KDnuggets
dla każdego języka składnia i struktura zwykle idą w parze, gdzie zbiór określonych reguł, konwencji i zasad reguluje sposób łączenia słów w frazy; frazy łączą się w zdania, a zdania łączą się w zdania. W tej sekcji będziemy mówić konkretnie o składni i strukturze języka angielskiego. W języku angielskim Słowa zwykle łączą się ze sobą, tworząc inne jednostki składowe. Składniki te obejmują słowa, wyrażenia, zdania i zdania. Biorąc pod uwagę zdanie: „brązowy lis jest szybki i przeskakuje nad leniwym psem”, składa się Ono z kilku słów i samo patrzenie na słowa nie mówi nam wiele.

kilka nieuporządkowanych słów nie przekazuje wiele informacji
Wiedza o strukturze i składni języka jest pomocna w wielu obszarach, takich jak przetwarzanie tekstu, adnotacja i parsowanie dla dalszych operacji, takich jak klasyfikacja tekstu lub podsumowanie. Typowe techniki parsowania dla zrozumienia składni tekstu są wymienione poniżej.
- tagowanie części mowy (POS)
- parsowanie płytkie lub Chunking
- parsowanie okręgów wyborczych
- parsowanie zależności
w kolejnych sekcjach przyjrzymy się wszystkim tym technikom. Biorąc pod uwagę nasze poprzednie przykładowe zdanie „the brown fox is quick and he is jumping over the lazy dog”, gdybyśmy przypisali je za pomocą podstawowych tagów POS, wyglądałoby to jak na poniższym rysunku.

oznaczanie POS dla zdania
w związku z tym zdanie zazwyczaj ma strukturę hierarchiczną składającą się z następujących elementów,
zdanie → zdania → zwroty → słowa
oznaczanie części mowy
części mowy (POS) są specyficznymi kategoriami leksykalnymi, do których przypisywane są słowa, w oparciu o ich kontekst składniowy i rolę. Zazwyczaj słowa mogą należeć do jednej z następujących głównych kategorii.
- N (oun): Zwykle oznacza to słowa, które przedstawiają jakiś przedmiot lub byt, który może być żywy lub nieożywiony. Przykładem może być Lis, pies, Książka i tak dalej. Symbolem znacznika POS dla rzeczowników jest N.
- V(erb): czasowniki są słowami, które są używane do opisania pewnych działań, Stanów lub wystąpień. Istnieje wiele innych podkategorii, takich jak czasowniki pomocnicze, odruchowe i przechodnie (i wiele innych). Typowe przykłady czasowników to bieganie, skakanie , czytanie i pisanie . Symbolem znacznika POS dla czasowników jest V.
- Adj (ective): Przymiotniki to słowa używane do opisania lub zakwalifikowania innych słów, zazwyczaj rzeczowników i zwrotów rzeczownikowych. Fraza beautiful flower ma rzeczownik (N) flower, który jest opisany lub kwalifikowany za pomocą przymiotnika (ADJ) beautiful . Symbolem znacznika POS dla przymiotników jest ADJ .
- Adv(erb): przysłówki zwykle działają jako modyfikatory dla innych słów, w tym rzeczowników, przymiotników, czasowników lub innych przysłówków. Fraza very beautiful flower ma przysłówek (ADV) very, który modyfikuje przymiotnik (ADJ) beautiful, wskazując stopień, w jakim kwiat jest piękny. Symbolem tagu POS dla przysłówków jest ADV.
oprócz tych czterech głównych kategorii Części mowy , istnieją inne kategorie, które występują często w języku angielskim. Należą do nich zaimki, przyimki, interpunkcje, spójniki, określniki i wiele innych. Ponadto każdy znacznik POS, taki jak rzeczownik (N), może być dalej podzielony na kategorie, takie jak rzeczowniki w liczbie pojedynczej (NN), rzeczowniki w liczbie pojedynczej(NNP) i rzeczowniki w liczbie mnogiej (NNS).
proces klasyfikowania i etykietowania tagów POS dla słów zwanych tagowaniem części mowy lub tagowaniem POS . Znaczniki POS są używane do opisywania słów i przedstawiania ich POS, co jest naprawdę pomocne w przeprowadzaniu konkretnych analiz, takich jak zawężanie rzeczowników i sprawdzanie, które z nich są najbardziej widoczne, dezambiguacja sensu słów i analiza gramatyczna. Będziemy wykorzystywać zarówno nltk, jak i spacy, które zwykle używają notacji Penn Treebank do tagowania POS.
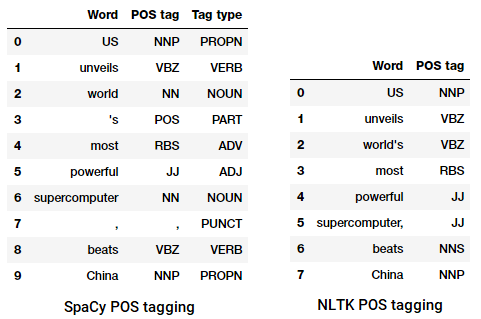
POS tagowanie nagłówka wiadomości
widzimy, że każda z tych bibliotek traktuje tokeny na swój sposób i przypisuje im określone tagi. Na podstawie tego, co widzimy, spacy wydaje się mieć nieco lepiej niż nltk.
płytkie parsowanie lub Chunking
Na podstawie hierarchii, którą przedstawiliśmy wcześniej, grupy słów tworzą zwroty. Istnieje pięć głównych kategorii fraz:
- fraza rzeczownikowa (NP): Są to Zwroty, w których rzeczownik działa jako słowo główne. Wyrażenia rzeczownikowe działają jako podmiot lub przedmiot czasownika.
- verb phrase (VP): te Zwroty są jednostkami leksykalnymi, które mają czasownik działający jako słowo główne. Zazwyczaj istnieją dwie formy zwrotów czasownikowych. Jedna forma zawiera składniki czasownika, a także inne jednostki, takie jak rzeczowniki, przymiotniki lub przysłówki jako części obiektu.
- fraza Przymiotnikowa (ADJP): są to wyrażenia z przymiotnikiem jako słowem głównym. Ich główną rolą jest opisywanie lub kwalifikowanie rzeczowników i zaimków w zdaniu i będą one umieszczane przed lub po rzeczowniku lub zaimku.
- przysłówek phrase (ADVP): te wyrażenia działają jak przysłówki, ponieważ przysłówek działa jako słowo główne w frazie. Wyrażenia przysłówkowe są używane jako modyfikatory dla rzeczowników, czasowników lub samych przysłówków poprzez podanie dalszych szczegółów, które je opisują lub kwalifikują.
- fraza Przyimkowa (PP): te zwroty zwykle zawierają przyimek jako słowo główne i inne składniki leksykalne, takie jak rzeczowniki, zaimki i tak dalej. Działają one jak przymiotnik lub przysłówek opisujący inne słowa lub frazy.
płytkie parsowanie, znane również jako lekkie parsowanie lub chunking, jest popularną techniką przetwarzania języka naturalnego analizującą strukturę zdania w celu rozbicia go na najmniejsze składniki (które są tokenami, takimi jak słowa) i grupowania ich razem w wyrażenia wyższego poziomu. Obejmuje to znaczniki POS, a także zwroty ze zdania.
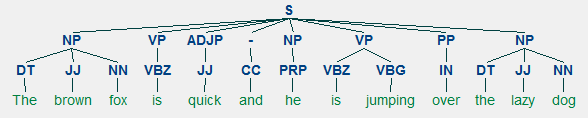
przykład płytkiego parsowania przedstawiający adnotacje frazy wyższego poziomu
wykorzystamyconll2000 do szkolenia naszego modelu płytkiego parsera. Ten korpus jest dostępny w nltk z fragmentami adnotacji i będziemy używać około 10K rekordów do szkolenia naszego modelu. Przykładowe zdanie opatrzone adnotacjami przedstawia się następująco.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
z poprzedniego wyjścia widać, że nasze punkty danych są zdaniami, które są już adnotowane za pomocą fraz i metadanych tagów POS, które będą przydatne w szkoleniu naszego płytkiego modelu parsera. Wykorzystamy dwie funkcje narzędzia do łączenia, tree2conlltags, aby uzyskać potrójne znaczniki word, tag i chunk dla każdego tokena, oraz conlltags2tree, aby wygenerować drzewo parse z tych potrójnych tokenów. Będziemy używać tych funkcji do trenowania naszego parsera. Próbka jest przedstawiona poniżej.
znaczniki chunk używają formatu IOB. Zapis ten reprezentuje Wnętrze, Na zewnątrz i początek. Przedrostek B przed znacznikiem wskazuje, że jest to początek fragmentu, a przedrostek I oznacza, że znajduje się on wewnątrz fragmentu. Znacznik O wskazuje, że token nie należy do żadnego fragmentu. Znacznik B jest zawsze używany, gdy po nim znajdują się kolejne znaczniki tego samego typu, bez obecności znaczników O między nimi.
zdefiniujemy teraz funkcję conll_tag_ chunks(), aby wyodrębnić znaczniki POS i chunk ze zdań z przytłumionymi adnotacjami oraz funkcję o nazwie combined_taggers(), aby wytrenować wiele znaczników z tagerami backoff (np. znaczniki unigram i bigram)
zdefiniujemy teraz klasę NGramTagChunker, które będą przyjmować oznaczone zdania jako dane wejściowe do treningu, pobierać ich (słowo, tag POS, tag częściowy) WTC potrajać i trenować BigramTagger za pomocą UnigramTagger jako tagera backoff. Zdefiniujemy również funkcjęparse() do wykonywania płytkiego parsowania nowych zdań
UnigramTaggerBigramTaggerITrigramTaggersą klasami dziedziczącymi z klasy bazowejNGramTagger, która sama dziedziczy z klasyContextTagger, która dziedziczy z klasySequentialBackoffTagger.
będziemy używać tej klasy do szkolenia na conll2000train_data I oceny wydajności modelu na test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
Nasz model chunkingu uzyskuje dokładność około 90%, co jest całkiem dobre! Wykorzystajmy teraz ten model do płytkiej analizy i Podzielmy nasz przykładowy nagłówek artykułu, którego użyliśmy wcześniej: „US unveils World’ s most powerful supercomputer, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
tak więc widać, że w artykule prasowym zidentyfikowano dwie frazy rzeczownikowe (NP) i jedną frazę czasownikową (VP). Znaczniki POS każdego słowa są również widoczne. Możemy to również zwizualizować w formie drzewa w następujący sposób. Może być konieczne zainstalowanie ghostscript w przypadku, gdy nltk wyświetli błąd.

płytkie parsowane nagłówek wiadomości
poprzednie wyjście daje dobre poczucie struktury po płytkim parsowaniu nagłówka wiadomości.
parsowanie składowe
gramatyki oparte na składowych są używane do analizy i określenia składników zdania. Gramatyki te mogą być używane do modelowania lub reprezentowania wewnętrznej struktury zdań w kategoriach hierarchicznie uporządkowanej struktury ich składników. Każde słowo należy Zwykle do określonej kategorii leksykalnej w przypadku i tworzy słowo główne różnych zwrotów. Wyrażenia te są tworzone na podstawie reguł zwanych regułami struktury fraz.
reguły struktury fraz stanowią rdzeń gramatyki, ponieważ mówią o składni i regułach, które rządzą hierarchią i uporządkowaniem poszczególnych składników w zdaniach. Zasady te dotyczą przede wszystkim dwóch rzeczy.
- określają, jakie słowa są używane do konstruowania zwrotów lub składników.
- określają, w jaki sposób musimy uporządkować te składniki razem.
ogólną reprezentacją reguły struktury frazy jest S → AB , która przedstawia , że struktura S składa się ze składników a i B, a kolejność jest następująca po B . Chociaż istnieje kilka reguł (patrz rozdział 1, Strona 19: analiza tekstu w Pythonie, jeśli chcesz zagłębić się głębiej), najważniejsza reguła opisuje, jak podzielić zdanie lub klauzulę. Reguła struktury fraz oznacza binarny podział dla zdania lub zdania jako S → NP VP, gdzie S jest zdaniem lub klauzulą, i dzieli się na podmiot, oznaczony frazą rzeczownikową (NP) i orzeczenie, oznaczony frazą czasownikową (VP).
parser Okręgowy może być zbudowany w oparciu o takie gramatyki/reguły, które są zwykle zbiorczo dostępne jako gramatyka bez kontekstu (CFG) lub gramatyka strukturalna wyrażeń. Parser przetwarza zdania wejściowe zgodnie z tymi regułami i pomaga w budowaniu drzewa parsowania.
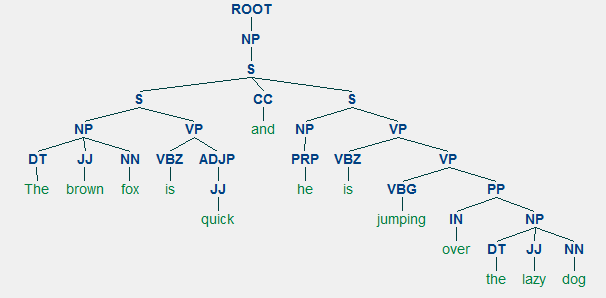
przykład parsowania okręgu pokazujący zagnieżdżoną strukturę hierarchiczną
będziemy używać nltk I StanfordParser tutaj, aby wygenerować drzewa parsowania.
Możesz wypróbować nowszą wersję, przechodząc na tę stronę internetową i sprawdzając sekcję Historia wydań. Po pobraniu rozpakuj go do znanej lokalizacji w systemie plików. Gdy to zrobisz, jesteś teraz gotowy do użycia parsera z
nltk, który wkrótce będziemy eksplorować.
Parser Stanforda zazwyczaj używa parsera PCFG (probabilistic context-free grammar). PCFG to gramatyka bez kontekstu, która kojarzy Prawdopodobieństwo z każdą z reguł produkcji. Prawdopodobieństwo drzewa parse generowane z PCFG jest po prostu produkcja poszczególnych prawdopodobieństw produkcje użyte do jego wygenerowania.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Wyobraźmy to sobie, aby lepiej zrozumieć strukturę.
from IPython.display import displaydisplay(result)
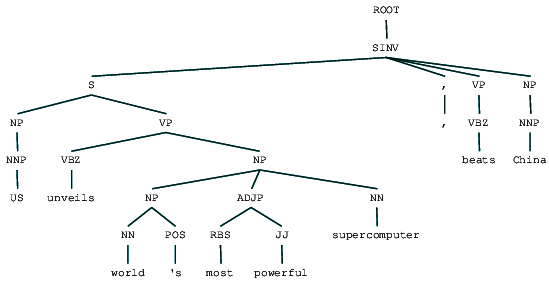
możemy zobaczyć zagnieżdżoną hierarchiczną strukturę składników w poprzednim wyjściu w porównaniu do płaskiej struktury w płytkim parsowaniu. Jeśli zastanawiasz się, co znaczy SINV, reprezentuje odwrócone zdanie deklaratywne, tj. takie, w którym podmiot następuje po czasowniku lub modalnym. Odwołaj się do odnośnika Penn Treebank w razie potrzeby, aby wyszukać inne tagi.
parsowanie zależności
w parsowaniu zależności staramy się używać gramatyk opartych na zależnościach do analizowania i wnioskowania zarówno zależności strukturalnych, jak i semantycznych oraz relacji między tokenami w zdaniu. Podstawową zasadą gramatyki zależności jest to, że w każdym zdaniu w języku wszystkie słowa z wyjątkiem jednego mają jakąś zależność lub zależność od innych słów w zdaniu. Słowo, które nie ma zależności, nazywa się rdzeniem zdania. Czasownik jest w większości przypadków traktowany jako rdzeń zdania. Wszystkie pozostałe słowa są bezpośrednio lub pośrednio powiązane z czasownikiem głównym za pomocą linków, które są zależnościami.
biorąc pod uwagę nasze zdanie „brązowy lis jest szybki i przeskakuje nad leniwym psem”, gdybyśmy chcieli narysować w tym celu drzewo składni zależności, mielibyśmy strukturę
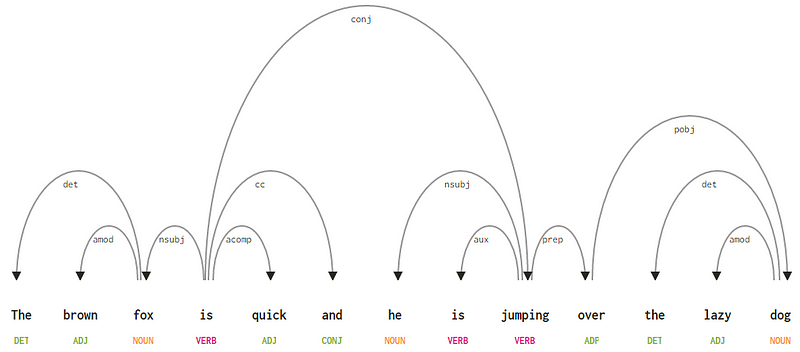
drzewo parsowania zależności Dla zdania
te zależności zależności każdy ma swoje znaczenie i są częścią listy uniwersalnych typów zależności. Jest to omówione w oryginalnym artykule, Universal Stanford Dependencies: a Cross-Linguistic Typology by de Marneffe et al, 2014). Możesz sprawdzić wyczerpującą listę typów zależności i ich znaczenia tutaj.
Jeśli zaobserwujemy niektóre z tych zależności, nietrudno je zrozumieć.
- znacznik zależności det jest dość intuicyjny — oznacza relację wyznacznika między nominalną głową a wyznacznikiem. Zazwyczaj słowo ze znacznikiem POS det będzie również miało relację det dependency tag. Przykłady obejmują
fox → theIdog → the. - znacznik zależności amod oznacza modyfikator przymiotnikowy i oznacza dowolny przymiotnik, który modyfikuje znaczenie rzeczownika. Przykłady obejmują
fox → brownIdog → lazy. - znacznik zależności nsubj oznacza encję, która działa jako podmiot lub agent w klauzuli. Przykłady obejmują
is → foxIjumping → he. - zależności cc i conj mają więcej wspólnego z powiązaniami związanymi ze słowami połączonymi przez koordynowanie spójników . Przykłady obejmują
is → andIis → jumping. - znacznik zależności aux wskazuje czasownik pomocniczy lub wtórny w zdaniu. Przykład:
jumping → is. - tag zależności acomp oznacza dopełnienie przymiotnika i działa jako dopełnienie lub dopełnienie czasownika w zdaniu. Przykład:
is → quick - znacznik zależności prep oznacza modyfikator przyimka, który zwykle modyfikuje znaczenie rzeczownika, czasownika, przymiotnika lub przyimka. Zwykle reprezentacja ta jest używana w przypadku przyimków mających dopełnienie rzeczownika lub frazy rzeczownikowej. Przykład:
jumping → over. - znacznik zależności pobj służy do oznaczania obiektu przyimka . Jest to zwykle Głowa frazy rzeczownikowej po przyimku w zdaniu. Przykład:
over → dog.
Spacy miał dwa typy parserów zależności w języku angielskim w oparciu o modele języka, których używasz, możesz znaleźć więcej szczegółów tutaj. Opierając się na modelach językowych, możesz użyć schematu zależności uniwersalnych lub schematu zależności jasnego stylu dostępnego również w NLP4J. Teraz wykorzystamy spacy I wydrukujemy zależności dla każdego tokena w nagłówku wiadomości.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
oczywiste jest, że czasownik beats jest rdzeniem, ponieważ nie ma żadnych innych zależności w porównaniu z innymi tokenami. Aby dowiedzieć się więcej o każdej adnotacji, zawsze możesz odwołać się do przejrzystego schematu zależności. Możemy również lepiej zwizualizować powyższe zależności.
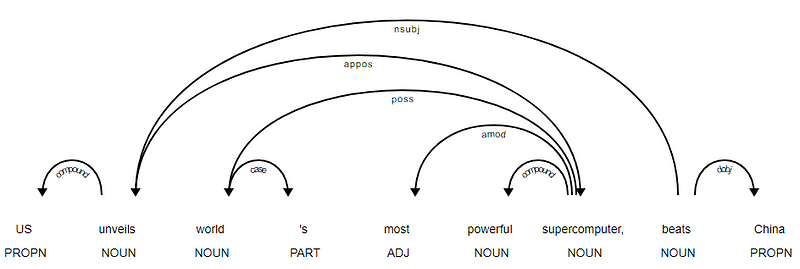
drzewo zależności nagłówka wiadomości od SpaCy
Możesz również wykorzystać nltk I StanfordDependencyParser do wizualizacji i budowania drzewa zależności. Przedstawiamy drzewo zależności zarówno w postaci surowej, jak i z adnotacjami w następujący sposób.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
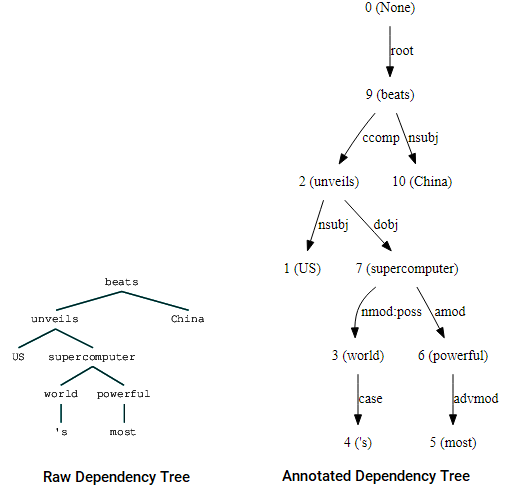
wizualizacje drzewa zależności z wykorzystaniem zależności nltk parser
można zauważyć podobieństwa do drzewa, które uzyskaliśmy wcześniej. Adnotacje pomagają w zrozumieniu rodzaju zależności między różnymi tokenami.
Bio: Dipanjan Sarkar jest analitykiem danych @Intel, autorem, mentorem @Springboard, pisarzem i uzależnionym od sportu i sitcomu.
oryginał. Reposted with permission.
podobne:
- solidne modele Word2vec z Gensim& zastosowanie funkcji Word2Vec do zadań uczenia maszynowego
- Ludzkie Uczenie maszynowe (Część 1) — potrzeba i znaczenie interpretacji modelu
- wdrażanie metod głębokiego uczenia i Inżynierii funkcji dla danych tekstowych: Model Skip-gram