KDnuggets
for alle språk, syntaks og struktur vanligvis går hånd i hånd, der et sett av spesifikke regler, konvensjoner og prinsipper styrer måten ord er kombinert i setninger; setninger få kombinerer i klausuler; og klausuler bli kombinert i setninger. Vi snakker spesielt om engelskspråklig syntaks og struktur i denne delen. På engelsk kombinerer ord vanligvis sammen for å danne andre bestanddeler. Disse bestanddelene inkluderer ord, setninger, klausuler og setninger. Med tanke på en setning, «den brune reven er rask og han hopper over den dovne hunden», den er laget av en haug med ord og bare ser på ordene av seg selv, forteller oss ikke mye.

en haug med uordnede ord formidler ikke mye informasjon
Kunnskap om språkets struktur og syntaks er nyttig på mange områder som tekstbehandling, annotering og parsing for videre operasjoner som tekstklassifisering eller oppsummering. Typiske parsing teknikker for å forstå tekst syntaks er nevnt nedenfor.
- Deler Av Tale (POS) Tagging
- Grunne Parsing eller Chunking
- Valgkrets Parsing
- Avhengighet Parsing
Vi vil se på alle disse teknikkene i påfølgende seksjoner. Med tanke på vår tidligere eksempelsetning «den brune reven er rask og han hopper over den dovne hunden», hvis vi skulle annotere den ved hjelp av grunnleggende POS-koder, ville det se ut som følgende figur.

POS tagging for en setning
således følger en setning vanligvis en hierarkisk struktur som består av følgende komponenter,
setning hryvnias klausuler → setninger → ord
tagging parts of speech
parts of speech (pos) er spesifikke leksikalske kategorier som ord er tildelt, basert på deres syntaktiske kontekst og rolle. Vanligvis kan ord falle inn i en av følgende hovedkategorier.
- N(oun): Dette betyr vanligvis ord som skildrer noe objekt eller enhet, som kan være levende eller nonliving. Noen eksempler ville være rev, hund , bok og så videre. POS-symbolet for substantiv er N.
- V(erb): Verb er ord som brukes til å beskrive bestemte handlinger, tilstander eller hendelser. Det finnes et bredt utvalg av ytterligere underkategorier, for eksempel hjelpeverb, refleksive og transitive verb (og mange flere). Noen typiske eksempler på verb ville løpe, hoppe, lese og skrive . POS-symbolet for verb er V.
- Adj(ective): Adjektiver er ord som brukes til å beskrive eller kvalifisere andre ord, vanligvis substantiv og substantiv setninger. Uttrykket vakker blomst har substantivet (N) blomst som er beskrevet eller kvalifisert ved hjelp av adjektivet (ADJ) vakker . POS-symbolet for adjektiver er ADJ .Adv(Erb): Adverb fungerer vanligvis som modifikatorer for andre ord, inkludert substantiver, adjektiver, verb eller andre adverb. Uttrykket veldig vakker blomst har adverbet (ADV) veldig, som endrer adjektivet (ADJ) vakkert, noe som indikerer i hvilken grad blomsten er vakker. POS-symbolet for adverb er ADV.
Foruten disse fire hovedkategorier av deler av tale, er det andre kategorier som forekommer ofte i det engelske språket. Disse inkluderer pronomen, preposisjoner, interjections, konjunksjoner, determiners og mange andre. VIDERE KAN HVER POS-tag som substantivet (N) videre deles inn i kategorier som singulære substantiv(NN), singulære egennavn (NNP) og flertallsnavn (NNS).
prosessen med klassifisering OG merking POS-koder for ord som kalles deler av tale tagging ELLER POS tagging . POS-koder brukes til å annotere ord og skildre DERES POS, noe som er veldig nyttig for å utføre spesifikk analyse, for eksempel å begrense ned på substantiver og se hvilke som er mest fremtredende, ordfølelse disambiguation og grammatikkanalyse. Vi vil utnytte både nltk og spacy som vanligvis bruker Penn Treebank-notasjonen for POS-tagging.
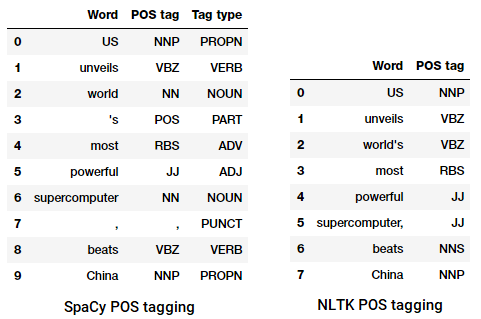
POS tagging en nyhetsoverskrift
Vi kan se at hver av disse bibliotekene behandler tokens på egen måte og tilordner bestemte koder for dem. Basert på det vi ser, synes spacy å gjøre litt bedre enn nltk.
Grunne Parsing eller Chunking
basert på hierarkiet vi avbildet tidligere, grupper av ord utgjør setninger. Det er fem hovedkategorier av setninger:
- Substantivfrase (NP): Dette er setninger der et substantiv fungerer som hovedordet. Substantiv setninger fungere som et emne eller objekt til et verb.
- Verbfrase( VP): disse setningene er leksikalske enheter som har et verb som fungerer som hovedordet. Vanligvis er det to former for verb setninger. En form har verb komponenter samt andre enheter som substantiver, adjektiver eller adverb som deler av objektet.
- Adjektivfrase (ADJP): dette er setninger med et adjektiv som hovedordet. Deres hovedrolle er å beskrive eller kvalifisere substantiver og pronomen i en setning, og de vil enten plasseres før eller etter substantivet eller pronomen.
- Adverb setning (ADVP): disse setningene fungere som adverb siden adverb fungerer som hodet ord i uttrykket. Adverb setninger brukes som modifikatorer for substantiver, verb eller adverb selv ved å gi ytterligere detaljer som beskriver eller kvalifiserer dem.Prepositional phrases (PP): disse setningene inneholder vanligvis en preposisjon som hovedordet og andre leksikalske komponenter som substantiver, pronomen og så videre. Disse fungerer som et adjektiv eller adverb som beskriver andre ord eller setninger.Grunne parsing, også kjent som lys parsing eller chunking, er en populær naturlig språkbehandlingsteknikk for å analysere strukturen i en setning for å bryte den ned i sine minste bestanddeler (som er tokens som ord) og gruppere dem sammen i høyere nivå setninger. DETTE inkluderer POS-koder samt setninger fra en setning.
et eksempel på grunne parsing viser høyere nivå setning merknaderVi vil utnytte
conll2000corpus for trening vår grunne parser modell. Dette corpus er tilgjengelig inltkmed blings merknader og vi skal bruke rundt 10K poster for trening vår modell. En prøve annotert setning er avbildet som følger.10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
fra forrige utgang, kan du se at våre datapunkter er setninger som allerede er merket med setninger og POS tags metadata som vil være nyttig i trening vår grunne parser modell. Vi vil utnytte to chunking utility-funksjoner, tree2contolltags, for å få tredobler av word, tag og chunk-koder for hvert token, og conlltags2tree for å generere et parsetre fra disse token-triplene. Vi skal bruke disse funksjonene til å trene vår parser. En prøve er avbildet nedenfor.
bitkodene bruker iob-formatet. Denne notasjonen representerer Innsiden, Utsiden og Begynnelsen. B-prefikset før en kode indikerer at det er begynnelsen på en del, og I – prefikset indikerer at det er inne i en del. O-taggen indikerer at token ikke tilhører noen del. B-taggen brukes alltid når det er etterfølgende koder av samme type som følger den uten tilstedeværelse Av O-koder mellom dem.
vi vil nå definere en funksjon
conll_tag_ chunks()for å trekke UT POS og blings koder fra setninger med chunked merknader og en funksjon kaltcombined_taggers()å trene flere taggers med backoff taggers (f.eks unigram og bigram taggers)vi vil nå definere en klasse
NGramTagChunkersom vil ta inn merkede setninger som treningsinngang, få deres (ord, pos-tag, blings-tag) wtc tredobler, og trene enBigramTaggermed enUnigramTaggersom backoff-taggeren. Vi vil også definere enparse()funksjon for å utføre grunne parsing på nye setningerUnigramTaggerBigramTaggerogTrigramTaggerer klasser som arver fra grunnklassenNGramTagger, som selv arver fraContextTagger– klassen, som arver fraSequentialBackoffTagger– klassen.Vi vil bruke denne klassen til å trene på
conll2000chunkedtrain_dataog evaluere modellytelsen påtest_dataChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
vår chunking modell får en nøyaktighet på rundt 90% som er ganske bra! La oss nå utnytte denne modellen til grunne analysere og blings vår prøve nyhetsartikkel overskrift som vi brukte tidligere, «US unveils world’ s most powerful supercomputer, beats China».
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
dermed kan du se at det har identifisert to substantivfraser (np) og en verbfrase (vp) i nyhetsartikkelen. HVERT ords POS-koder er også synlige. Vi kan også visualisere dette i form av et tre som følger. Du må kanskje installere ghostscript i tilfelle
nltkkaster en feil.

Grunne analyserte nyhetsoverskriftforrige utgang gir en god følelse av struktur etter grunne analysering av nyhetsoverskriften.
Valgkrets Parsing
Bestanddelbaserte grammatikker brukes til å analysere og bestemme bestanddelene i en setning. Disse grammatikkene kan brukes til å modellere eller representere den interne strukturen av setninger i form av en hierarkisk ordnet struktur av deres bestanddeler. Hvert ord tilhører vanligvis en bestemt leksikalsk kategori i saken og danner hovedordet i forskjellige setninger. Disse setningene er dannet basert på regler som kalles setningsstruktur regler.
Setningsstruktur regler danner kjernen i valgkrets grammatikker, fordi de snakker om syntaks og regler som styrer hierarkiet og rekkefølgen av de ulike bestanddelene i setningene. Disse reglene imøtekomme to ting primært.
- de bestemmer hvilke ord som brukes til å konstruere setningene eller bestanddelene.
- de bestemmer hvordan vi må bestille disse bestanddelene sammen.
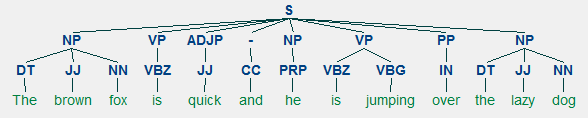
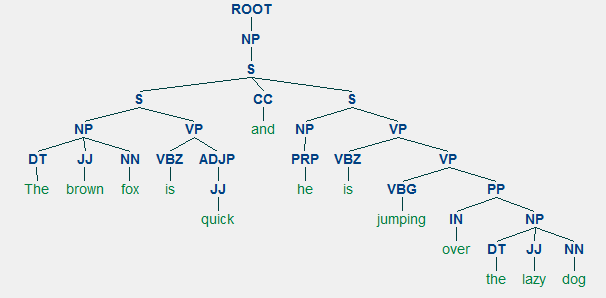
den generiske representasjon av en setning struktur regel ER S → AB, som viser at strukturen s består av bestanddeler A og B, og rekkefølgen er a etterfulgt Av B . Mens det er flere regler (se Kapittel 1, Side 19: Tekstanalyse med Python, hvis du vil dykke dypere), beskriver den viktigste regelen hvordan du deler en setning eller en klausul. Setningsstrukturregelen betegner en binær divisjon for en setning eller en klausul som S → NP VP hvor S er setningen eller klausulen, og den er delt inn i emnet, betegnet med substantivfrasen (NP) og predikatet, betegnet med verbfrasen (VP).en valgkrets-parser kan bygges basert på slike grammatikker / regler, som vanligvis er kollektivt tilgjengelige som kontekstfri grammatikk (CFG) eller setningsstrukturert grammatikk. Parseren vil behandle innspill setninger i henhold til disse reglene, og bidra til å bygge et parsetre.
et eksempel på valgkretsparsing som viser en nestet hierarkisk strukturVi skal bruke
nltkogStanfordParserher for å generere analysere trær.Forutsetninger: Last ned den offisielle Stanford Parser herfra, som synes å fungere ganske bra. Du kan prøve en senere versjon ved å gå til denne nettsiden og sjekke Release History-delen. Etter nedlasting, pakk den til et kjent sted i filsystemet. Når du er ferdig, er du nå klar til å bruke parseren fra
nltk, som vi snart skal utforske.Stanford-parseren bruker vanligvis EN PCFG-parser (probabilistisk kontekstfri grammatikk). EN PCFG er en kontekstfri grammatikk som knytter en sannsynlighet med hver av sine produksjonsregler. Sannsynligheten for et parsetre generert fra EN PCFG er ganske enkelt produksjonen av de individuelle sannsynlighetene for produktioner som brukes til å generere den.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Vi kan se valgkrets analysere treet for vår nyhetsoverskrift. La oss visualisere det for å forstå strukturen bedre.
from IPython.display import displaydisplay(result)
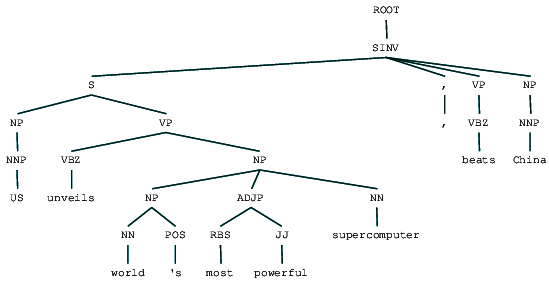
Valgkrets analysert nyhetsoverskriftvi kan se den nestede hierarkiske strukturen til bestanddelene i foregående utgang i forhold til den flate strukturen i grunne parsing. Hvis DU lurer på hva SINV betyr, representerer den En Omvendt deklarativ setning, dvs. en der motivet følger det spenne verbet eller modal. Se Penn Treebank referanse etter behov for å slå opp andre koder.
Avhengighetsparsing
i avhengighetsparsing prøver vi å bruke avhengighetsbaserte grammatikker for å analysere og utlede både struktur og semantiske avhengigheter og relasjoner mellom tokens i en setning. Det grunnleggende prinsippet bak en avhengighetsgrammatikk er at i en setning på språket har alle ord unntatt en, noe forhold eller avhengighet av andre ord i setningen. Ordet som ikke har noen avhengighet kalles roten til setningen. Verbetet er tatt som roten til setningen i de fleste tilfeller. Alle de andre ordene er direkte eller indirekte knyttet til rotverbet ved hjelp av lenker, som er avhengighetene.Med Tanke på vår setning «den brune reven er rask og han hopper over den dovne hunden», hvis vi ønsket å tegne avhengighetssyntakstreet for dette, ville vi ha strukturen
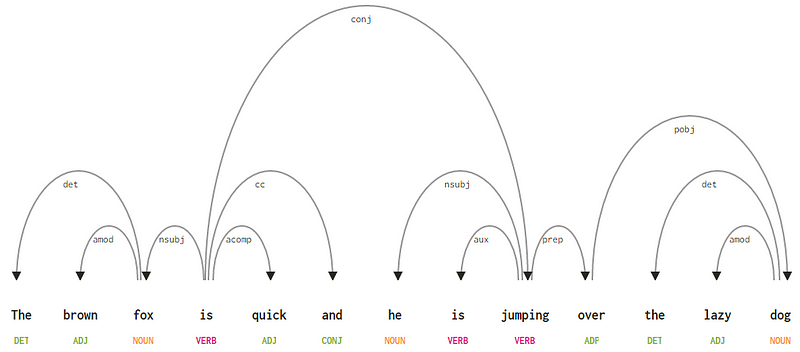
et avhengighetsparsetre for en setninghvis vi observerer noen av disse avhengighetene, er det ikke så vanskelig å forstå dem.
- avhengighetskoden det er ganske intuitiv — den betegner determiner forholdet mellom et nominelt hode og determiner. Vanligvis vil ordet MED POS tag DET også ha det dependency tag relationship. Eksempler er
fox → theogdog → the.amod står for adjektiv modifier og står for ethvert adjektiv som endrer betydningen av et substantiv. Eksempler erfox → brownogdog → lazy. - avhengighetskoden nsubj står for en enhet som fungerer som et emne eller agent i en klausul. Eksempler er
is → foxogjumping → he. - avhengighetene cc og conj har mer å gjøre med koblinger relatert til ord forbundet med koordinerende sammenhenger . Eksempler er
is → andogis → jumping. - avhengighetskoden aux angir hjelpeordet eller sekundærverbet i setningsdelen. Eksempel:
jumping → is. - avhengighetskoden acomp står for adjektiv komplement og fungerer som komplement eller objekt til et verb i setningen. Eksempel:
is → quick - avhengighetskoden prep betegner en prepositional modifier, som vanligvis endrer betydningen av et substantiv, verb, adjektiv eller preposisjon. Vanligvis brukes denne representasjonen til preposisjoner som har et substantiv eller substantivfrasskomplement. Eksempel:
jumping → over. - avhengighetskoden pobj brukes til å betegne objektet til en preposisjon . Dette er vanligvis hodet til en substantivfrase etter en preposisjon i setningen. Eksempel:
over → dog.
Spacy hadde to typer engelsk avhengighet parsere basert på hvilke språkmodeller du bruker, kan du finne flere detaljer her. Basert på språkmodeller kan Du bruke Universal Dependencies Scheme eller CLEAR Style Dependency Scheme som også er tilgjengelig i NLP4J nå. Vi vil nå utnytte
spacyog skrive ut avhengighetene for hvert token i nyhetsoverskriften.<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
det er tydelig at verbet slår ER ROTEN siden det ikke har noen andre avhengigheter i forhold til de andre tokens. For å vite mer om hver merknad kan du alltid referere TIL CLEAR dependency scheme. Vi kan også visualisere de ovennevnte avhengighetene på en bedre måte.
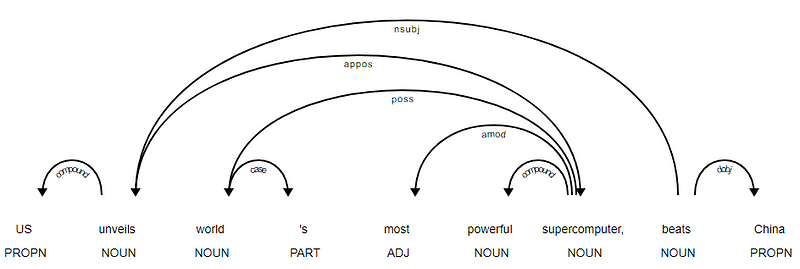 nyheter Overskrift avhengighet treet Fra SpaCy
nyheter Overskrift avhengighet treet Fra SpaCydu kan også utnytte
nltkogStanfordDependencyParserfor å visualisere og bygge ut avhengighetstreet. Vi presenterer avhengighetstreet både i sin rå og annoterte form som følger.(beats (unveils US (supercomputer (world 's) (powerful most))) China)
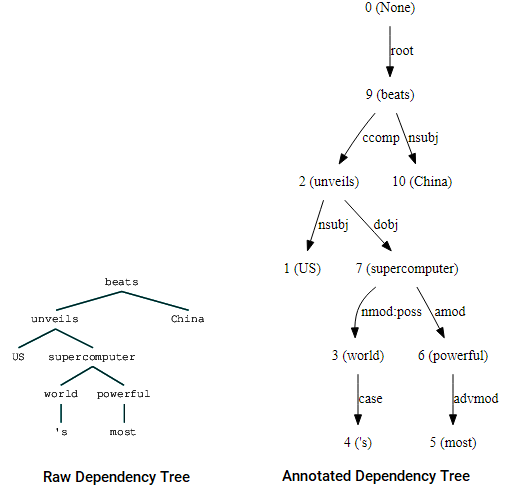
Dependency tre visualiseringer ved hjelp av Nltks Stanford dependency parserdu kan merke likhetene med treet vi hadde fått tidligere. Merknadene hjelper med å forstå typen avhengighet blant de forskjellige tokens.Bio: Dipanjan Sarkar Er En Data Scientist @Intel, en forfatter, en mentor @Springboard, en forfatter, og en sport og sitcom addict.
Original. Reposted med tillatelse.
Relatert:
- Robuste Word2Vec-Modeller med Gensim & Bruk Av Word2Vec-Funksjoner for Maskinlæringsoppgaver
- Menneskelig Tolkbar Maskinlæring (Del 1 — – Behovet og Betydningen Av Modelltolkning
- Implementering Av Dype Læringsmetoder og Funksjonsteknikk For Tekstdata: Skip-gram-Modellen