresentazione all’altra.
Altri termini che meritano chiarimenti in questo contesto:
set di caratteri, charset L’insieme di caratteri che possono essere codificati. “La codifica ASCII comprende un set di caratteri di 128 caratteri.”Essenzialmente sinonimo di “codifica”. code page Una “pagina” di codici che mappano un carattere a una sequenza di numeri o bit. Alias “il tavolo”. Essenzialmente sinonimo di “codifica”. stringa Una stringa è un gruppo di elementi messi insieme. Una stringa di bit è un gruppo di bit, come01010011
. Una stringa di caratteri è un gruppo di caratteri,like this. Sinonimo di “sequenza”.
Binario, ottale, decimale, esadecimale
Ci sono molti modi per scrivere numeri. 10011111 in binario è 237 in ottale è 159 in decimale è 9F in esadecimale. Rappresentano tutti lo stesso valore, ma l’esadecimale è più breve e più facile da leggere rispetto al binario. Continuerò con il binario in questo articolo per ottenere il punto migliore e risparmiare al lettore uno strato di astrazione. Non allarmarti nel vedere i codici dei caratteri di cui ad altre notazioni altrove, è la stessa cosa.
Excusez-moi?
Ora che sappiamo di cosa stiamo parlando, diciamo solo che: 95 caratteri non sono molto quando si tratta di lingue. Copre le basi dell’inglese, ma per quanto riguarda la scrittura di una lettera osé in francese? Uno Straßenübergangsänderungsgesetz in tedesco? Un invito a uno smörgåsbord in svedese? Beh, non puoi, non in ASCII. Non ci sono specifiche su come rappresentare una qualsiasi delle lettere é, ß, ü, ä, ö o å in ASCII, quindi non è possibile utilizzarle.
“Ma guardalo”, hanno detto gli europei, “in un computer comune con 8 bit al byte, ASCII sta sprecando un intero bit che è sempre impostato su 0! Possiamo usare quel bit per spremere un intero ‘ nother 128 valori in quella tabella!”E così hanno fatto. Ma anche così, ci sono più di 128 modi per accarezzare, tagliare, tagliare e punteggiare una vocale. Non tutte le variazioni di lettere e scarabocchi utilizzati in tutte le lingue europee possono essere rappresentati nella stessa tabella con un massimo di 256 valori. Quindi, ciò che il mondo ha finito con è una ricchezza di schemi di codifica, standard, standard de-facto e half-standard che coprono tutti un sottoinsieme diverso di caratteri. Qualcuno aveva bisogno di scrivere un documento sullo svedese in ceco, ha scoperto che nessuna codifica copriva entrambe le lingue e ne inventava una. O almeno così immagino sia andato innumerevoli volte.
E non dimenticare russo, hindi, arabo, ebraico, coreano e tutte le altre lingue attualmente in uso attivo su questo pianeta. Per non parlare di quelli non più in uso. Una volta risolto il problema di come scrivere documenti in lingua mista in tutte queste lingue, provare voi stessi su cinese. O giapponese. Entrambi contengono decine di migliaia di caratteri. Hai 256 valori possibili per un byte composto da 8 bit. Vada!
Codifiche multi-byte
Per creare una tabella che associa i caratteri alle lettere per una lingua che utilizza più di 256 caratteri, un byte semplicemente non è sufficiente. Utilizzando due byte (16 bit), è possibile codificare 65.536 valori distinti. BIG-5 è una codifica a doppio byte. Invece di rompere una stringa di bit in blocchi di otto, la spezza in blocchi di 16 e ha una tabella grande (voglio dire, GRANDE) che specifica a quale carattere si associa ogni combinazione di bit. BIG-5 nella sua forma di base copre per lo più i caratteri cinesi tradizionali. GB18030 è un’altra codifica che essenzialmente fa la stessa cosa, ma include sia i caratteri cinesi tradizionali che quelli semplificati. E prima di chiedere, sì, ci sono codifiche che coprono solo cinese semplificato. Non possiamo avere solo una codifica ora, vero?
Ecco un piccolo estratto dalla tabella GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin caratteri), ma alla fine è ancora un altro formato di codifica specializzato tra molti.
Unicode per la confusione

qualcuno si è Finalmente avuto abbastanza di disordine e di cui per forgiare un anello per legare tutti di creare uno standard di codifica per unificare tutti gli standard di codifica. Questo standard è Unicode. Fondamentalmente definisce una tabella ginormous di 1.114.112 punti di codice che possono essere utilizzati per tutti i tipi di lettere e simboli. Questo è molto per codificare tutti i personaggi europei, mediorientali, estremo-orientali, meridionali, settentrionali, occidentali, pre-storici e futuri che l’umanità conosce.2 Utilizzando Unicode, è possibile scrivere un documento contenente praticamente qualsiasi lingua utilizzando qualsiasi carattere è possibile digitare in un computer. Questo era impossibile o molto difficile da ottenere prima che arrivasse Unicode. C’è anche una sezione non ufficiale per Klingon in Unicode. In effetti, Unicode è abbastanza grande da consentire aree non ufficiali di uso privato.
Quindi, quanti bit usa Unicode per codificare tutti questi caratteri? Nessuno. Perché Unicode non è una codifica.
Confuso? Molte persone sembrano essere. Unicode definisce innanzitutto una tabella di punti di codice per i caratteri. Questo è un modo elegante di dire “65 sta per A, 66 sta per B e 9,731 sta per ☃” (seriamente, lo fa). Il modo in cui questi punti di codice sono effettivamente codificati in bit è un argomento diverso. Per rappresentare 1.114.112 valori diversi, due byte non sono sufficienti. Tre byte sono, ma tre byte sono spesso scomodi da lavorare, quindi quattro byte sarebbero il minimo comodo. Ma, a meno che tu non stia effettivamente usando il cinese o alcuni degli altri caratteri con grandi numeri che richiedono molti bit per codificare, non userai mai un pezzo enorme di quei quattro byte. Se la lettera “A”era sempre codificata in 00000000 00000000 00000000 01000001,” B”sempre in 00000000 00000000 00000000 01000010 e così via, qualsiasi documento si gonfierebbe fino a quattro volte la dimensione necessaria.
Per ottimizzare questo, ci sono diversi modi per codificare i punti di codice Unicode in bit. UTF-32 è una codifica che codifica tutti i punti di codice Unicode usando 32 bit. Cioè, quattro byte per carattere. È molto semplice, ma spesso spreca molto spazio. UTF-16 e UTF-8 sono codifiche a lunghezza variabile. Se un carattere può essere rappresentato usando un singolo byte (perché il suo punto di codice è un numero molto piccolo), UTF-8 lo codificherà con un singolo byte. Se richiede due byte, userà due byte e così via. Ha modi elaborati per utilizzare i bit più alti in un byte per segnalare quanti byte è costituito da un carattere. Questo può risparmiare spazio, ma può anche sprecare spazio se questi bit di segnale devono essere usati spesso. UTF-16 è nel mezzo, usando almeno due byte, crescendo fino a quattro byte se necessario.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
E questo è tutto ciò che c’è da fare. Unicode è una grande tabella che associa i caratteri ai numeri e le diverse codifiche UTF specificano come questi numeri sono codificati come bit. Nel complesso, Unicode è ancora un altro schema di codifica. Non c’è niente di speciale, sta solo cercando di coprire tutto pur essendo efficiente. E questa è una buona cosa.™
Punti di codice
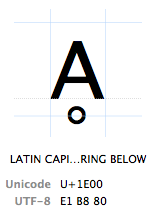
I caratteri sono indicati dal loro “Punto di codice Unicode”. I punti di codice Unicode sono scritti in esadecimale (per mantenere i numeri più brevi), preceduti da un “U+” (questo è proprio quello che fanno, non ha altro significato che “questo è un punto di codice Unicode”). Il carattere Ḁ ha il punto di codice Unicode U + 1E00. In altre parole (decimali), è il 7680 ° carattere della tabella Unicode. È ufficialmente chiamato “LETTERA MAIUSCOLA LATINA A CON ANELLO SOTTO”.
TL;DR
Un riassunto di tutto quanto sopra: Qualsiasi carattere può essere codificato in molte sequenze di bit diverse e qualsiasi particolare sequenza di bit può rappresentare molti caratteri diversi, a seconda della codifica utilizzata per leggerli o scriverli. Il motivo è semplicemente perché codifiche diverse utilizzano numeri diversi di bit per caratteri e valori diversi per rappresentare caratteri diversi.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows latino 1 | 01000110 11111000 11110110 |
| Føö | Mac Romano | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
idee sbagliate, le confusioni e problemi
detto questo, veniamo ai problemi reali vissute da molti utenti e programmatori di ogni giorno, come quei problemi si riferiscono a tutti i precedenti e che la loro soluzione. Il problema più grande di tutti è:
Perché in nome di Dio i miei personaggi sono confusi?!
ÉGÉìÉRÅ;Se quel$string era in una codifica a byte singolo, questo ci darebbe il primo carattere. Ma solo perché ” carattere “coincide con” byte ” in una codifica a byte singolo. PHP ci dà semplicemente il primo byte senza pensare ai “caratteri”. Le stringhe sono sequenze di byte per PHP, niente di più, niente di meno. Tutta questa roba di “carattere leggibile” è una cosa umana e a PHP non importa.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !Lo stesso vale per molte funzioni standard comesubstrstrpostrim e così via. Il non supporto sorge se c’è una discrepanza tra la lunghezza di un byte e un carattere.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Usando$string sulla stringa sopra, di nuovo, ci darà il primo byte, che è11100110. In altre parole, un terzo del carattere a tre byte “漢”. 11100110 è, di per sé, una sequenza UTF-8 non valida, quindi la stringa è ora interrotta. Se ne hai voglia, potresti provare a interpretarlo in qualche altra codifica dove 11100110 rappresenta un carattere valido, che si tradurrà in un carattere casuale. Buon divertimento, ma non usarlo in produzione.
E questo è in realtà tutto ciò che c’è da fare. “PHP non supporta nativamente Unicode” significa semplicemente che la maggior parte delle funzioni PHP assume un byte = un carattere, il che può portare a tagliare caratteri multi-byte a metà o calcolare la lunghezza delle stringhe in modo errato se si utilizza ingenuamente funzioni non multi-byte-aware su stringhe multi-byte. Ciò non significa che non è possibile utilizzare Unicode in PHP o che ogni stringa Unicode deve essere benedetta da utf8_encode o da altre sciocchezze del genere.
Fortunatamente, c’è l’estensione Multibyte String, che replica tutte le importanti funzioni di stringa in modo consapevole multi-byte. L’utilizzo dimb_substr($string, 0, 1, 'UTF-8') sulla stringa precedente restituisce correttamente11100110 10111100 10100010, che è l’intero carattere “di”. Poiché le funzionimb_ ora devono effettivamente pensare a cosa stanno facendo, devono sapere su quale codifica stanno lavorando. Pertanto ogni funzionemb_ accetta anche un parametro$encoding. In alternativa, questo può essere impostato globalmente per tutte le funzioni mb_ utilizzando mb_internal_encoding.
Usare e abusare della gestione delle codifiche di PHP
L’intero problema del supporto (non)di PHP per Unicode è che non gli importa. Le stringhe sono sequenze di byte per PHP. Quali byte in particolare non importa. PHP non fa nulla con le stringhe tranne tenerle memorizzate in memoria. PHP semplicemente non ha alcun concetto di caratteri o codifiche. E a meno che non cerchi di manipolare le stringhe, non ne ha bisogno; tiene solo byte che possono o non possono essere interpretati come caratteri da qualcun altro. L’unico requisito PHP ha delle codifiche è che il codice sorgente PHP deve essere salvato in una codifica compatibile ASCII. Il parser PHP sta cercando determinati caratteri che gli dicono cosa fare. $00100100) segnala l’inizio di una variabile, =00111101) un’assegnazione, "00100010) l’inizio e la fine di una stringa, e così via. Qualsiasi altra cosa che non abbia alcun significato speciale per il parser viene semplicemente presa come una sequenza di byte letterale. Ciò include qualsiasi cosa tra virgolette, come discusso sopra. Ciò significa quanto segue:
-
Non è possibile salvare il codice sorgente PHP in una codifica ASCII incompatibile. Ad esempio, in UTF-16 un
"è codificato come00000000 00100010. Per PHP, che cerca di leggere tutto come ASCII, questo è unNULbyte seguito da un".PHP probabilmente otterrà un singhiozzo se ogni altro carattere che trova è un byteNUL. -
È possibile salvare il codice sorgente PHP in qualsiasi codifica ASCII-compatibile. Se i primi 128 punti di codice di una codifica sono identici ad ASCII, PHP pu analizzarlo. Tutti i caratteri che sono in qualche modo significativi per PHP sono all’interno dei 128 codepoint definiti da ASCII. Se i letterali di stringa contengono punti di codice oltre a ciò, a PHP non importa. È possibile salvare il codice sorgente PHP in ISO-8859-1, Mac Roman, UTF-8 o qualsiasi altra codifica compatibile con ASCII. I letterali stringa nel tuo script willhave qualsiasi codifica hai salvato il tuo codice sorgente come.
-
Qualsiasi file esterno elaborato con PHP può essere in qualsiasi codifica che ti piace. Se PHP non ha bisogno di analizzarlo, non ci sono requisiti da soddisfare per mantenere il parser PHP felice.
$foo = file_get_contents('bar.txt');Quanto sopra leggerà semplicemente i bit in
bar.txtnella variabile$foo. PHP non cerca di interpretare, convertire, codificare o comunque giocherellare con i contenuti. Il file può anche contenere dati binari come un’immagine,a PHP non importa. -
Se le codifiche interne ed esterne devono corrispondere, devono corrispondere. Un caso comune è la localizzazione, doveil codice sorgente contiene qualcosa come
echo localize('Foobar')e un file di localizzazione esterno contienequalcosa di questo:msgid "Foobar"msgstr "フーバー"Entrambe le stringhe “Foobar” devono avere una rappresentazione bit identica se si desidera trovare la localizzazione corretta.Se il codice sorgente è stato salvato in ASCII ma il file di localizzazione in UTF-16, le stringhe non corrisponderebbero.Sarebbe necessaria una sorta di conversione di codifica o l’uso di una funzione di corrispondenza delle stringhe consapevole della codifica.
Il lettore astuto potrebbe chiedere a questo punto se è possibile salvare una sequenza di byte UTF-16 all’interno di una stringa letterale di un file di codice sorgente codificato ASCII, a cui la risposta sarebbe: assolutamente.
echo "UTF-16";Se puoi portare il tuo editor di testo per salvare le partiecho "e";in ASCII e soloUTF-16 in UTF-16, questo funzionerà perfettamente. La rappresentazione binaria necessaria per questo è simile a questa:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ; La prima riga e gli ultimi due byte sono ASCII. Il resto è UTF-16 con due byte per carattere. Il principale 11111110 11111111 sulla riga 2 è un marker richiesto all’inizio del testo codificato UTF-16 (richiesto dallo standard UTF-16, PHP non gliene frega niente). Questo script PHP emetterà felicemente la stringa” UTF-16 “codificata in UTF-16, perché emette semplicemente i byte tra i due doppi apici, che sembra rappresentare il testo” UTF-16 ” codificato in UTF-16. Il file del codice sorgente non è ASCII né UTF-16 completamente valido, quindi lavorare con esso in un editor di testo non sarà molto divertente.
Bottom line
PHP supporta Unicode, o in effetti qualsiasi codifica, va bene, purché siano soddisfatti determinati requisiti per mantenere il parser felice e il programmatore sappia cosa sta facendo. Devi solo stare attento quando manipoli le stringhe, che includono l’affettatura, il taglio, il conteggio e altre operazioni che devono avvenire a livello di carattere piuttosto che a livello di byte. Se non stai “facendo nulla” con le tue stringhe oltre a leggerle e inviarle, difficilmente avrai problemi con il supporto di PHP di codifiche che non avresti in nessun’altra lingua.
Encoding-aware languages
Cosa significa allora per una lingua supportare Unicode? Javascript per esempio supporta Unicode. In effetti, qualsiasi stringa in Javascript è codificata in UTF-16. In realtà, è l’unica cosa che Javascript si occupa. Non è possibile avere una stringa in Javascript che non sia codificata UTF-16. Javascript adora Unicode nella misura in cui non esiste alcuna possibilità di gestire qualsiasi altra codifica nel linguaggio principale. Poiché Javascript è più spesso eseguito in un browser che non è un problema, dal momento che il browser in grado di gestire la logistica banale di codifica e decodifica di input e output.
Altre lingue sono semplicemente codificanti. Internamente memorizzano le stringhe in una particolare codifica, spesso UTF-16. A loro volta devono essere informati o cercare di rilevare la codifica di tutto ciò che ha a che fare con il testo. Hanno bisogno di sapere in quale codifica viene salvato il codice sorgente, in quale codifica è contenuto un file che dovrebbero leggere, in quale codifica si desidera produrre il testo; e convertono le codifiche al volo se necessario con qualche manifestazione di Unicode come intermediario. Stanno facendo la stessa cosa che puoi/dovresti/devi fare in PHP semi-automaticamente dietro le quinte. Non è né migliore né peggiore di PHP, solo diverso. La cosa bella è che le funzioni del linguaggio standard che si occupano di stringhe funzionano solo™, mentre in PHP è necessario prestare attenzione al fatto che una stringa possa contenere caratteri multi-byte o meno e scegliere le funzioni di manipolazione delle stringhe di conseguenza.
Le profondità di Unicode
Poiché Unicode si occupa di molti script diversi e molti problemi diversi, ha molta profondità. Ad esempio, lo standard Unicode contiene informazioni per problemi come l’unificazione dell’ideografo CJK. Ciò significa che due o più caratteri cinesi / giapponesi / coreani rappresentano effettivamente lo stesso carattere in metodi di scrittura leggermente diversi. O regole sulla conversione da minuscole a maiuscole, viceversa e andata e ritorno, che non è sempre così semplice in tutti gli script come nella maggior parte degli script di derivazione latina dell’Europa occidentale. Alcuni caratteri possono anche essere rappresentati utilizzando diversi punti di codice. La lettera “ö”ad esempio può essere rappresentata usando il punto di codice U+00F6 (“LETTERA MINUSCOLA LATINA O CON DIAERESI”) o come i due punti di codice U+006F (“LETTERA MINUSCOLA LATINA O”) e U+0308 (“COMBINAZIONE DI DIAERESI”), cioè la lettera” o “combinata con””. In UTF-8 è la sequenza a doppio byte 11000011 10110110 o la sequenza a tre byte 01101111 11001100 10001000, che rappresentano entrambi lo stesso carattere leggibile. Come tale, ci sono regole che regolano la normalizzazione all’interno dello standard Unicode, cioè come una di queste forme può essere convertita nell’altra. Questo e molto altro è al di fuori dello scopo di questo articolo, ma si dovrebbe essere consapevoli di esso.
Final TL;DR
- Il testo è sempre una sequenza di bit che deve essere tradotta in testo leggibile usando le tabelle di ricerca. Se viene utilizzata la tabella di ricerca errata, viene utilizzato il carattere errato.
- In realtà non hai mai a che fare direttamente con “caratteri” o “testo”, hai sempre a che fare con bit come visto attraverso diversi livelli di astrazioni. I risultati errati sono un segno del fallimento di uno dei livelli di astrazione.
- Se due sistemi stanno parlando tra loro, hanno sempre bisogno di specificare in quale codifica vogliono parlare tra loro. L’esempio più semplice di questo è questo sito web che dice al tuo browser che è codificato in UTF-8.
- In questo giorno ed età, la codifica standard è UTF-8 poiché può codificare praticamente qualsiasi carattere di interesse, è retrocompatibile con la baseline ASCII de-facto ed è relativamente efficiente nello spazio per la maggior parte dei casi d’uso.
- Altre codifiche hanno ancora occasionalmente i loro usi, ma dovresti avere una ragione concreta per voler affrontare i mal di testa associati ai set di caratteri che possono codificare solo un sottoinsieme di Unicode.
- I giorni di one byte = one character sono finiti e sia i programmatori che i programmi devono recuperare il ritardo.
Ora si dovrebbe davvero non avere più scuse la prossima volta che si garble qualche testo.
-
Sì, ciò significa che ASCII può essere memorizzato e trasferito usando solo 7 bit e spesso lo è. No, questo non rientra nell’ambito di questo articolo e per motivi di discussione assumeremo che il bit più alto sia “sprecato” in ASCII. ↩
-
E se non lo è, verrà esteso. È già stato diverse volte. note
-
Si prega di notare che quando sto usando il termine “starting” insieme a “byte”, lo intendo dal punto di vista leggibile dall’uomo. Per
-
Esaminare la specifica UTF-8 se si desidera seguire questo con carta e penna. Hey
-
Ehi, sono un programmatore, non un biologo. ↩
-
E ovviamente non ci saranno backup recenti. A
-
Un “carattere Unicode” è un punto di codice nella tabella Unicode. “あ” non è un carattere Unicode, è la lettera Hiragana あ. C’è un punto di codice Unicode per questo, ma ciò non rende la lettera stessa un carattere Unicode. Un ” carattere UTF-8 “è un ossimoro, ma può essere allungato per significare ciò che è tecnicamente chiamato” sequenza UTF-8″, che è una sequenza di byte di uno, due, tre o quattro byte che rappresentano un carattere Unicode. Entrambi i termini sono spesso usati nel senso di “qualsiasi lettera che non fa parte della mia tastiera”, il che non significa assolutamente nulla. ↩
-
http://www.php.net/manual/en/function.utf8-encode.phpDavid
Informazioni sull’autore
David C. Zentgraf è uno sviluppatore web che lavora in parte in Giappone e in Europa e isa regolare su Stack Overflow.Se si dispone di feedback, critiche o aggiunte,non esitate a provare @deceze su Twitter, prendere una supposizione istruita al suo indirizzo e-mail o cercarlo utilizzando metodi di tempo onorato.Questo articolo è stato pubblicato su kunststube.net. E no, non c’è parola sporca in “Kunststube”.