KDnuggets
para qualquer linguagem, sintaxe e estrutura geralmente andam de mãos dadas, onde um conjunto de regras, convenções e princípios específicos governam a forma como as palavras são combinadas em frases; as frases combinam-se em cláusulas; e as cláusulas são combinadas em sentenças. Vamos falar especificamente sobre a sintaxe e estrutura da língua inglesa nesta seção. Em inglês, as palavras geralmente se combinam para formar outras unidades constituintes. Estes constituintes incluem palavras, frases, cláusulas e frases. Considerando uma frase,” A raposa castanha é rápida e está pulando sobre o cão preguiçoso”, é feita de um monte de palavras e apenas olhando para as palavras por si só não nos dizem muito.

Um grupo de não-ordenadas as palavras não conseguem transmitir toda a informação
o Conhecimento sobre a estrutura e a sintaxe da linguagem é útil em muitas áreas como processamento de texto, anotação e análise para mais operações, tais como a classificação de texto ou resumo. Técnicas típicas de análise para entender a sintaxe do texto são mencionadas abaixo.partes da marcação da fala (POS) análise superficial ou análise do círculo eleitoral análise da dependência Análise de todas estas técnicas em secções subsequentes. Considerando nossa frase de exemplo anterior “a raposa castanha é rápida e ele está pulando sobre o cão preguiçoso”, se nós fôssemos anotá-lo usando etiquetas POS básicas, ele iria se parecer com a seguinte figura.

POS tagging para uma sentença
Assim, uma frase geralmente segue uma estrutura hierárquica que consiste dos seguintes componentes,
frase → cláusulas → frases → palavras
Marcação de Partes do Discurso
Peças de speech (POS) são específicas as categorias lexicais para a qual as palavras são atribuídos, com base em seu contexto sintático e papel. Normalmente, as palavras podem cair em uma das seguintes categorias principais.
- n(oun): Isto geralmente denota palavras que retratam algum objeto ou entidade, que podem estar vivos ou não vivos. Alguns exemplos seriam fox, dog, book, e assim por diante. O símbolo de tag POS para substantivos é N.
- V(erb): verbos são palavras que são usadas para descrever certas ações, estados ou ocorrências. Há uma grande variedade de subcategorias adicionais, tais como verbos auxiliares, reflexivos e transitivos (e muitos mais). Alguns exemplos típicos de verbos seriam correr, saltar, ler e escrever . O símbolo de tag POS para verbos é V.
- Adj (ective): Adjetivos são palavras usadas para descrever ou qualificar outras palavras, tipicamente substantivos e frases substantivas. A expressão flor bonita tem o substantivo (N) flor que é descrito ou qualificado usando o adjetivo (ADJ) bonito . O símbolo POS tag para adjetivos é ADJ .
- Adv (erb): advérbios geralmente atuam como modificadores para outras palavras, incluindo substantivos, adjetivos, verbos ou outros advérbios. A frase flor muito bonita tem o advérbio muito, que modifica o adjetivo (ADJ) belo , indicando o grau em que a flor é bela. O símbolo POS tag para advérbios é ADV.
além destas quatro principais categorias de partes da fala, existem outras categorias que ocorrem frequentemente na língua inglesa. Estes incluem pronomes, preposições, interjeções, conjunções, determiners, e muitos outros. Além disso, cada tag POS como o substantivo (N) pode ser subdividido em categorias como substantivos singulares (NN), substantivos próprios singulares(NNP), e substantivos plurais (NNS).
o processo de classificação e rotulagem de etiquetas POS para palavras chamadas partes de marcação de fala ou marcação POS . Tags POS são usados para anotar palavras e retratar sua POS, o que é realmente útil para realizar análises específicas, tais como estreitar sobre substantivos e ver quais são os mais proeminentes, desambiguação de sentido de palavra, e análise gramatical. Estaremos alavancando ambos nltke spacy que usualmente usam a notação Penn Treebank para marcação POS.
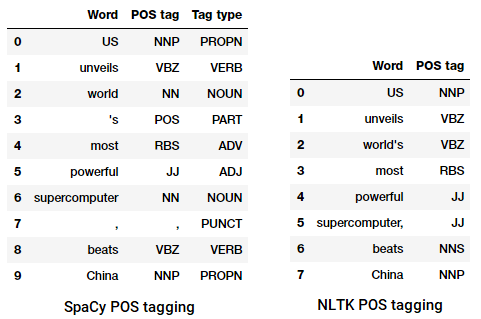
POS tagging uma manchete de notícia
podemos ver que cada uma dessas bibliotecas tratar tokens em seu próprio caminho e atribuir tags específicas para eles. Baseado no que vemos, spacyparece estar fazendo um pouco melhor quenltk.
análise superficial ou Chunking
com base na hierarquia que descrevemos anteriormente, grupos de palavras compõem frases. Existem cinco categorias principais de frases:
- frase substantiva (NP): Estas são frases onde um substantivo age como a palavra cabeça. As frases substantivas agem como um sujeito ou objeto a um verbo.
- frase verbal( VP): estas frases são unidades lexicais que têm um verbo agindo como a palavra principal. Normalmente, existem duas formas de frases verbais. Uma forma tem os componentes verbais, bem como outras entidades como substantivos, adjetivos ou advérbios como partes do objeto.
- frase adjetiva (ADJP): estas são frases com um adjetivo como a palavra cabeça. Seu papel principal é descrever ou qualificar substantivos e pronomes em uma sentença, e eles serão colocados antes ou depois do substantivo ou pronomes.
- advérbio frase (ADVP): estas frases agem como advérbios, uma vez que o advérbio age como a palavra principal na frase. Frases advérbicas são usadas como modificadores para substantivos, verbos ou advérbios, fornecendo detalhes adicionais que os descrevem ou qualificam.
- frase preposicional (PP): estas frases geralmente contêm uma preposição como a palavra-cabeça e outros componentes lexicais como substantivos, pronomes, e assim por diante. Estes agem como um adjetivo ou advérbio descrevendo outras palavras ou frases.
análise superficial, também conhecida como análise de luz ou chunking, é uma popular técnica de processamento de linguagem natural de analisar a estrutura de uma frase para quebrá-la em seus menores constituintes (que são símbolos como palavras) e agrupá-los em frases de nível superior. Isto inclui tags POS, bem como frases de uma frase.
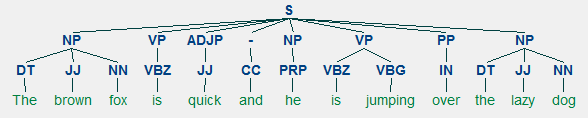
Um exemplo de análise superficial representando o maior nível de expressão anotações
Vamos aproveitar o conll2000 corpus para a formação de nossa shallow parser de modelo. Este corpus está disponível em nltk com anotações de chunk e estaremos usando cerca de 10k registros para treinar o nosso modelo. Apresenta-se a seguir uma frase anotada com uma amostra.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
a Partir do resultado anterior, você pode ver que os nossos pontos de dados são frases que já estão anotados com frases e POS tags de metadados que serão úteis na formação de nossa shallow parser de modelo. Nós vamos alavancar duas funções utilitárias chunking, tree2conltags, para obter triplos de palavras, tag, e tags chunk para cada token, e conlltags2tree para gerar uma árvore de parse a partir desses token triples. Vamos usar estas funções para treinar o nosso analisador. Apresenta-se a seguir uma amostra.
the chunk tags use the IOB format. Esta notação representa o interior, o exterior e o início. O prefixo B antes de uma tag indica que é o início de um bloco, e o prefixo I indica que ele está dentro de um bloco. A etiqueta O indica que o token não pertence a nenhum bloco. O B-tag é sempre usado quando há tags subsequentes do mesmo tipo seguindo-o sem a presença de tags O entre eles.
Vamos agora definir uma função conll_tag_ chunks() extrato de POS e de bloco de tags a partir de frases com blocos de anotações e uma função chamada combined_taggers() para treinar vários codificadores com a retirada taggers (e.g. unigram e bigram taggers)
Vamos agora definir uma classe NGramTagChunker que vai tomar no tagged frases como formação entrada, obter seus (word, POS tag, tag de Bloco) WTC triplos, e formar um BigramTagger com um UnigramTagger como o de backoff tagger. Também vamos definir uma parse() função para executar superficial análise em novas frases
UnigramTaggerBigramTaggereTrigramTaggersão classes que herdam da classe baseNGramTagger, que se herdaContextTaggerclasse que herda deSequentialBackoffTaggerclasse.
Vamos usar essa classe para treinar o conll2000 fragmentada train_data e avaliar o desempenho do modelo em que o test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
o Nosso agrupamento modelo obtém uma precisão de cerca de 90%, o que é muito bom! Vamos agora aproveitar este modelo para análise superficial e manchar a manchete do nosso artigo de notícias que usamos anteriormente, “us revela o supercomputador mais poderoso do mundo, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
Assim você pode vê-lo identificou dois substantivo (NP) e um verbo frase (VP) no artigo de notícias. As etiquetas POS de cada palavra também são visíveis. Nós também podemos visualizar isso na forma de uma árvore como segue. Poderá ter de instalar o ghostscript no caso de nltk lançar um erro.

Superficial analisado manchete de notícia
A saída anterior dá uma boa noção de estrutura, após análise superficial a manchete de notícia.
análise Eleitoral
gramáticas com base Constituinte são usadas para analisar e determinar os constituintes de uma sentença. Estas gramáticas podem ser usadas para modelar ou representar a estrutura interna de sentenças em termos de uma estrutura hierarquicamente ordenada de seus constituintes. Cada palavra geralmente pertence a uma categoria lexical específica no caso e forma a palavra-cabeça de diferentes frases. Estas frases são formadas com base em regras chamadas regras de estrutura de frases.
As Regras de estrutura de frases formam o núcleo das gramáticas de eleitorado, porque elas falam sobre sintaxe e regras que governam a hierarquia e ordenação dos vários constituintes nas sentenças. Estas regras servem principalmente para duas coisas.
- eles determinam que palavras são usadas para construir as frases ou constituintes.eles determinam como devemos encomendar estes constituintes juntos.
a representação genérica de uma regra de estrutura de frases é S → AB , que retrata que a estrutura S consiste de constituintes A E B , e a ordenação é a Seguida de B. Embora existam várias regras (veja o Capítulo 1, Página 19: Analytics de texto com Python, Se você quiser mergulhar mais profundamente), a regra mais importante descreve como dividir uma sentença ou uma cláusula. A regra da estrutura de frases denota uma divisão binária para uma sentença ou uma cláusula como S → NP VP onde S é a sentença ou cláusula, e é dividido no assunto, denotado pela frase substantiva (NP) e o predicado, denotado pela frase verbal (VP).
um analisador de eleitorado pode ser construído com base em tais gramáticas / regras, que são geralmente disponíveis coletivamente como gramática livre de contexto (CFG) ou gramática estruturada por frases. O analisador processará as sentenças de entrada de acordo com estas regras, e ajudará na construção de uma árvore de processamento.
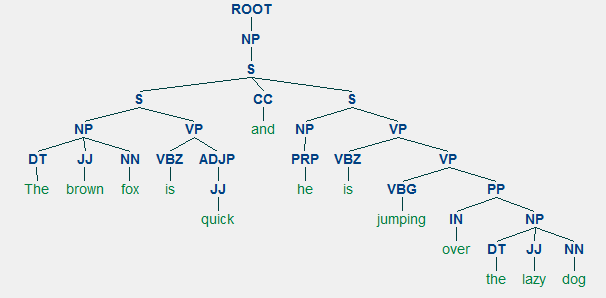
Um exemplo de eleitorado de análise mostrando um aninhados estrutura hierárquica
Vamos usar nltk e o StanfordParser aqui para gerar analisar árvores.
pré-requisitos: baixar o analisador Stanford oficial a partir daqui, que parece funcionar muito bem. Você pode experimentar uma versão posterior, indo para este site e verificando a seção de histórico de lançamento. Depois de baixar, desconecte-o para um local conhecido no seu sistema de ficheiros. Uma vez feito, você está agora pronto para usar o analisador de
nltk, que vamos explorar em breve.
The Stanford parser generally uses a PCFG (probabilistic context-free grammar) parser. PCFG é uma gramática livre de contexto que associa uma probabilidade com cada uma de suas regras de produção. A probabilidade de uma árvore de processamento gerada a partir de um PCFG é simplesmente a produção das probabilidades individuais das produções usadas para gerá-la.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
Podemos ver a árvore de análise eleitoral para o nosso cabeçalho de notícias. Vamos visualizá-lo para entender melhor a estrutura.
from IPython.display import displaydisplay(result)
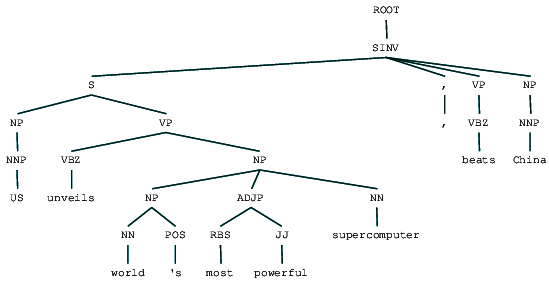
grupo Constituinte analisado manchete de notícia
Podemos ver o aninhadas estrutura hierárquica dos constituintes na saída anterior em comparação ao plano de estrutura superficial de análise. No caso de você estar se perguntando o que SINV significa, ele representa uma sentença declarativa invertida, ou seja, uma em que o sujeito segue o verbo tensado ou modal. Consulte a referência Penn Treebank conforme necessário para procurar outras etiquetas.
Análise de dependências
na análise de dependências, tentamos usar gramáticas baseadas em dependências para analisar e inferir ambas as dependências estrutura e semântica e relações entre tokens em uma sentença. O princípio básico por trás de uma gramática de dependência é que em qualquer sentença na linguagem, todas as palavras, exceto uma, têm alguma relação ou dependência de outras palavras na sentença. A palavra que não tem dependência é chamada de raiz da sentença. O verbo é tomado como a raiz da sentença na maioria dos casos. Todas as outras palavras estão direta ou indiretamente ligadas ao verbo raiz usando links, que são as dependências.
Considerando a nossa frase “A raposa marrom é rápido e ele está pulando sobre o cão preguiçoso”, se quisermos desenhar a dependência sintaxe árvore para isso, teríamos a estrutura
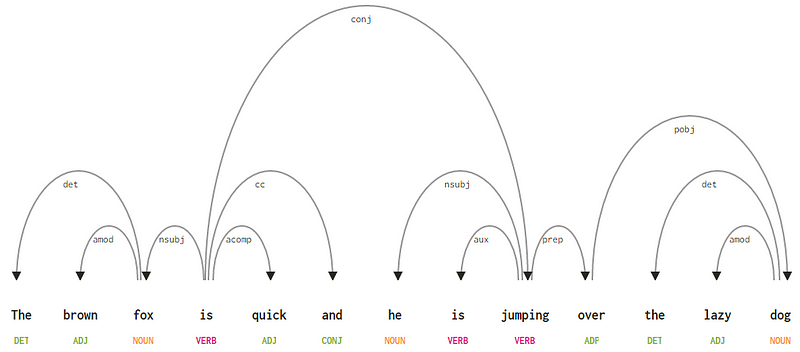
Uma dependência árvore de análise de uma sentença
Estas relações de dependência cada um tem o seu próprio significado e são uma parte de uma lista de universal tipos de dependência. Isto é discutido em um artigo original, Universal Stanford Dependencies: a Cross-Linguistic Typology by De Marneffe et al, 2014). Você pode verificar a lista exaustiva de tipos de dependências e seus significados aqui.
se observarmos algumas destas dependências, não é muito difícil compreendê-las.
- a marca de dependência det é bastante intuitiva-denota a relação determinadora entre uma cabeça nominal e o determinador. Normalmente,a palavra com POS tag DET também terá a relação de dependências de det. Exemplos incluem
fox → theedog → the. - a marca de dependência amod significa modificador adjetivo e significa qualquer adjetivo que modifica o Significado de um substantivo. Exemplos incluem
fox → brownedog → lazy. - A etiqueta de dependência nsubj representa uma entidade que age como um sujeito ou agente em uma cláusula. Exemplos incluem
is → foxejumping → he. - as dependências cc e conj têm mais a ver com ligações relacionadas com palavras conectadas pela coordenação de conjunções . Exemplos incluem
is → andeis → jumping. - A etiqueta de dependência aux indica o verbo auxiliar ou Secundário na cláusula. Exemplo:
jumping → is. - a marca de dependência acomp significa complemento adjetivo e atua como o complemento ou objeto de um verbo na sentença. Exemplo:
is → quick - a marca de dependência prep denota um modificador preposicional, que normalmente modifica o Significado de um substantivo, verbo, adjetivo ou preposição. Normalmente, esta representação é usada para preposições com um substantivo ou complemento de frases substantivas. Exemplo:
jumping → over. - A etiqueta de dependência pobj é usada para denotar o objeto de uma preposição . Esta é geralmente a cabeça de uma frase substantiva seguindo uma preposição na frase. Exemplo:
over → dog.
Spacy tinha dois tipos de parsers de dependência inglês com base em que modelos de linguagem você usa, você pode encontrar mais detalhes aqui. Com base em modelos de linguagem, você pode usar o esquema de dependências Universais ou o esquema de dependências de estilo claro Também disponível no NLP4J agora. Vamos agora alavancar spacy e imprimir as dependências para cada token em nossa manchete de notícias.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
é evidente que o verbo beats é a RAIZ, pois não tem quaisquer outras dependências em relação aos outros tokens. Para saber mais sobre cada anotação, você pode sempre se referir ao esquema de dependência claro. Também podemos visualizar as dependências acima de uma forma melhor.
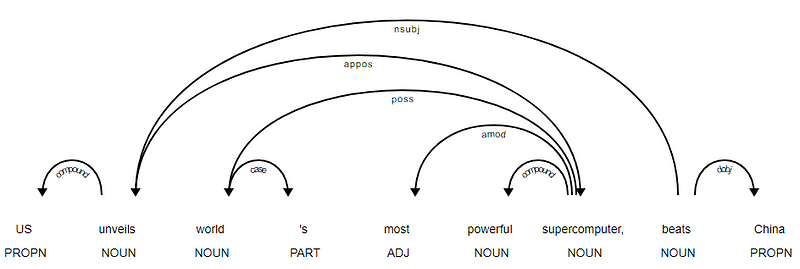
Manchete de Notícia árvore de dependência de SpaCy
Você também pode usar nltk e o StanfordDependencyParser para visualizar e construir a árvore de dependência. Mostramos a árvore de dependências na sua forma crua e anotada como se segue.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
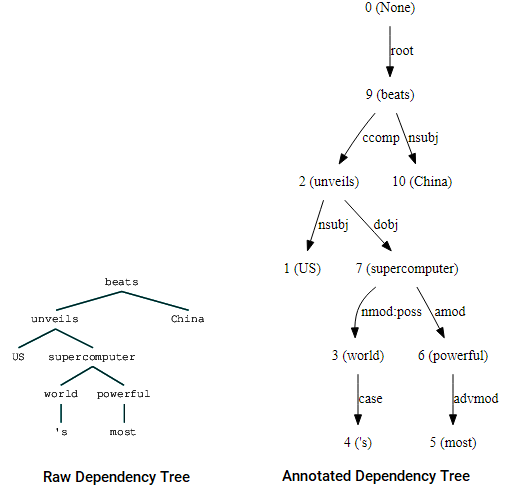
Árvore de Dependência de visualizações usando nltk do Stanford dependência parser
Você pode notar as semelhanças com a árvore que tinha obtido anteriormente. As anotações ajudam a entender o tipo de dependência entre os diferentes tokens.
Bio: Dipanjan Sarkar é um cientista de dados @Intel, um autor, um mentor @Springboard, um escritor, e um viciado em esportes e sitcom.Original. Reposto com permissão.
:
- Robusto Word2Vec Modelos com Gensim & Aplicar Word2Vec Recursos para a Máquina de Tarefas de Aprendizagem
- Humanos Interpretáveis de Aprendizagem de Máquina (Parte 1) — a Necessidade e A Importância do Modelo de Interpretação
- a Implementação de Profundas Métodos de Aprendizagem e Recurso de Engenharia para Dados de Texto: O Skip-grama Modelo