KDnuggets
Para cualquier lenguaje, la sintaxis y la estructura generalmente van de la mano, donde un conjunto de reglas, convenciones y principios específicos gobiernan la forma en que las palabras se combinan en frases; las frases se combinan en cláusulas; y las cláusulas se combinan en oraciones. Hablaremos específicamente sobre la sintaxis y la estructura del idioma inglés en esta sección. En inglés, las palabras generalmente se combinan para formar otras unidades constituyentes. Estos componentes incluyen palabras, frases, cláusulas y oraciones. Considerando una frase ,» El zorro marrón es rápido y está saltando sobre el perro perezoso», está hecha de un montón de palabras y solo mirar las palabras por sí solas no nos dice mucho.

Un montón de palabras desordenadas no transmiten mucha información
El conocimiento sobre la estructura y la sintaxis del lenguaje es útil en muchas áreas como el procesamiento de texto, la anotación y el análisis para operaciones posteriores, como la clasificación de texto o el resumen. A continuación se mencionan las técnicas de análisis típicas para comprender la sintaxis del texto.
- Etiquetado de partes del habla (POS)
- Análisis superficial o Fragmentado
- Análisis de constituyentes
- Análisis de dependencias
Veremos todas estas técnicas en secciones posteriores. Teniendo en cuenta nuestra oración de ejemplo anterior «El zorro marrón es rápido y está saltando sobre el perro perezoso», si tuviéramos que anotarlo usando etiquetas POS básicas, se vería como la siguiente figura.

Etiquetado POS para una oración
Por lo tanto, una oración típicamente sigue una estructura jerárquica que consta de los siguientes componentes,
oración → cláusulas → frases → palabras
Etiquetar Partes del habla
Las partes del habla (POS) son categorías léxicas específicas a las que se asignan las palabras, en función de su contexto sintáctico y función. Por lo general, las palabras pueden caer en una de las siguientes categorías principales.
- N (oun): Esto generalmente denota palabras que representan algún objeto o entidad, que puede ser viviente o no viviente. Algunos ejemplos serían zorro, perro , libro, etc. El símbolo de etiqueta POS para sustantivos es N.
- V(erb): Los verbos son palabras que se usan para describir ciertas acciones, estados u ocurrencias. Hay una amplia variedad de subcategorías adicionales, como verbos auxiliares, reflexivos y transitivos (y muchos más). Algunos ejemplos típicos de verbos serían correr, saltar, leer y escribir . El símbolo de etiqueta POS para verbos es V.
- Adj(ectivo): Los adjetivos son palabras que se usan para describir o calificar otras palabras, típicamente sustantivos y frases nominales. La frase flor hermosa tiene el sustantivo (N) flor que se describe o califica usando el adjetivo (ADJETIVO) hermosa . El símbolo de etiqueta POS para adjetivos es ADJ .
- Adv (erb): Los adverbios generalmente actúan como modificadores para otras palabras, incluidos sustantivos, adjetivos, verbos u otros adverbios. La frase very beautiful flower tiene el adverbio (ADV) very, que modifica el adjetivo (ADJ) beautiful, indicando el grado en que la flor es hermosa. El símbolo de etiqueta POS para adverbios es ADV.
Además de estas cuatro categorías principales de partes del habla , hay otras categorías que ocurren con frecuencia en el idioma inglés. Estos incluyen pronombres, preposiciones, interjecciones, conjunciones, determinantes, y muchos otros. Además, cada etiqueta POS como el sustantivo (N) puede subdividirse en categorías como sustantivos singulares(NN), sustantivos propios singulares (NNP) y sustantivos plurales (NNS).
El proceso de clasificar y etiquetar etiquetas POS para palabras llamadas etiquetado de partes del habla o etiquetado POS . Las etiquetas POS se utilizan para anotar palabras y representar sus POS, lo que es realmente útil para realizar análisis específicos, como reducir los sustantivos y ver cuáles son los más prominentes, desambiguación del sentido de las palabras y análisis gramatical. Aprovecharemos nltk y spacy, que generalmente usan la notación Penn Treebank para el etiquetado de POS.
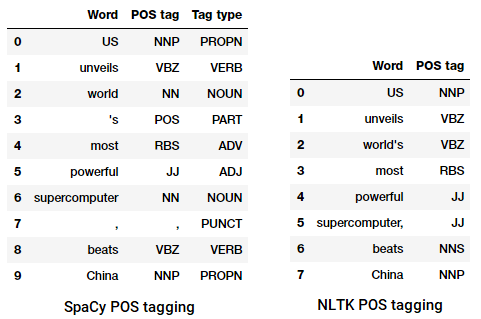
etiquetado POS de titulares de noticias
podemos ver que cada una de estas bibliotecas tratar de tokens en su propio camino y asignar etiquetas específicas para ellos. Basado en lo que vemos, spacy parece ser un poco mejor que el nltk.
Análisis superficial o segmentación
Basado en la jerarquía que representamos anteriormente, grupos de palabras componen frases. Hay cinco categorías principales de frases:
- Frase nominal (NP): Estas son frases en las que un sustantivo actúa como la palabra principal. Las frases nominales actúan como sujeto u objeto de un verbo.
- Frase verbal (VP) : Estas frases son unidades léxicas que tienen un verbo que actúa como la palabra principal. Por lo general, hay dos formas de frases verbales. Una forma tiene los componentes del verbo, así como otras entidades como sustantivos, adjetivos o adverbios como partes del objeto.
- Frase adjetiva (ADJP) : Estas son frases con un adjetivo como palabra principal. Su función principal es describir o calificar sustantivos y pronombres en una oración, y se colocarán antes o después del sustantivo o pronombre.
- Frase adverbial (ADVP) : Estas frases actúan como adverbios ya que el adverbio actúa como la palabra principal de la frase. Las frases adverbiales se usan como modificadores para sustantivos, verbos o adverbios, proporcionando más detalles que los describen o califican.
- Frase preposicional (PP): Estas frases generalmente contienen una preposición como la palabra principal y otros componentes léxicos como sustantivos, pronombres, etc. Actúan como un adjetivo o adverbio que describe otras palabras o frases.
El análisis superficial, también conocido como análisis ligero o chunking, es una técnica popular de procesamiento de lenguaje natural para analizar la estructura de una oración para dividirla en sus componentes más pequeños (que son símbolos como palabras) y agruparlos en frases de nivel superior. Esto incluye etiquetas POS, así como frases de una oración.
Un ejemplo de análisis superficial que representa anotaciones de frases de mayor nivel
Aprovecharemos el corpus conll2000 para entrenar nuestro modelo de analizador superficial. Este corpus está disponible en nltk con anotaciones de fragmentos y utilizaremos alrededor de 10K registros para entrenar nuestro modelo. Una oración anotada de muestra se representa de la siguiente manera.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
De la salida anterior, puede ver que nuestros puntos de datos son oraciones que ya están anotadas con frases y metadatos de etiquetas POS que serán útiles para entrenar nuestro modelo de analizador sintáctico superficial. Aprovecharemos dos funciones de utilidad de fragmentación, tree2conlltags, para obtener triples de etiquetas de palabra, etiqueta y fragmento para cada token, y conlltags2tree para generar un árbol de análisis a partir de estos triples de token. Usaremos estas funciones para entrenar a nuestro analizador sintáctico. A continuación se muestra una muestra.
El fragmento el uso de etiquetas de la IOB formato. Esta notación representa el Interior, el Exterior y el Principio. El prefijo B antes de una etiqueta indica que es el comienzo de un fragmento, y el prefijo I indica que está dentro de un fragmento. La etiqueta O indica que el token no pertenece a ningún fragmento. La etiqueta B siempre se usa cuando hay etiquetas posteriores del mismo tipo que la siguen sin la presencia de etiquetas O entre ellas.
Ahora definiremos una función conll_tag_ chunks() para extraer etiquetas POS y fragmentos de oraciones con anotaciones fragmentadas y una función llamada combined_taggers() para entrenar a múltiples etiquetadores con etiquetadores de retroceso (por ejemplo, etiquetadores de unigrama y bigrama)
Ahora definiremos una clase NGramTagChunker que tomará oraciones etiquetadas como entrada de entrenamiento, obtendrá sus triples WTC (palabra, etiqueta POS, etiqueta de fragmento) y entrenará a un BigramTagger con un UnigramTagger como etiquetador de retroceso. También vamos a definir un parse() función para realizar análisis superficial sobre nuevas frases
El
UnigramTaggerBigramTagger, yTrigramTaggerson clases que heredan de la clase baseNGramTagger, que a su vez hereda de la etiquetaContextTaggerclase, que hereda de la etiquetaSequentialBackoffTaggerclase.
vamos a utilizar esta clase para entrenar en el conll2000 fragmentada train_data y evaluar el desempeño del modelo en la etiqueta test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
Nuestra chunking modelo obtiene una precisión de alrededor del 90%, que es bastante bueno! Ahora aprovechemos este modelo para analizar de forma superficial y fragmentar nuestro ejemplo de titular de artículo de noticias que usamos anteriormente, «EE.UU. revela la supercomputadora más poderosa del mundo, supera a China».
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
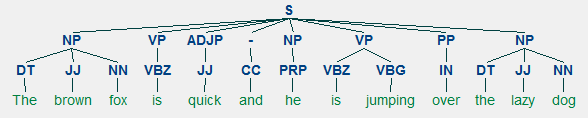
Así que usted puede ver que se ha identificado dos frases (NP) y una frase verbal (VP) en el artículo de noticias. Las etiquetas POS de cada palabra también son visibles. También podemos visualizar esto en forma de árbol de la siguiente manera. Es posible que deba instalar ghostscript en caso de que nltk genere un error.

Titular de noticias analizado poco profundo
La salida anterior da una buena sensación de estructura después de analizar poco profundo el titular de noticias.
Análisis de constituyentes
Las gramáticas basadas en constituyentes se utilizan para analizar y determinar los constituyentes de una oración. Estas gramáticas se pueden usar para modelar o representar la estructura interna de las oraciones en términos de una estructura jerárquicamente ordenada de sus constituyentes. Todas y cada una de las palabras generalmente pertenecen a una categoría léxica específica en el caso y forman la palabra principal de diferentes frases. Estas frases se forman en base a reglas llamadas reglas de estructura de frases.
Las reglas de estructura de frases forman el núcleo de las gramáticas de constituyentes, porque hablan de sintaxis y reglas que gobiernan la jerarquía y el orden de los diversos constituyentes en las oraciones. Estas normas se refieren principalmente a dos cosas.
- Determinan qué palabras se usan para construir las frases o componentes.
- Determinan cómo necesitamos ordenar estos componentes juntos.
La representación genérica de una regla de estructura de frase es S → AB, que representa que la estructura S consta de constituyentes A y B , y el orden es A seguido de B . Si bien hay varias reglas (consulte el Capítulo 1, Página 19: Análisis de texto con Python, si desea profundizar más), la regla más importante describe cómo dividir una oración o una cláusula. La regla de estructura de frases denota una división binaria para una oración o una cláusula como S → NP VP donde S es la oración o cláusula, y se divide en el sujeto, denotado por la frase nominal (NP) y el predicado, denotado por la frase verbal (VP).
Se puede construir un analizador de constituyentes basado en dichas gramáticas / reglas, que generalmente están disponibles colectivamente como gramática libre de contexto (CFG) o gramática estructurada por frases. El analizador procesará las oraciones de entrada de acuerdo con estas reglas, y ayudará a construir un árbol de análisis.
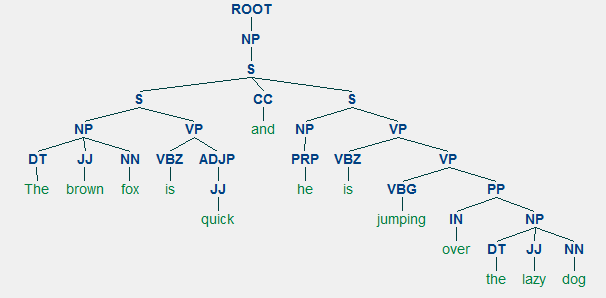
Un ejemplo de la unidad constitutiva de análisis muestra una estructura jerárquica anidada
vamos a utilizar la etiqueta nltk y el StanfordParser aquí para generar analizar los árboles.
Requisitos previos: Descargue el analizador oficial de Stanford desde aquí, que parece funcionar bastante bien. Puede probar una versión posterior yendo a este sitio web y revisando la sección Historial de versiones. Después de descargarlo, descomprímalo en una ubicación conocida en su sistema de archivos. Una vez hecho esto, ahora está listo para usar el analizador de
nltk, que exploraremos pronto.
El analizador de Stanford generalmente utiliza un analizador PCFG (gramática probabilística sin contexto). Un PCFG es una gramática libre de contexto que asocia una probabilidad con cada una de sus reglas de producción. La probabilidad de un árbol de análisis generado a partir de un PCFG es simplemente la producción de las probabilidades individuales de las producciones utilizadas para generarlo.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
podemos ver la circunscripción árbol de análisis para nuestros titulares de noticias. Visualicemos para entender mejor la estructura.
from IPython.display import displaydisplay(result)
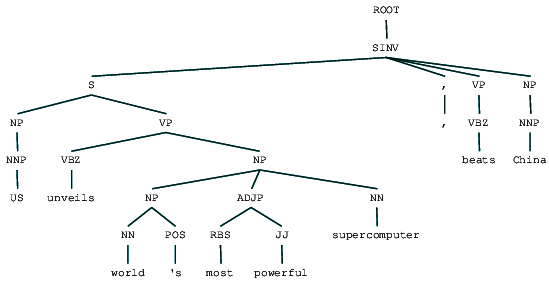
Circunscripción analiza titular de noticias
Podemos ver la misma estructura jerárquica de los componentes en el resultado anterior como en comparación con la estructura plana en la poca profundidad de análisis. En caso de que se pregunte qué significa SINV, representa una oración declarativa invertida, es decir, una en la que el sujeto sigue el verbo tensado o modal. Consulte la referencia de Penn Treebank según sea necesario para buscar otras etiquetas.
Análisis de dependencias
En el análisis de dependencias, tratamos de usar gramáticas basadas en dependencias para analizar e inferir dependencias semánticas y estructurales y relaciones entre tokens en una oración. El principio básico detrás de una gramática de dependencias es que en cualquier oración en el idioma, todas las palabras excepto una, tienen alguna relación o dependencia de otras palabras en la oración. La palabra que no tiene dependencia se llama la raíz de la oración. El verbo se toma como la raíz de la oración en la mayoría de los casos. Todas las demás palabras están directa o indirectamente vinculadas al verbo raíz mediante enlaces, que son las dependencias.
Considerando nuestra oración «El zorro marrón es rápido y está saltando sobre el perro perezoso», si quisiéramos dibujar el árbol de sintaxis de dependencias para esto, tendríamos la estructura
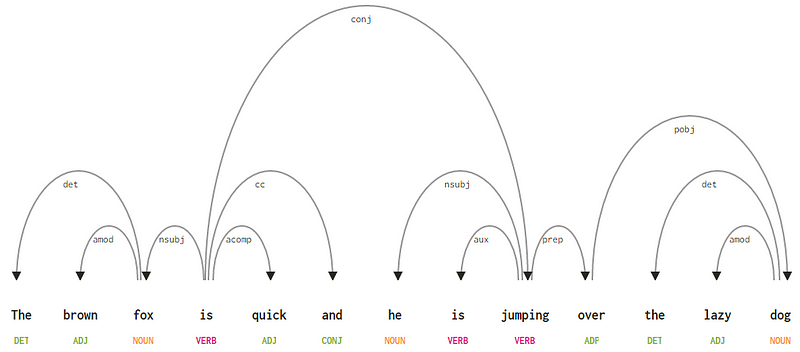
Un árbol de análisis de dependencias para una oración
Cada una de estas relaciones de dependencia tiene su propio significado y forma parte de una lista de tipos de dependencia universales. Esto se discute en un artículo original, Universal Stanford Dependencies: A Cross-Linguistic Typology por de Marneffe et al, 2014). Puede consultar la lista exhaustiva de tipos de dependencias y sus significados aquí.
Si observamos algunas de estas dependencias, no es demasiado difícil de entender.
- La etiqueta de dependencia det es bastante intuitiva: denota la relación determinante entre una cabeza nominal y el determinante. Por lo general, la palabra con etiqueta POS DET también tendrá la relación de etiqueta de dependencia det. Los ejemplos incluyen
fox → theydog → the. - La etiqueta de dependencia amod significa modificador adjetivo y significa cualquier adjetivo que modifique el significado de un sustantivo. Los ejemplos incluyen
fox → brownydog → lazy. - La etiqueta de dependencia nsubj significa una entidad que actúa como sujeto o agente en una cláusula. Los ejemplos incluyen
is → foxyjumping → he. - Las dependencias cc y conj tienen más que ver con enlaces relacionados con palabras conectadas por conjunciones coordinadas . Los ejemplos incluyen
is → andyis → jumping. - La etiqueta de dependencia aux indica el verbo auxiliar o secundario en la cláusula. Ejemplo:
jumping → is. - La etiqueta de dependencia acomp significa complemento adjetivo y actúa como complemento u objeto de un verbo en la oración. Ejemplo:
is → quick - La etiqueta de dependencia prep denota un modificador preposicional, que generalmente modifica el significado de un sustantivo, verbo, adjetivo o preposición. Por lo general, esta representación se usa para preposiciones que tienen un sustantivo o un complemento de frase nominal. Ejemplo:
jumping → over. - La etiqueta de dependencia pobj se usa para denotar el objeto de una preposición . Esta es generalmente la cabeza de una frase nominal después de una preposición en la oración. Ejemplo:
over → dog.
Spacy tenía dos tipos de analizadores de dependencias en inglés basados en los modelos de idioma que utilizas, puedes encontrar más detalles aquí. Basado en modelos de lenguaje, puede usar el Esquema de Dependencias Universales o el Esquema de Dependencias de Estilo CLARO que también está disponible en NLP4J ahora. Ahora aprovecharemos spacy e imprimiremos las dependencias para cada token en nuestro titular de noticias.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
es evidente que el verbo beats es la RAÍZ, ya que no tiene ningún otro dependencias como en comparación con el resto de elementos. Para saber más sobre cada anotación, siempre puede consultar el esquema de dependencias CLARAS. También podemos visualizar las dependencias anteriores de una mejor manera.
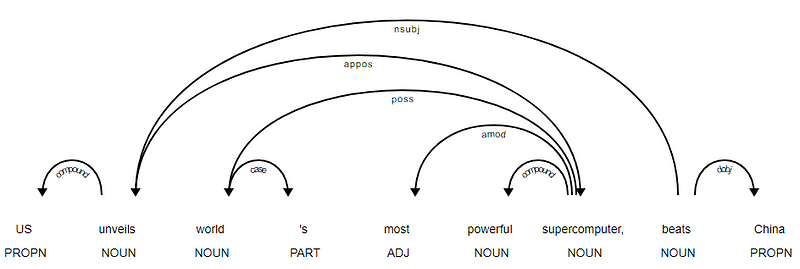
Noticias de la Titular de la dependencia árbol de SpaCy
también puede aprovechar nltk y el StanfordDependencyParser para visualizar y construir el árbol de dependencias. Mostramos el árbol de dependencias tanto en su forma cruda como anotada de la siguiente manera.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
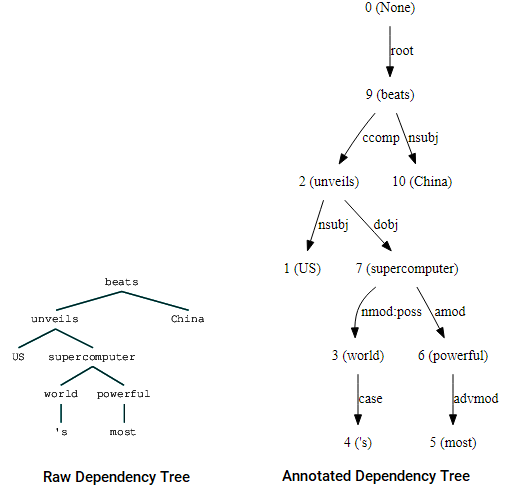
Árbol de dependencias de visualizaciones mediante nltk de Stanford dependencia analizador
Usted puede notar las similitudes con el árbol que había obtenido anteriormente. Las anotaciones ayudan a comprender el tipo de dependencia entre los diferentes tokens.
Bio: Dipanjan Sarkar es un científico de datos @Intel, un autor, un mentor @Springboard, un escritor y un adicto a los deportes y a las sitcom.
Original. Publicado con permiso.
Relacionados:
- Modelos Robustos de Word2Vec con Gensim & Aplicación de funciones de Word2Vec para Tareas de Aprendizaje Automático
- Aprendizaje Automático Interpretable por Humanos (Parte 1): La Necesidad y la Importancia de la Interpretación de Modelos
- Implementación de Métodos de Aprendizaje Profundo e Ingeniería de Funciones para Datos de Texto: El Modelo de Salto de gramo